增长乏力?那是你还没真正懂“数据驱动增长”!
-

-
flydragon5 这家伙很懒,还没有设置简介...
0 人点赞了该文章 · 86 浏览
对互联网人来说,掌握数据分析能力能为日常工作提供大量支持,不过大多数人仍处于认知阶段。那为了提前发现问题,确保增长,该如何设计增长实验?本文就此展开了梳理讨论,从五个方面进行了分析,对数据分析感兴趣的童鞋不要错过哦。
之前分享过:做增长,是数据分析师最好的立功方式,今天直接来个例子,看看怎么通过数据设计增长实验。
话不多说,整!
问题场景:某包含多系列产品的快消品公司,希望推出一款全新饮料(2个SKU)以带动整体销售金额。该款为全新推出,缺少经验,因此计划在今年先行实验,观察效果后大面积推广。
问:该如何设计增长实验,以提前发现问题,确保增长?
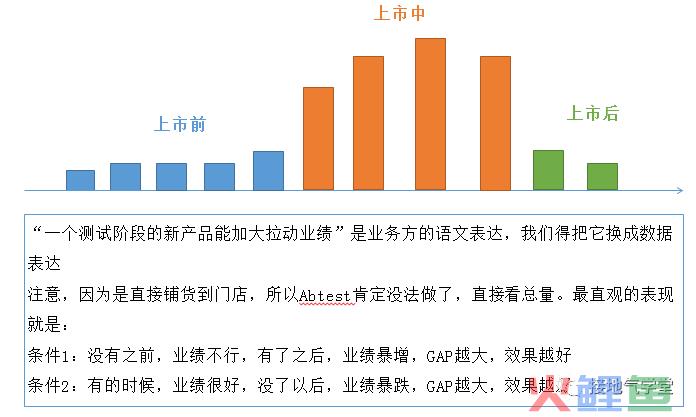
一、虚假的数据增长
很多新人同学举手,表示这题我会:
1、对接头条、腾讯、阿里大数据获取全部信息
2、建立用户到店-货架-选择-加入购物篮-结账转化漏斗
3、进行ABtest,进店用户自动打码分流进行AAAB对比
4、建立用户画像精准识别目标用户性别,年龄,收入,爱好
5、建立人工智能大数据模型精准预测自然销量
现实问题是:没数据。
因为不是自有渠道,所以只能拿到进货数,其他的数据不要想了,不存在的,一条都没有。倒是门店有没有铺货,可以靠巡店督导定期上门检查。
那么,该怎么办呢?
二、最基础的增长模型
最简单的想法:上新品是为了拉动销量,所以上新之后,得比上新之前渠道订货得多。于是最简单的模型就出来了(如下图):
那么,看起来实验设计也很简单了:
1、找几个店
2、铺货
3、观察铺货以后销量
4、搞掂
是不是真的搞掂了呢?
三、考虑增长基础
第一个问题:找店是随机找,还是有目标找?
很有可能有的店天生就卖得好,有的店天生卖得差。如果事先不对店过往订货情况进行分析,就很有可能高估/低估增长能力。
特别要注意专职店是否存在,这类型门店如果数量过多,可能会影响整体判断(如下图):
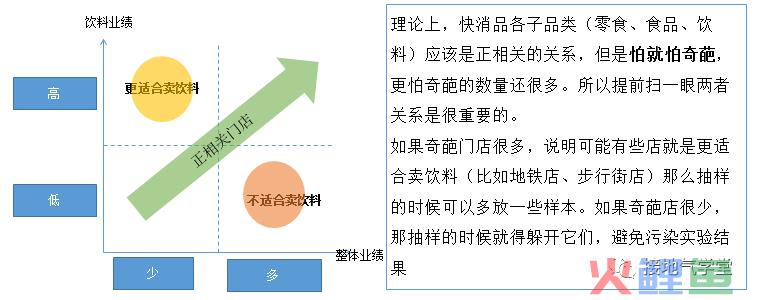
在前期选择试点样本店的时候,提前做好筛选,考虑:
1、门店位置:社区店/CBD店/步行街店
2、门店业绩:整体业绩好/中/差
3、品类业绩:饮料类好/中/差
4、门店时间:新店/老店
这些数据是可以获取到的,数据1在督导的巡店表里有记录,数据2,3,4在订货单里有记录,所以完全可获得。
需要做的是提前对数据进行分析,做好分层和打标签的工作。
这么多维度交叉起来,引发一个新问题:到底要选多少店做试点。
统计学会告诉你单群体最小样本30,最好384,这样95%置信度下抽样误差5%——但是这些和眼前的问题工作没多大关系。
因为眼前的问题是:
第一:需要以店为单位抽,有可能所有门店加起来都不够这么多。
第二:测试的是新产品,且测试周期可能很长,意味着货源可能不够。
第三:测试的是新上架产品,需要业务方一个店一个点铺货,得考虑工作量。
所以,设计样本数的时候,首先对单店在测试周期内销量有个预计,保证肯定有货,这样才能真正测出来:是否达预期。
定下门店总量以后,再按以上考虑维度往里塞样本。最后出来的结果,保证每个分类尽可能都有样本就行。
如果事先有一级、二级、三级门店的分类,则轻松很多。
因为一二三级分类,很有可能已经综合考虑了销售能力,门店规模等等因素。但在使用之前得注意几个问题:
a. 过往的一二三级分类,是否目前还准?
别出现3级>2级>1级的情况,那事后分析就很尴尬了。
b. 一二三级是否考虑类型?
避免一级门店全是同一类门店(比如都是CBD店)这样事后评估,会发现严重缺其他门店样本。
c. 一二三级是否和饮料销售有关系?
注意,题目企业是个全系列企业,很有可能一二三级是按整体业绩分类的,对应到饮料类,又会出现3级>2级>1级的极端情况。
只要不存在以上问题,那1、2、3级分类就直接用吧。
考虑增长基础,不但让设计更丰满,而且能极大方便事后的评估。避免诸如以下这些尴尬的问题:
1、为啥测试效果不好,因为找的都是很差的店
2、为啥分析不出推广潜力,因为找的都是同一类的店
3、为啥1级门店反而卖的不好,因为丫天生就卖得不好
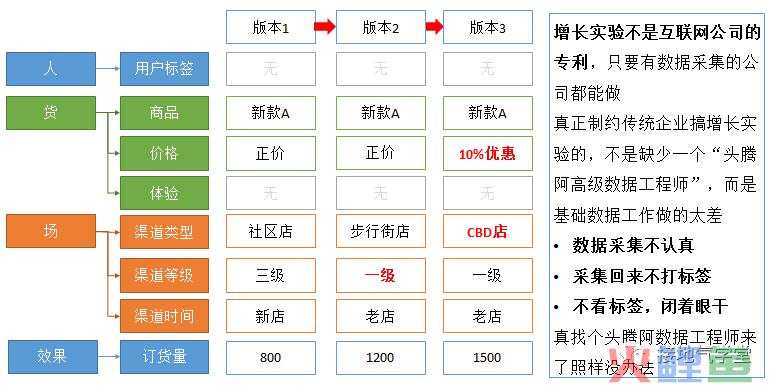
并且在事后分析的时候,能对各类型门店标签下情况进行深入的分析,具体到每一类店铺标签的效果。
这样迭代实验的时候,也有更清晰的方向,落地的时候,思路也更多(如下图)。
那么,考虑到这一步够了吗?
四、考虑增长周期
第二步:考虑什么时间测,测多久
一般商品都有自己的销售周期,饮料类的周期更特殊,可能集中在夏季爆发,也有可能受各地气候的影响,也有可能受天气短期影响。
因此,在设计测试周期的时候,需要先梳理相似价位、相似类型、相似目标群体对应的饮料的走势,这样才能有个全局判断(如下图)。
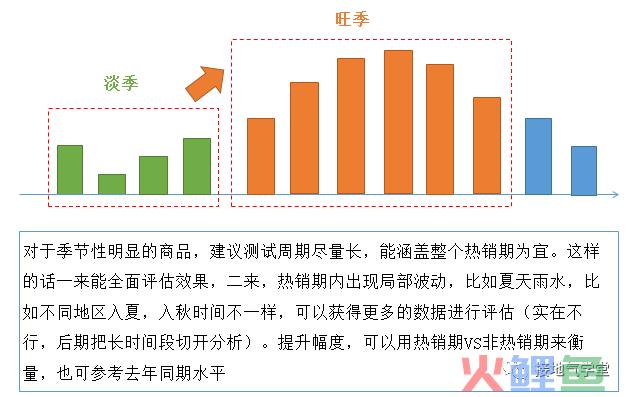
有了全局判断后,可以设一个比较长的观察周期,以尽可能多覆盖各种场景。这样在事后评估分析的时候,也能对各种情况进行分析(如下图)。
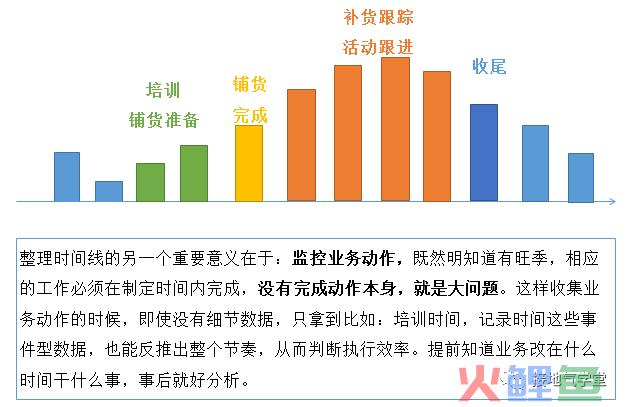
五、考虑增长落地
第三步:考虑业务落地动作
一款新产品上市,宣传、铺货、促销三件套往往是一起往上招呼。这些落地动作才是最终决定测试成果的因素。而这些动作,都依赖各地分公司/办事处的执行,执行力至关重要。
这里有个很深刻的问题:一但测试效果不好……
1、到底是产品本身没需求?
2、还是业务自己没做好?
3、还是数据分析师算错了?
监控了业务执行过程,你才有资格说:业务做得好/不好。没有监控业务执行过程,人家随时都能说:数据分析没算出来。
“现在不都人工智能大数据了吗,一定是我们的数据分析师太蠢了,招个头腾阿的数据分析师肯定能算清楚”——这锅已经为你准备好了,所以一定要掌握清楚。
待掌握的信息包括:
(1)、铺货启动时间
(2)、铺货完成时间
(3)、补充订货时间
有了这些信息,可以结合订货数据做更多分析:
(1)、有没有拖了很久不启动的
(2)、有没有启动了推进很慢的
(3)、有没有不分规模闭着眼睛铺的
(4)、有没有缺货了不去补的
当然,后期核查要跟上,且核查的时候,可以增加几个关键维度检查,比如:
(1)、大夏天的把货铺在货架而不是塞冰柜的
(2)、大卖场不做堆头只做货架的
(3)、有促销物资不往门店进的
这些核查数据同样得从督导手里收回来,同数据一起分析,才更容易看到结果。
这样,在解释结果的时候,自然更有底气:凡是没有执行的到位的,一概不许甩锅给产品/数据,自己没做好的自己反省去。这样也更有利于找到真正问题答案。
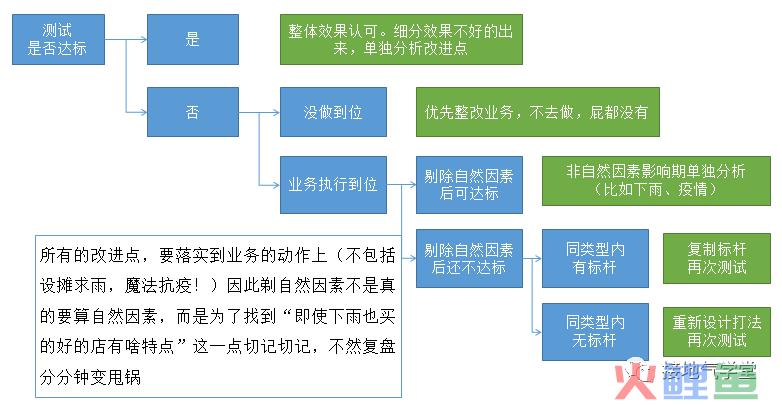
六、小 结
2020年的数据分析领域最大问题,就是:学习过程书本化,脱离实际。
教数据分析的书、老师、课程,为了让算法、统计原理、用户画像、漏斗模型、ABtest发挥作用,就专门挑一些字段丰富,清洗干净的数据集,让算法跑起来。
新人们把工作当读书,跑几个数据集就欣欣然自以为得已得已。
两下相交,导致的结果就是新人们遇到实际问题的时候:不是幻想头腾阿有灵丹妙药,就是急着搬书找答案,要么就是跑到各个群问:“有没有互联网饮料行业的大佬,急,在线等,可付费!”。唯独丧失了具体问题、具体分析的能力。
破除迷信,脚踏实地,认真研究业务流程,设计合理的方法,才是解决问题之道。
数据简单有数据简单的搞法,数据丰富有数据丰富的搞法,把简单的数据通过业务流程改进变得丰富,这三者合并才是一个合格的数据分析师该有的能力。
-END-