如何学习业务数据分析?
-

-
chshaowei 这家伙很懒,还没有设置简介...
0 人点赞了该文章 · 74 浏览

01. 科普一下数据分析的应用类型
科研数据分析:
模型非系统化,纯粹学术,实际应用很难落地,要求编程能力极强,模型理论能力极强。一般模型特别多,特别复杂,类似这种
业务数据分析:
非系统化,纯粹业务,无需要求编程能力,模型较为简单,业务数据分析方法的核心就是差异性分析,一般有商务数据分析与运营数据分析,这个后面展开讲。

数据挖掘:
系统化,糅合学术与业务,要求编程能力中等,模型理论能力中底下,核心就是基于机器学习或深度学习模型去做分类与回归。
02. 一般人的首选:业务数据分析
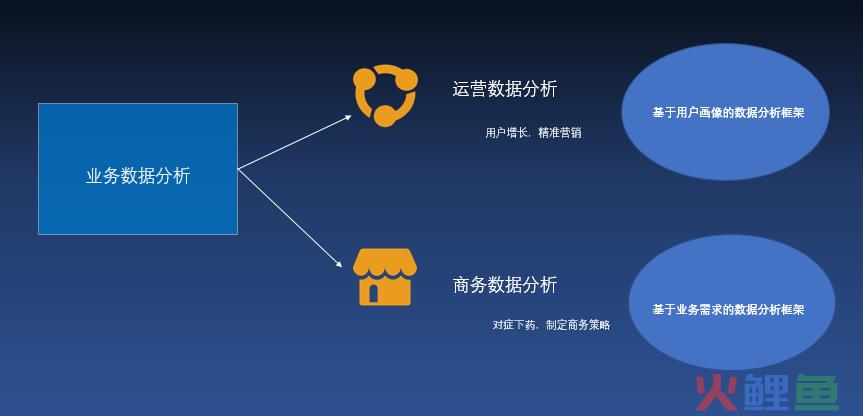
业务数据分析也分为两类,一类是基于标签平台做的运营数据分析(一般只有toc的大公司才有,需要底层建设完善的数据工程),一类是用于进行方案迭代选择的商务数据分析(正常的业务公司)。
商业数据分析
先来说说第二种,商务数据分析,这类应用比较广,其实归根到底,核心就是两个东西:
1. 指标拆解2. 差异性分析(ABTest)连接起来就是对目标进行指标拆解,然后根据指标设计出尽可能多的方案,用ABTest去验证实验前后的差异或者实验组对照组的差异,进行不断调整迭代。
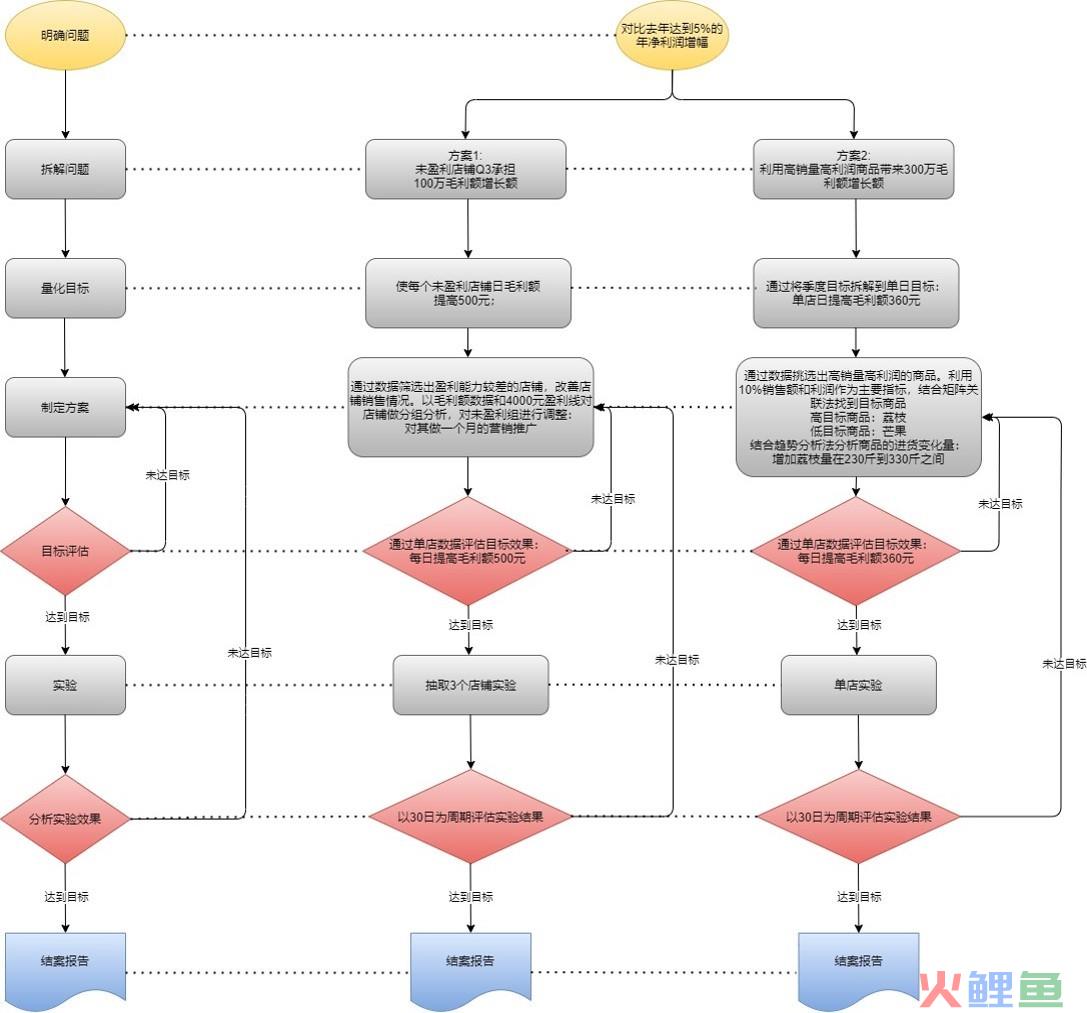
拿上面那个图跟大家解释一下,首先我们拿到一个业务问题,例如,我们这个产品线,今年要比去年达到5%的年净利润增长。
那么我们开始指标拆解,要达到5%的年净利润增长,需要增长400w净利润,有以下的增长点:
· 未盈利的店铺产生利润
· 砍掉高成本低利润的商品,提升低成本高利润的产品
....
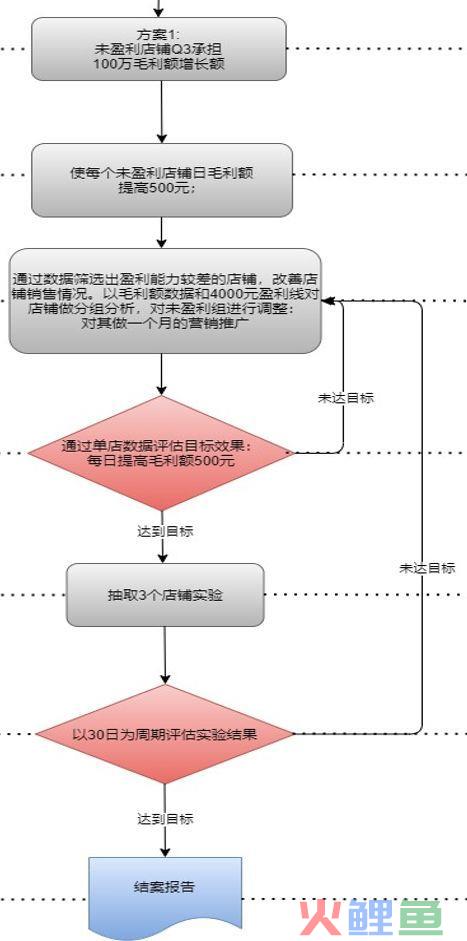
假设只有以上两点,我们结合一些数据推算出来第一个方案需要达成100W净利润增长,第二个方案需要达成300W净利润增长。
那么我们就可以通过下面这种方式设计实验组、对照组,给实验组下达提升日毛利率500元(这个数值是通过100W/天数/未盈利店铺数得到),通过ABTest检验实验组对照组效果,如果没问题的就全面推广(或按比例再划分实验组对照组,直至全面推广),有问题就打回重新设计实验方案。
运营数据分析
我们知道,数据分析的本质就是辅助决策,我们应该尽可能地根据业务问题通过数据分析寻找出解决问题的对策,今天在这里,我将结合数据科学在实际中应用方法,讲解一下真正数据分析技能速成方法与数据分析的业务本质,讲的都是真真在在的干货,有志于真正能掌握业务数据分析技能的小伙伴一定要耐心看完。
直接甩干货,这是一套亲身总结的业务数据分析框架,在用户增长、精准营销等业务数据分析中屡试不爽,看不懂?没关系,下面我将结合对数据科学的理解进行阐述。
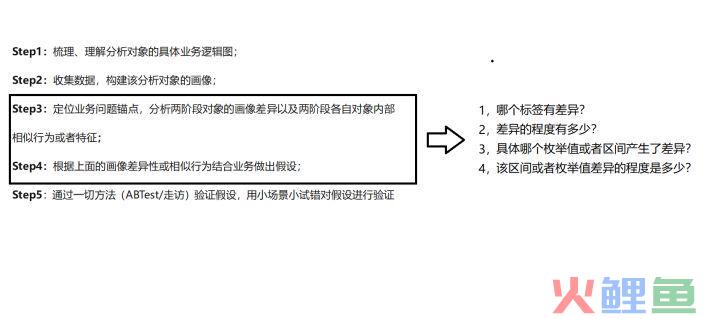
Step1:梳理、理解分析对象的具体业务逻辑图;
首先我们先来看看几个现实中的问题
公司做了场活动,效果不好,用户来了也不下单,数据分析师你怎么分析?
这个月公司的线上产品销售量呈现断崖式下跌,数据分析师你怎么分析?
新出的产品用户反馈不错,投了很多广告,但是销售量却提不上去?
某理财产品曝光度从未降权,但是购买用户却一直在流失,啥原因?
其实我们仔细观察一下,这类问题本质上就是关于留存率、转化率分析,前面我们说到,数据分析的本质就是辅助决策,那么业务数据分析的本质就是通过分析数据的规律,得到针对业务问题行之有效的策略。像这类留存率、转化率的分析,在业务就是作用于精准营销、用户增长方面,只有这类分析,才能为公司带来变现,提升自己的职场竞争力。回归正题,要做数据分析,首先得充分理解业务的逻辑。通过梳理、理解分析对象的具体业务逻辑图就是针对我们遇到的现实业务来梳理业务路径或者业务流转路径图, 要完成这个步骤,业内是有非常多的理论或者构建路径框架的,我总结了一下,其核心主要分位两种:
路径类模型
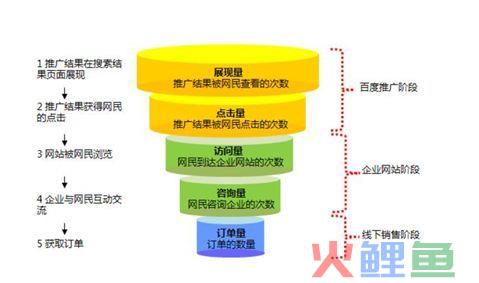
如路径分析,漏斗分析,核心定位是上一个节点与下一个节点存在交叉重叠的关系。例如下面的漏斗分析,它的展现这个节点的用户数是包含点击这个节点的用户数的。
层次类模型
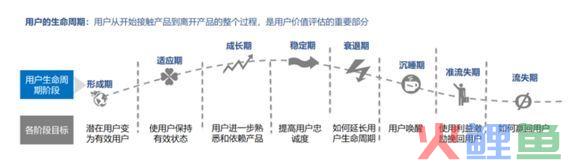
如生命周期模型,RFM模型,核心定位是上一个节点与下一个节点不存在交叉重叠的关系。例如下面的生命周期模型,它的形成期这个节点的用户数是不包含点击这个节点的用户数的,他们之前的上下承接关系仅仅只是层次。
其实业务中最常见的业务梳理方式还是漏斗模型与生命周期模型,特别是生命周期模型,可以这么说,用户运营的本质就是用户生命周期模型的梳理,业务逻辑梳理的质量直接影响第三步的分析,这里以购买理财产品A为例子,利用漏斗分析梳理一下业务逻辑。
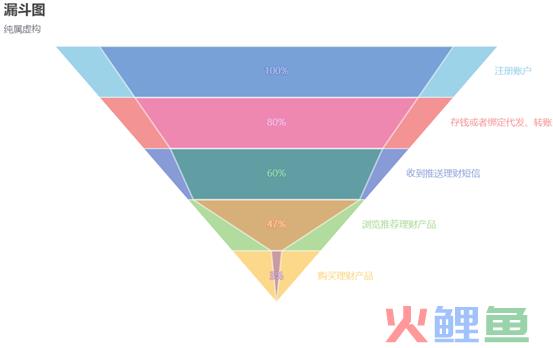
注册开通个人账户→线上存钱或者绑定代发、转账→收到推送理财短信→浏览推荐理财产品→购买理财产品。
Step2:收集数据,构建该分析对象的画像;
第二部核心就是收集数据了,其做法便是构建业务对象的标签体系,例如我们这里的业务是购买理财产品的人,那么其业务对象就是某平台下的银行卡用户。
我们知道近几年来用户画像、标签运营这两个词特别火,现在搞精准营销或者用户增长都一直强调用户画像、标签运营,其实说白了就是构建业务对象的标签体系,然后利用筛选逻辑圈选出来的客群,展现客群标签的区间分布就是用户画像。业内特别热门的用户画像平台有神策,诸葛IO、个推等等,但是其实本质上,他们的核心作用就是管理、存储标签用的,像现在我接触的很多区域性银行他们有些都是直接拿excel来替代做用户画像,所以,其实用户画像平台是不值钱的,他们真正的核心竞争力就是构建用户(业务对象)标签体系的能力,所以很多时候他们这类平台签署的合同都是人力资源服务,而用户画像平台是半卖半送的,像我司在客户现场的精准营销项目组其实工作内容就是帮客户建设用户标签体系,所以搭指标体系可是数据分析师的必备技能,也是数据分析岗位进阶的核心竞争力,业内有流传:不会搭指标体系的的数据分析师都是菜鸟数据分析师。
通常是我是分为基础标签、统计标签、特征标签、模型标签这四个大方向的技术路径来构建标签的,下面是我搭建的银行业客户画像的指标体系方案,由于图太大了,这里就放出来简缩版
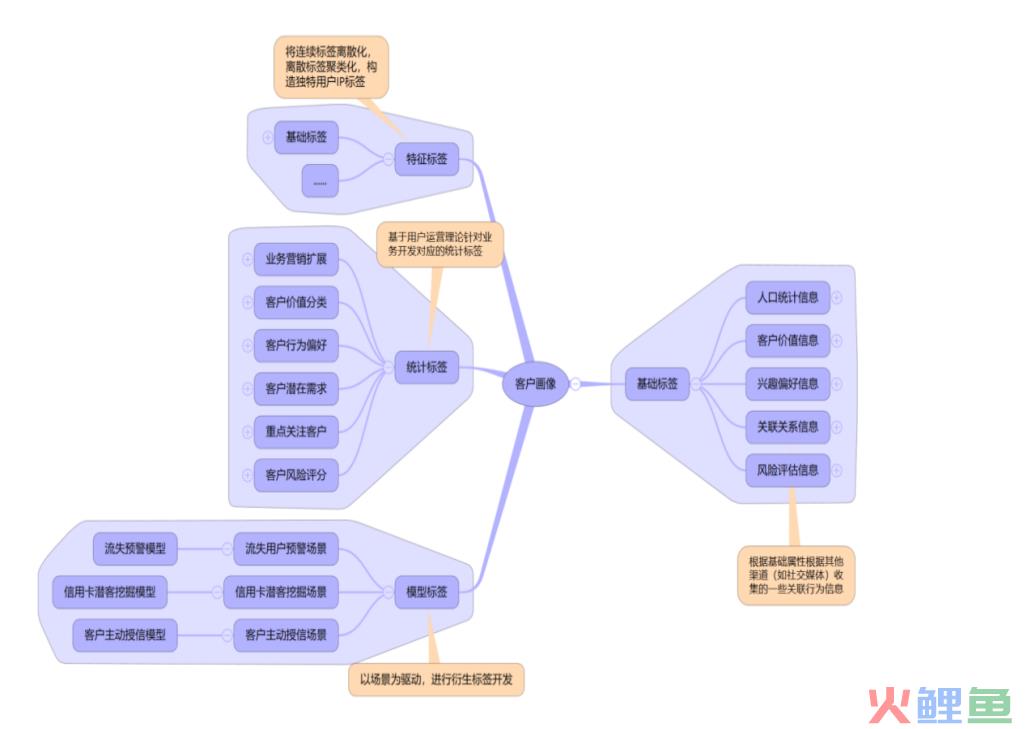
标签体系健全与否是精细化运营的关键,如果标签体系不完整,谈何数据分析,不过很舒服的一点是,很多toC的公司都有用户画像平台,普通业务人员运用这套分析框架能帮你轻松解决很多业务问题。
Step3:定位业务问题锚点,进行数据分析
这里数据分析的核心是分析两阶段对象的画像差异以及两阶段各自对象内部相似行为或者特征。
对于两阶段对象的画像差异,看回之前的漏斗图,我们发现最最后两个阶段的转化率发生了断崖式下跌,购买理财产品A的转化率是3%,但是浏览推荐理财产品的转化率是47%,他们之间只有6.3%的留存率,做精准营销的话这里便有一个业务问题,如何提高浏览推荐理财产品到购买之间的转化率?
这个问题也就回归到用户画像分析,假设浏览推荐理财产品的客群称之为A,购买理财产品的客群称之为B,我把分析点归纳为三个点,分别是:
· 客群(A-B)与客群(B)的用户画像差异分析
· 客群(A-B)的用户画像具有什么相似标签(行为)
· 客群(B)的用户画像具有什么相似标签(行为)PS:一般数据分析师的分析思路主要是以下一些方面
· 从A阶段到B阶段,大部分用户符合什么特征?
· 从A阶段道B阶段,大部分用户是否发生过一些相同行为?
· 从A阶段到B阶段,是否受到不同渠道来源影响?
· 从A阶段到B阶段,是否受到不同学历的影响?
……
所以其实本质上就是上面我所列举的三个点,关于这块,我也是积累心得,以第一点举例,客群(A-B)与客群(B)的用户画像差异分析,我们需要分析的有以下四个方面的内容:
· 哪个标签发生了差异?
(两个客群是性别产生了差异还是收入产生了差异抑或其他?)
· 该标签的总体差异程度是怎样的?
(是性别的差异性大?还是收入?)
· 该标签的用户分布是具体是哪个区间产生了差异
(收入的哪些分布区间产生了差异?)
· 这个区间具体的差异程度是怎样的?
(收入的哪个分布区间产生的差异最大?)对于两阶段各自对象内部相似行为或者特征,这块其实属于可解释机器学习范畴,一般来说我们用一个分类模型就可以解决,例如要研究A客群画像内部相似行为或者特征,我们可以建立一个分类模型,输入可以是标签,输出分为正样本和负样本,其中正样本为A客群画像的用户标识,负样本为从全量客户抽样拿到的非A客群画像用户的用户标识,这也称之为相似人群扩展,这类模型生成的命中概率作为衍生标签还可以,但是来提取内部相似行为或者特征就比较困难了,不过可以利用一些诸如决策树的可解释机器学习来获取其客观的内部相似行为或者特征,这块也称之为构造客群画像的筛选条件。这块我也会新开一个章节讲解如何实现,并且辅以案例(默默求个点赞)。Step4:根据上面的画像差异性或相似行为结合业务做出假设;设计假设主要是从画像差异性入手,用户的相似行为在上一步骤也说了其核心作用于相似用户扩展(扩大投放的用户)。根据我们的业务路径,我们可以选择某两个阶段的客群来挖掘其差异性,解决他们的转化率问题。
举回原例,假设银行app给100w个人推送了理财产品的广告,只有2w个人点击了广告,这块属于分层次模型(step1描述),因为可以分为两个客群:客群A(98W个没有点击广告的人),客群B(2W个点击理财广告的人),通过Step3的分析,假设我们发现有差异的标签为性别,收入,年龄...... ,其差异量化值分为0.98,0.74,0.71.....,我们可以发现客群A男女占比为0.5、0.5,客群B男女占比为0.97,0.03,可以做出假设:男生更容易接受该广告,对该理财产品的更能产生兴趣,运营的策略可以是:向男性银行用户推送该理财策略。Step5:通过一切方法(ABTest/走访)验证假设,用小场景小试错对假设进行验证。
到这个过程通常情况下我们要做的就是把假设进行验证,验证假设的方式通常情况下有两种,一为走访验证,深入一线用户了解用户的需求,验证上文我们提出的假设;二为A/B Test,也就是通过流量分发用于验证假设,这里着重讲一下通俗来讲,ABTest就是比较两个事物好坏的一套方法论。比如某个平台将不同的用户分成不同的组,同时测试不同的方案,通过用户反馈的真实数据来找出哪一个方案更好。这解决的是“多种方案需要拍脑袋确认哪一种更好的问题”。
ABTest的前身是随机对照试验-双盲测试,是「医疗/生物试验将研究对象随机分组,对不同组实施不同的干预,对照起效果」。 双盲测试中病人被随机分成两组,在不知情的情况下分别给予安慰剂和测试用药,经过一段时间的实验后再来比较这两组病人的表现是否具有显著的差异,从而决定测试用药是否真的有效。 2000年谷歌工程师进行了第一次AB Test,试图确定在搜索引擎结果页面上显示的最佳结果数量。后来AB测试不断发展,但基础和基本原则通常保持不变,2011年,谷歌首次测试后11年,谷歌进行了7000多次不同的AB测试。
在用户增长、精准营销等业务数据分析方面,用户画像是最重点突出的,今天讲解的数据分析框架其实最基础的,最核心的也是标签体系(用户画像),这一块才是数据分析师能力的体现如果没有平台上扎实完整的用户画像标签体系,巧妇难为无米之炊,谈何数据驱动决策,进而进行用户增长、精准营销。而这套框架涉及的数据分析模型其实本质上只有差异性分析(假设检验)。综上:业务数据分析通常业界有两种方式的呈现:1,运营数据分析,其核心是构建用户客群画像+客群差异性分析,挖掘运营策略点,这也是正统的业务数据分析师的常规做法
2,商务数据分析,其核心是指标拆解+差异性检验,通过指标拆解形成尽可能多的方案,不断验证迭代方案。这两者都是需要通过灰度发布,设置尽可能多的,实验组对照组或者实验前后的数据差异对比,不断校正产品或者业务迭代方向。