一篇文章是如何被推荐到你眼前的?
-

-
Laoshou 这家伙很懒,还没有设置简介...
0 人点赞了该文章 · 94 浏览

笔者以独特的角度入手,以一篇文章自白的角度讲述了个性化推荐的功能逻辑。
“hi,我是魏无羡,我出生后被送到一个内容库,在这里遇到了很多师兄弟,在一个个黑盒子里,我们身上被打上了N个不同的标签来表明我们的出生地、武功高低、门派风格等等,经过各种试炼检验,有些师兄弟被淘汰了,而我顺利通过了审核进入下发环节。我依靠着一身武艺和好的身世背景,顺利进入尖子班,并在每一阶梯流量中脱颖而出。”
现代人每天都在接触个性化推荐,例如常刷的今日头条、腾讯新闻、抖音等APP。
个性化推荐是特定场景下人和信息更有效率的连接,粗颗粒度理解就是断物识人:左边是内容(断物),右边是用户(识人),中间通过推荐引擎链接两者,追求的是一种高效连接。
在开篇的自白里,高质量下发的核心:识别蓝忘机爱的是魏无羡,并且把魏无羡推给他。
魏无羡:我经历的各种“黑盒子”——内容库
各式各样的黑盒子,都是为了建立人机结合的用户喜爱的高质量内容生成系统,这个实时、高效的系统需要具备哪些特征?
个性化推荐从一个好的内容库开始(第一个黑盒子),目的是为个性化推荐提供精准的内容数据基础,为了创造一个好的内容库,要做哪些工作?
总地来说,是把不能分发或影响体验的内容剔除:
除了部分运营内容外,推出的内容基本来自内容库,内容的质量奠定了个性化推荐的基调。内容库里的内容根据一定规则形成内容候选,机器就开始挑内容进行后续的个性化推荐。
魏无羡奔向的蓝忘机长啥样? ——用户画像
如果你介绍一位朋友,在不同的场合,你也许会有不同的介绍方法。
- 在公司,你会介绍他是一位牛逼的开发大大;
- 在球场,你会介绍他是北大的流川枫;
- 在相亲局,你会介绍他是你“两眼泪汪汪”的同乡。
正是因为事物具有多面性和复杂性的特点,不是一两个词就能概括全的。标签实质上是我们对多维事物的降维理解,抽象出事物更具有表意性、更为显著的特点,所以需要有针对性的投射,以换取信息匹配效率最大化。
用户画像根据用户自然属性、社会属性、阅读习惯和线上行为等信息抽象出的一个标签化的用户模型,常用于用户数据化、个性化推荐、各大业务支撑等等。简单概括为“他是谁”,“他喜欢什么”,为个性化推荐提供丰富而精准的用户画像。
资讯推荐的用户画像一般会分为长期画像和短期画像,前者为离线处理,后者为在线处理。
- 长期画像:是一段时间内的行为+用户自主选择或填写的画像+外部渠道补充的画像等,相对稳定。
- 短期画像:是近几天的行为(例如近7天内点击的100条item),受时间衰减影响较大。
- 综合画像:是以上两者融合。
用户画像的建立更像一门统计学,在处理数据的时候有些关注点:
- 噪音处理:如热门事件会有恶意噪声
- 时间衰减:自建短期模型,新动作提高权重
- 反向惩罚:如曝光未点击进行惩罚
- 归一化:使计算结果具有可比性
- 其他
除了用户在APP的阅读行为,完善用户画像还有哪些路径?
- 外部渠道数据(渠道、唤醒物料、矩阵画像、APPlist等);
- 借助产品设计(如新手引导的兴趣预选);
- 借助运营活动(如支付宝活动收集好友关系)。
画像优化如何评估?
以下指标可供参考:
- 画像覆盖率、人均画像个数;
- 画像准确率:离线人工评估->在线abtest(点击率、时长等指标)。
关于用户画像,还有一点需要了解:不是有了用户画像,便能驱动和提高业务,而是为了驱动和提高业务,才需要用户画像。
蓝忘机还记得魏三岁的好吗?——NLP
蓝忘机已有画像,魏无羡的标签怎么打?也就是机器怎么做?
资讯推荐常见的标签有:分类(CATEGORY)、兴趣点(POI)、关键词(TAG)、主题(TOPIC),颗粒度由小到大:KEYWORD<TAG<POI<TOPIC<CATEGORY。
KEYWORD
TAG
POI
TOPIC
CATEGORY
过往标签推荐较多,现在更多尝试向量化(embedding)推荐,即把特征表征为多维向量,可通过距离衡量语义相关性,YouTube的视频推荐率先实践。
给想了解深度学习(Deep Learning)的产品汪推荐《Deep Learning with Python》[美]弗朗素瓦·肖莱 著,阅读第一章即可(毕竟是一本开发教程书),详见下一篇推送。
通过所有特征标注,魏无羡随千军万马过独木桥 ——召回
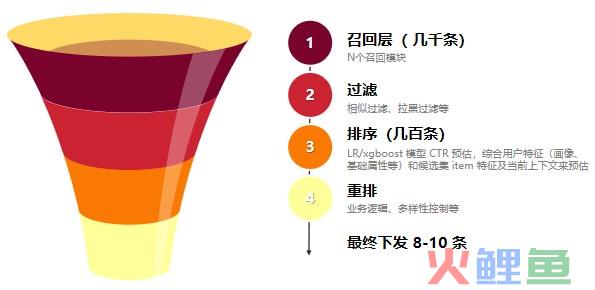
打上标签的内容一起涌来,机器怎么挑?在召回环节,通过索引,几十个召回模块一共召回几千条内容,各召回模块的召回条数有限制,例如本地召回限制最多召回30条内容,召回的内容会根据一定条件(例如CTR、篇均时长、互动指标等)排序后截断,所有召回模块召回的内容汇总到一块,成为一个初步的候选集。
这些召回模块都有他自己存在的理由,例如根据地理位置的召回、根据分类兴趣的召回、根据关键词的召回、根据热议度的召回等等,都是产品经理或开发的想法的一种尝试,大致可分为四类:
1. 兴趣
- 基于内容及用户模型进行推荐;
- 基于订阅收藏等互动行为进行推荐。
2. 协同
- 基于内容:内容的协同
- 基于用户:用户的协同
- 基于用户:内容的协同
3. 热门
- 流量热门推荐:用户行为表现热门的内容;
- 事件热门推荐:最近发生的热搜事件。
4. 本地
- 本地内容推荐;
- 地域内容推荐。
产品汪基于业务需求,在召回模块的探索有:增减召回模块、召回模块逻辑/效果优化、调整召回条数配额。
此类abtest除了关注整体指标外,还需要关注对召回模块的影响:

召回过后会有一个小的过滤环节,主要是一些拉黑过滤,重复过滤等等,把一些不能推或影响体验的内容过滤掉。此环节的过滤和索引前内容候选的过滤不同,前者是具有普适性的过滤(例如低点击过滤、过期过滤等),后者和用户的行为、属性有关。
尖子生魏无羡重新加持,开始 CTR PK 环节——排序
排序环节关注三个词:模型、特征和权重。
所以CTR工程师的工作就是选择模型、采样数据优化、增删特征和调参,字少事大的又一典型。
奔向蓝忘机之前,魏无羡还要过一道人工坎——重排
重排环节主要处理一些业务规则。例如视频推荐占比不超过60%、第2个位置固定出运营内容、相同兴趣点新闻黏连不能超过3条等等,都需要在重排环节处理,这块代码是开发最不忍直视。
规则是最快的上线生效途径,可以用于纠偏、提权等操作。例如,希望增加视频推荐,一开始可在重排环节强出视频(召回环节简单做),保证视频的曝光增多,abtest验证加入视频推荐可行后,再从内容池、召回等环节精细化开发,走一个较长的排期。
总地来说,短期的人工干预应该逐步被长期的机制所替换。过多的“补丁”会严重增加系统的复杂度,降低可理解性。所以更建议优化召回模块优先于排序模块,因为修改召回模块扩充候选集能拥有更多可能性;而主观修改排序模块则极有可能损失公平,降低效率。
Happy Ending
最终下发8-12条,魏无羡奔向屏幕前的蓝忘机,有情人点击阅读,终成眷属。
有的人觉得个性化推荐是“APP更懂我”,但其实个性化推荐的过程不仅具有个体进化意义,还具有群体评估意义,就拿正文页末的“喜欢”、“不喜欢”按钮来说:
以上是智能推荐系统的整体概念,其中的去重、相似推荐、本地推荐、新文章冷启动、相关视频推荐等等,每一模块都可以是独立业务,精细化做起来都是满满的工作量,学无止境。
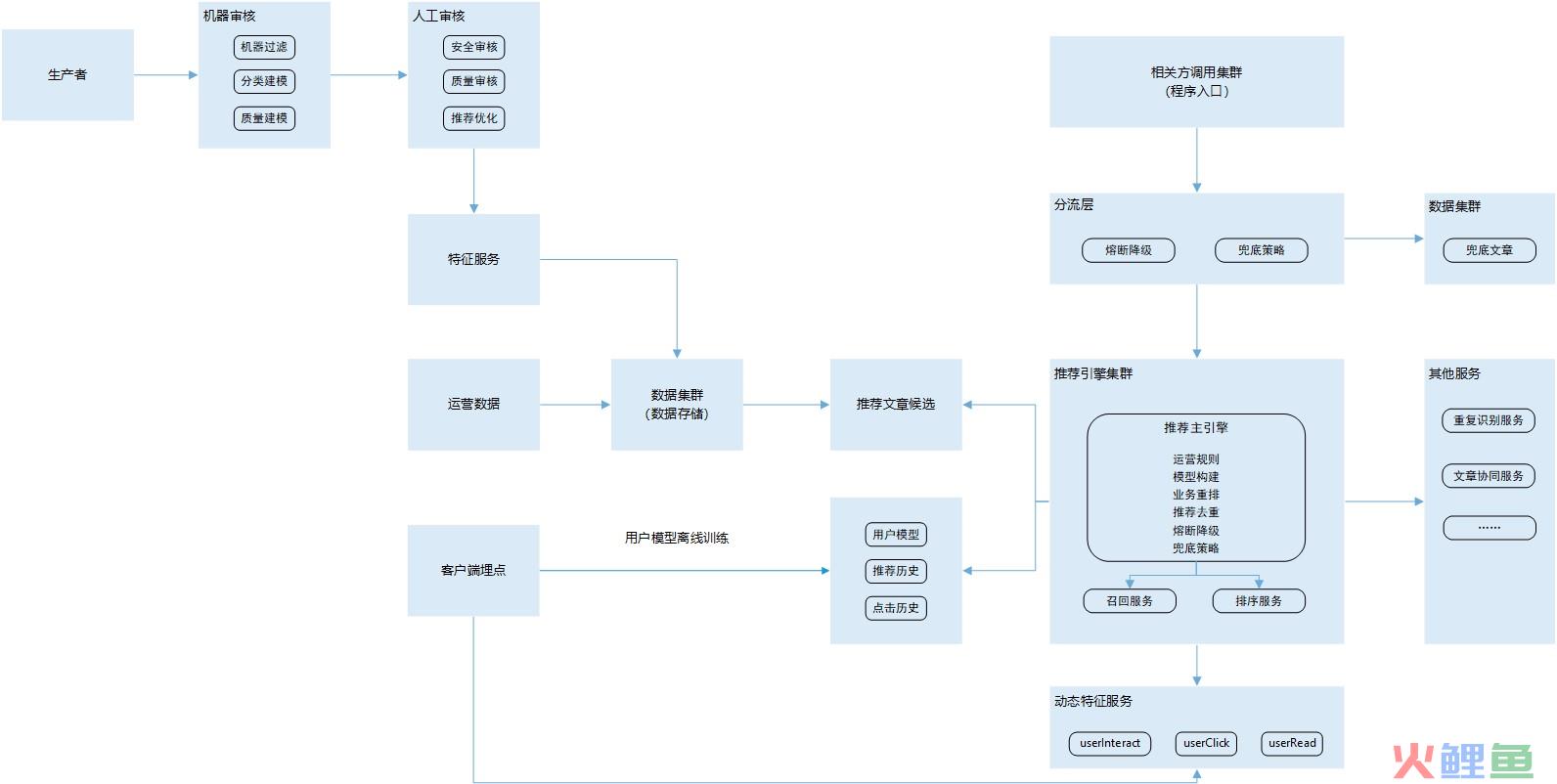
(推荐系统示例)
结语
引用闫泽华在《内容算法》里写的:
个性化的好:在既定的指标体系下,借助技术手段不断追求更好的数据表现,是生意。
好的个性化:在不改变用户目的的前提下,借助技术手段达成用户效率和体验提升,是理想。
本文由 @张小喵Miu 授权发布于运营派,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。