听乌森聊强化学习的那些事
-

-
月落西山 这家伙很懒,还没有设置简介...
0 人点赞了该文章 · 124 浏览

作者:莲石东路@乌森
心之所向,无界成长。从底层架构到应用实战,聊聊炼数成金背后的故事。
持续更新数据治理、数据科学、数据可视化、空间计算系列文章。
01 聊聊强化学习
前几天的一则新闻非常有意思。说的是2021年的美洲杯帆船赛上,新西兰酋长队利用强化学习测试水翼设计,他们称之为“AI水手”。”AI水手”在模拟器里学习如何应对风速和风向,学习调整14种不同的风帆和控制船只,经过不断的试错迭代,只用了八周时间就从一个什么都不懂的小白成长到战胜人类水手的水平。
有了”经验丰富”的”AI水手”的帮助,新西兰酋长队迭代设计的速度提升了十倍,得以用指数级速度测试更多船体设计并实现了性能优势,卫冕帆船赛的冠军。
这画面是不是很眼熟,没错,就跟阿尔法狗战胜人类顶级围起棋手那回一样,计算机再次用算力优势在一个领域里超越了人类。强化学习证明了自己在游戏以外领域的价值,帮助人们提升了设计工业产品的速度。
强化学习其实不是个新鲜概念了,只不过过去是被深度学习领域的CV、NLP等热门技术掩盖,现在重新被关注了而已。
那么,它具体是干什么的?简而言之,就是”自学成才”。
还是以Alpha Go举例。早期采用监督学习的 Alpha Go,需要输入大量人类棋手的下法、对弈棋局等数据,不断学习下法,也就是说,它是在“模仿”人类。但无论怎么模仿,它终究还是难以真正超越人类。到了采取了强化学习的Alpha Go Zero 的版本,它就不再对着人类的玩法照猫画虎了。了解到基本的规则以及最终要达到的目标后,就开始“随便下”,如果下赢了,就会得到奖励,然后指导下一步的决策;如果输了,就会有惩罚。在这种尝试——反馈——学习的过程中,完成自我进化。
对比于监督学习,强化学习的优势在于:无需在前期就输入大量数据,可以自我迭代完成学习的过程。对于许多场景来说,我们并没有太多可以参照的数据,而且有些小的变动都有可能会导致过去的经验没法直接套用,监督式的机器学习算法,学无可学。
正因为强化学习更接近于人类的思维模式,也难怪强化学习之父Richard Sutton说:” 我相信,从某种意义上讲,强化学习是人工智能的未来。”
学会下围棋只是强化学习开始,在产业界落地才是AI技术真正价值的所在。
好了,闲话不多说,下面来介绍一些强化学习的入门知识。
02 强化学习的基本概念
强化学习是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益。其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。在维基百科对强化学习的定义为:受到行为心理学的启发,强化学习主要关注智能体如何在环境中采取不同的行动,以最大限度地提高累积奖励。
就本质来说,强化学习是要解决做决策的问题,也就是自动决策问题,且可以连续做决策。
03 强化学习的组成元素
(1)四大元素
强化学习包含四个元素:智能体(agent),环境,行动/动作,奖励。
下面给出强化学习四大元素的定义:
智能体:强化学习的本体,作为学习者或者决策者。
环境:强化学习智能体以外的一切,主要由状态集组成。状态表示环境的数据。状态集是环境中所有可能的状态。
行动/动作:智能体可以做出的动作。动作集是智能体可以做出的所有动作。
奖励:智能体在执行一个动作后,获得的正/负奖励信号。奖励集是智能体可以获得所有反馈信息,正/负奖励信号亦可称作正/负反馈信号。
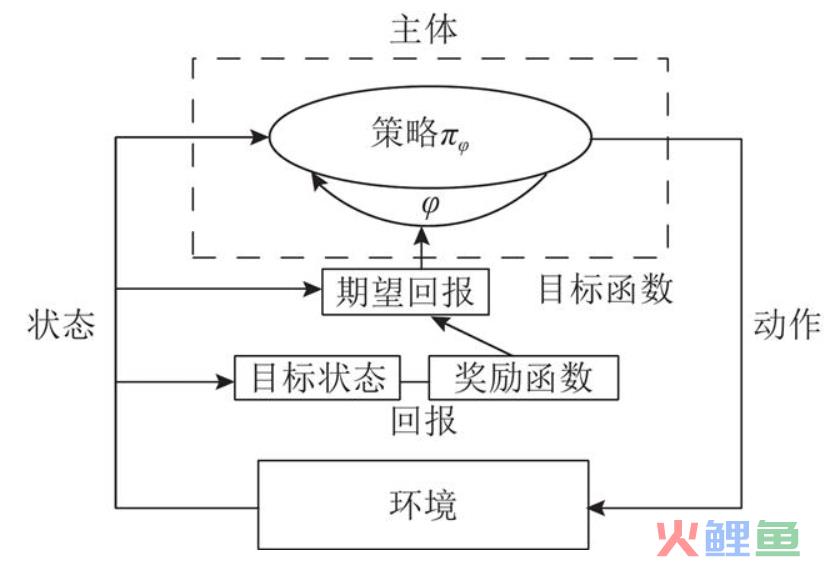
(2)策略与目标
强化学习是从环境状态到动作的映射学习,该映射关系称为策略。通俗地说,智能体选择动作的思考过程即为策略。
智能体自动寻找在连续时间序列里的最优策略,而最优策略通常指最大化长期累积奖励。
可见,强化学习实际上是智能体在与环境进行交互的过程中,学会最佳决策序列。
04 强化学习的分类
强化学习通常分为两种,一种是无模型的,另一种是基于模型的。
(1)无模型强化学习
无模型强化学习直接为参与者生成策略,所有的环境知识都嵌入到这个策略中。
① 策略梯度算法
策略梯度算法修改代理的策略以跟踪那些为其带来更高奖励的操作。这使这些算法符合策略,因此它们只能从算法内采取的操作中学习。
用于连接主义强化学习的简单统计梯度跟踪算法--1992年:提出了政策梯度的概念,提出了系统地增加产生高回报的行为的可能性的核心思想。
② 基于价值的算法
基于价值的算法会根据给定状态的感知价值来修改代理策略。这使得这些算法脱离策略,因为代理可以通过从任何策略中读取奖励函数来更新其内部状态结构。
Q学习--1992年:Q学习是现代强化学习中基于价值的经典方法,其中代理存储每个动作状态对的感知值,然后通知策略动作。
深度Q网络(DQN)--2015年:深度Q学习仅应用神经网络来模拟Q函数的每个动作和状态,这可以节省大量的计算资源,并有可能扩展到连续的时间动作空间。
③ Actor-Critic算法
行为者批判算法将基于策略和基于价值的方法结合在一起--通过对价值(critic)和行为(actor)使用单独的网络近似值。这两个网络相互配合,使彼此规范化并有望获得更稳定的结果。
Actor-Critic算法--2000年:提出了用两个单独的但相互交织的模型来生成控制策略的想法。
信任区域政策优化(TRPO)--2015年:基于actor critic途径,TRPO的作者希望在每个训练迭代中调整策略的变化,他们引入了一个关于KL散度的硬约束,即新策略分布中的信息变化。使用约束而不是惩罚,在实践中允许更大的训练步骤和更快的收敛。
近端政策优化(PPO)--2017年:PPO是对TRPO的改进,相较于之前的TRPO方法更加易于实现。
深度确定性策略梯度(DDPG)--2016年:DDPG将Q学习与策略梯度更新规则结合在一起,允许Q学习应用于许多连续控制环境。
双延迟深度确定性策略梯度(TD3)--2018年:TD3在DDPG的基础上进行了3个主要更改:1)同时学习两个Q函数,采用较低的Bellman估计值以减少方差;2)与Q函数相比,更新策略的频率更低;3)向目标操作添加噪音,以降低攻击性策略。
Soft Actor Critic(SAC)--2018年:为了在机器人实验中使用无模型的RL,作者希望提高样本效率,数据收集的广度和勘探的安全性。他们使用基于熵的RL来控制探索,并使用DDPG样式Q函数逼近进行连续控制。
随着样本复杂度下降和结果上升,许多人对无模型强化学习的应用感到非常兴奋。最近的研究已将这些方法的越来越多的部分用于物理实验,这使广泛使用的机器人的前景更近了一步。
(2)基于模型的强化学习
基于模型的强化学习尝试建立环境知识,并利用这些知识采取明智的措施。
学习控制的概率推断(PILCO)--2011:它提出了一种基于高斯过程(GP)的策略搜索方法。
带有轨迹采样的概率集成(PETS)--2018:PETS将三个部分组合成一个功能算法:
1)由多个随机初始化的神经网络组成的动力学模型(模型集合);
2)基于粒子的传播算法;
3)和简单模型预测控制器。
基于模型的元策略优化(MB-MPO)--2018年:使用元学习来选择集成中哪个动态模型最能优化策略并减少模型偏差。这种元优化允许MBRL在更低的样本中更接近于渐进的无模型性能。
模型集成信任区域策略优化(ME-TRPO)--2018年:ME-TRPO是TRPO在模型集成上的应用,该模型集成被认为是环境的基本事实。对无模型版本的一个细微的添加是策略训练的停止条件,只有在策略迭代时,一定比例的模型不再看到改进时才会停止。
近年来,基于模型的强化学习有很多令人兴奋的应用,例如四轴飞行器和步行机器人。
-END-