用Python完成Excel的基本工作
-

-
ming312 这家伙很懒,还没有设置简介...
0 人点赞了该文章 · 67 浏览
因为对Python的很多数据分析语句不是很熟练,所以日常在数据清洗分析的时候会优先Excel操作,Excel实在做不了再用Python。这也导致我对Python的用法经历了边用边学,学完就忘的尴尬经历。本文将Excel数据清洗处理的需求和Python的实现一一对应起来,从而让自己也能轻车熟路地用Python做数据清洗以及分析。
01数据获取
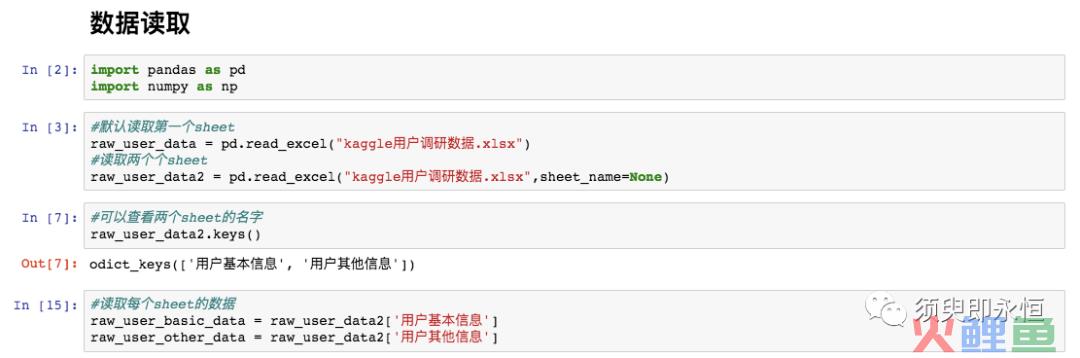
1. 打开Excel文件,读取第一个sheet
import pandas as pd import numpy as nppd.read_excel("XXXX.xlsx")
#如果是多个sheet,默认读取第一个sheet
2. 打开Excel文件,读取多个sheet
DataFrame= pd.read_excel("XXXX.xlsx",sheet_name=None)DataFrame[sheet_name]
#获取sheet_name对应sheet的数据
3. 查询数据有几行几列,有哪些字段
读入数据后,一般会先看下数据有多大,有哪些数据。
DataFrame.shape
#输出这个表格有行数和列数DataFrame.columns #查询表格的列名
4. 查看数据的样例
DataFrame.head() #查看数据的前五行DataFrame.sample(n, replace=False, radom_state =1)
#不放回地随机抽样n行
02数据预处理
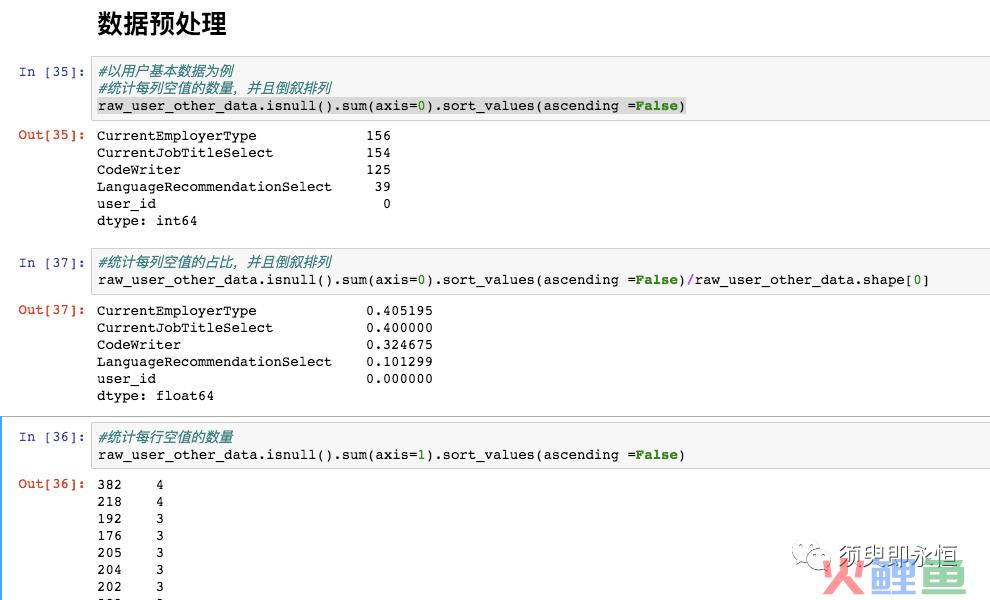
1. 统计下各行各列是否有空值,及空值占比
DataFrame.isnull().sum(axis=0)
#统计每列空值数量
DataFrame.isnull().sum(axis=1)
#统计每行空值数量
2. 删除空值行或者空值列
DataFrame[~DataFrame[col].isnull()]
#删除col列为空的行
DataFrame.dropna(axis=0)
#删除有空值的行,使用参数
axis=0DataFrame.dropna(axis=1)
#删除有空值的列,使用参数
axis=1DataFrame.dropna(how='all',axis=0)
#删除所有值都为空值的行
DataFrame.dropna(how='all',axis=1)
#删除所有值都为空值的列
DataFrame.dropna(subset=[col1,col2])
#删除 col1或者col2列有空值的行
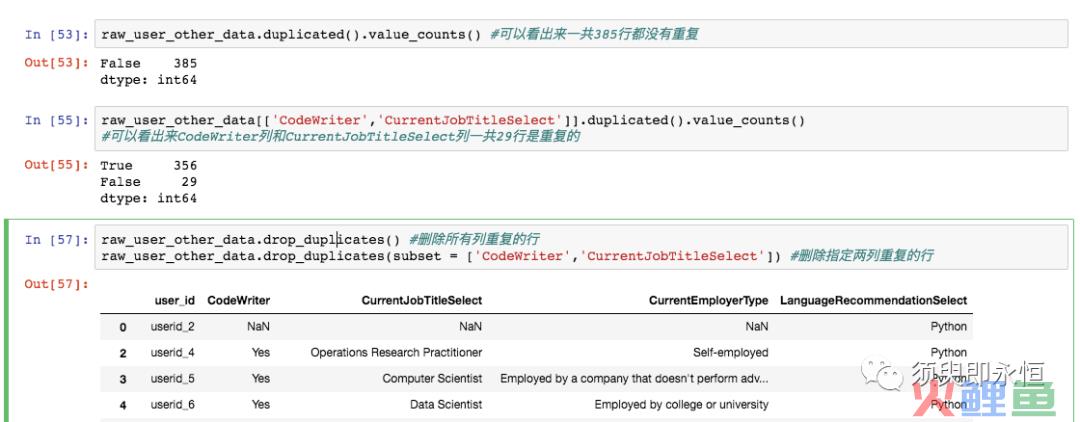
3. 统计是否存在重复数据
DataFrame.duplicated().value_counts()
#统计所有列重复的行数
DataFrame[[col1,col2]].duplicated().value_counts()
#统计指定列有重复的行数
DataFrame.drop_duplicates()
#删除所有列重复的行
DataFrame.drop_duplicates(subset = [col1,col2])
#删除指定两列重复的行
4. 按某字段排序
DataFrame.sort_values(by=col1,ascending=False)
#按col1列升序排列
DataFrame.sort_values(by=[col1,col2],ascending=(True,False))
#按col1列升序,col2列降序
5. 对某数值列调整数据格式
Excel中我们经常需要将数值设置成百分百或者保留两位小数等。现在看看Python怎么做:
'{:.2%}'.format(x)
#转换为两位小数的百分百
round(x,2)
#转化为小数,保留2位小数
03数据选择
数据处理最基本的需求就是筛选出指定行列。Python基本的筛选方式有三种:
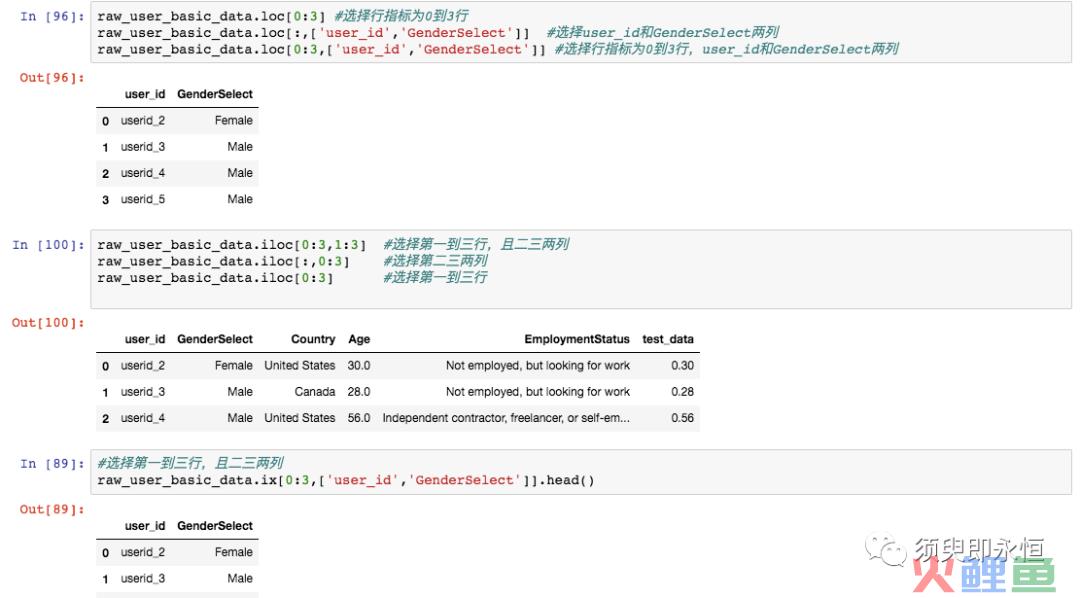
1、DataFrame.loc #根据行的指标和列的列名来选择
2、DataFrame.iloc #根据行列的序列来选,如第2行、第4列
3、DataFrame.ix #上面两种方法的混合,即可用行列名,也可用序列
具体用法可看下面的示例:
1. 筛选出满足某种条件的数据
某列等于某值的行
DataFrame.loc[DataFrame[col]=='F']
# 选出col列等于F的行
DataFrame.loc[DataFrame[col].isin(['E', 'F'])
# 选出col列等于E或者F的行
某列包含某个字段的行
DataFrame.loc[DataFrame[col].str.contains(X)] # 选出col列含有X字符串的行04数据操作运算
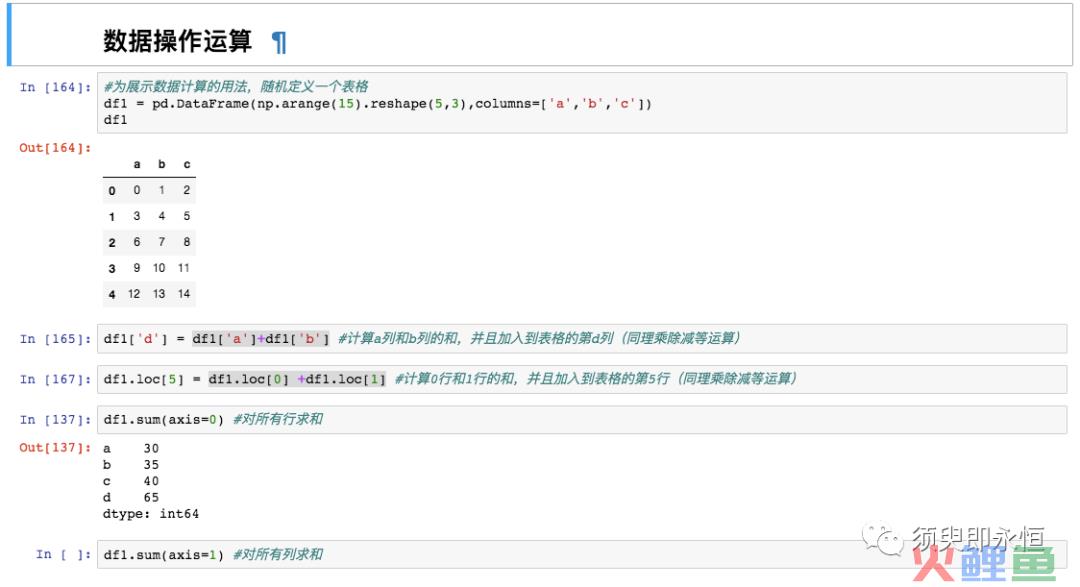
1. 多列数值列做函数计算
Excel常用的场景之一就是:对不同行或不同列做加减乘除计算等;这个非常简单只需拿出对应的行或列计算即可。
df1['a']+df1['b']
#a列和b列相加,同理可换其他运算
df1.loc[0] +df1.loc[1]
#0行和1行相加,同理可换其他运算
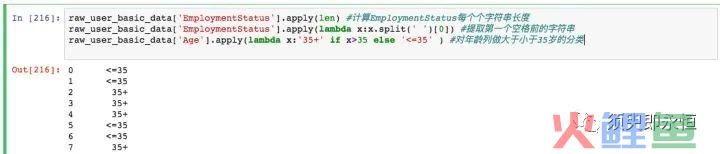
2. 某数值列做函数变换
还有一个场景是,我们需要对某列做函数变换,如提取出某部分字符串,计算字符串长度,字符串倒序等等。这种情况,需要用到apply函数,
DataFrame[col].apply(func,axis=0) #把func函数作用到col列这里的func可以用python已有的函数,也可以用lambda自定义。
DataFrame[col].apply(lambda x:x.func) #用lambda自定义函数作用于col列
05数据分组/数据透视表
在Excel里数据透视表是非常有用且常用的一个功能,他可以实现各种分组统计计算。Python里有三种函数,作用和Excel透视表一致。
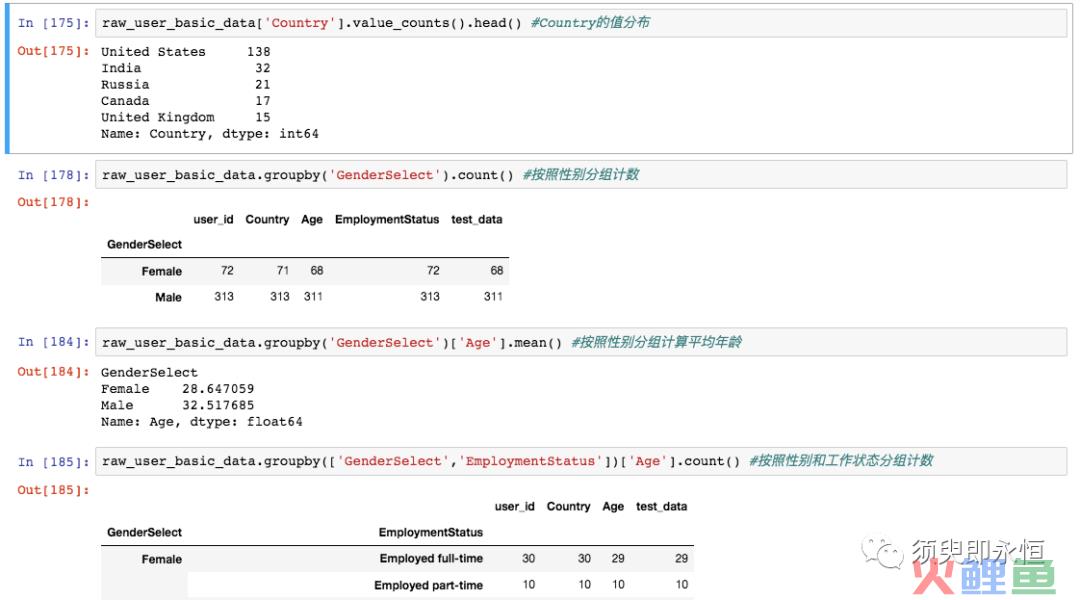
1. 统计某列的数值分布
DataFrame[col].value_counts() #统计col列的数量分布
2. 某列分组后对其他列进行数值运算
DataFrame.groupby(col1)[col2].count()
#对col1列分组,统计col2列的数量
DataFrame.groupby(col1)[col2].mean()
#对col1列分组,统计col2列的均值
DataFrame.groupby(col1)[col2].sum()
#对col1列分组,统计col2列的和
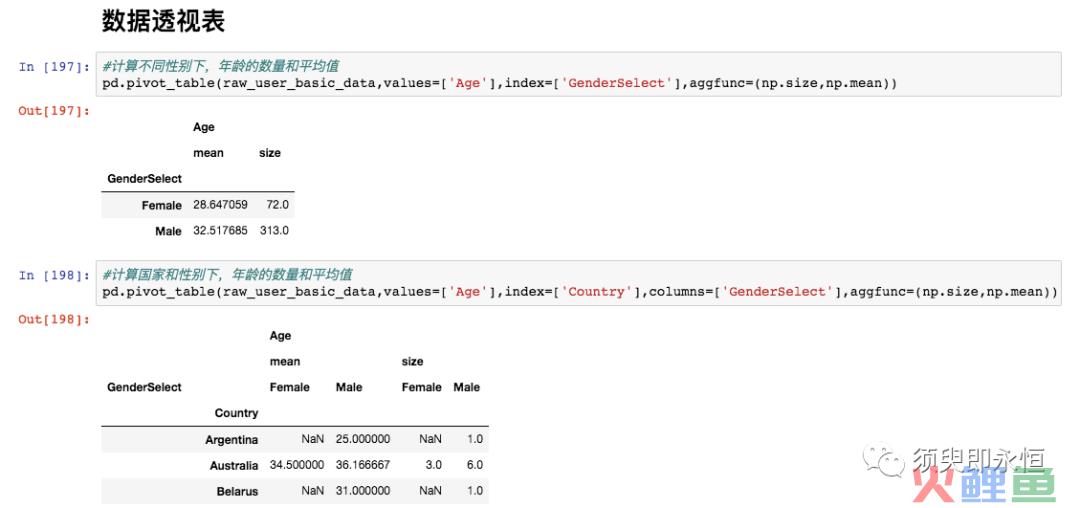
3. 数据透视表的替代
pd.pivot_table(DataFrame,values=[col1],index=[col2], columns=[col3],aggfunc=(np.size,np.mean,np.sum))
这里的index相当于透视表里的行,columns相当于透视表里的列,value表示透视表里计算的值,aggfunc表示作用于value的函数。
06多表拼接
1. 多个表格上下拼接或左右拼接
pd.concat([DataFrame1.DataFrame2],axis=0) #axis为0是上下连接,1是左右连接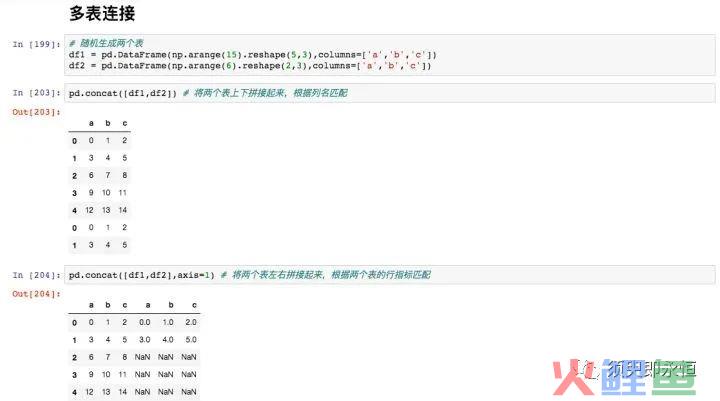
2. VLOOKUP
Python里的merge函数可以实现同样的作用。
当两个表的关联列名一样的时候:
DataFrame1.merge(DataFrame12,on=[col1,col2],how=’left/right/inner/outer’)
当两个表的关联列名不一样的时候:
DataFrame1.merge(DataFrame12,left_on=col1,right_on=col2,how=’left/right/inner/outer’)

07数据导出
数据导出和导入很类似,具体用法如下:
df1.to_csv('XXXX.csv')
#将df1导出为csv文件,文件名为XXXXdf1.to_excel('XXXX.xlsx')
#将df1导出为xlsx文件,文件名为XXXX
以上就是我要分享的内容,想要熟练掌握用Python做数据分析,上述的语句一定要多用多练。如果需要截图中的代码,可私信我「python代码」,感谢大家阅读~
-END-