增长模型下的数据体系运用:利用AB测试选择最优功能
-

-
xdd小点点 这家伙很懒,还没有设置简介...
0 人点赞了该文章 · 130 浏览
有四个问题,常常会存在判断上的困难:
这几个问题看起来似乎很简单,然而,实际工作中我们恰恰常在这几点上做出错误决策。下面让我结合实战案例上做一些探讨:
一、AB测试做与不做的具体情况
01
我最初接触AB测试时认为:如果想精确评估一个功能带来的效果,或者衡量对比两个决策因素(或者两个设计、两个选项……)孰优孰劣如何选择,我们可以通过AB测试来实际看一下到底哪个更优。如果采用某个方案已经非常肯定,那么AB测试并没有太大必要。
然而,在实际工作中,我还是看到了非常多的例子,似乎已经非常肯定的事情,AB测试的结果却给出了完全相反的答案。
下面我们看一个实际的例子:
作为综合性电商,如何在显示面积有限的移动端向消费者高效率展示海量商品,是个普遍的难题。
大多数情况下,会根据一级分类设计类目频道,点进去是二级分类频道,再点进去是三级分类频道……这样的结果,需要用户走很深的层级才能看见具体的商品,不但“酒香巷子深”,而且每一次跳转,都会导致流量大比例跳失。所以近年来电商产品普遍尝试的一个趋势是“做浅”。
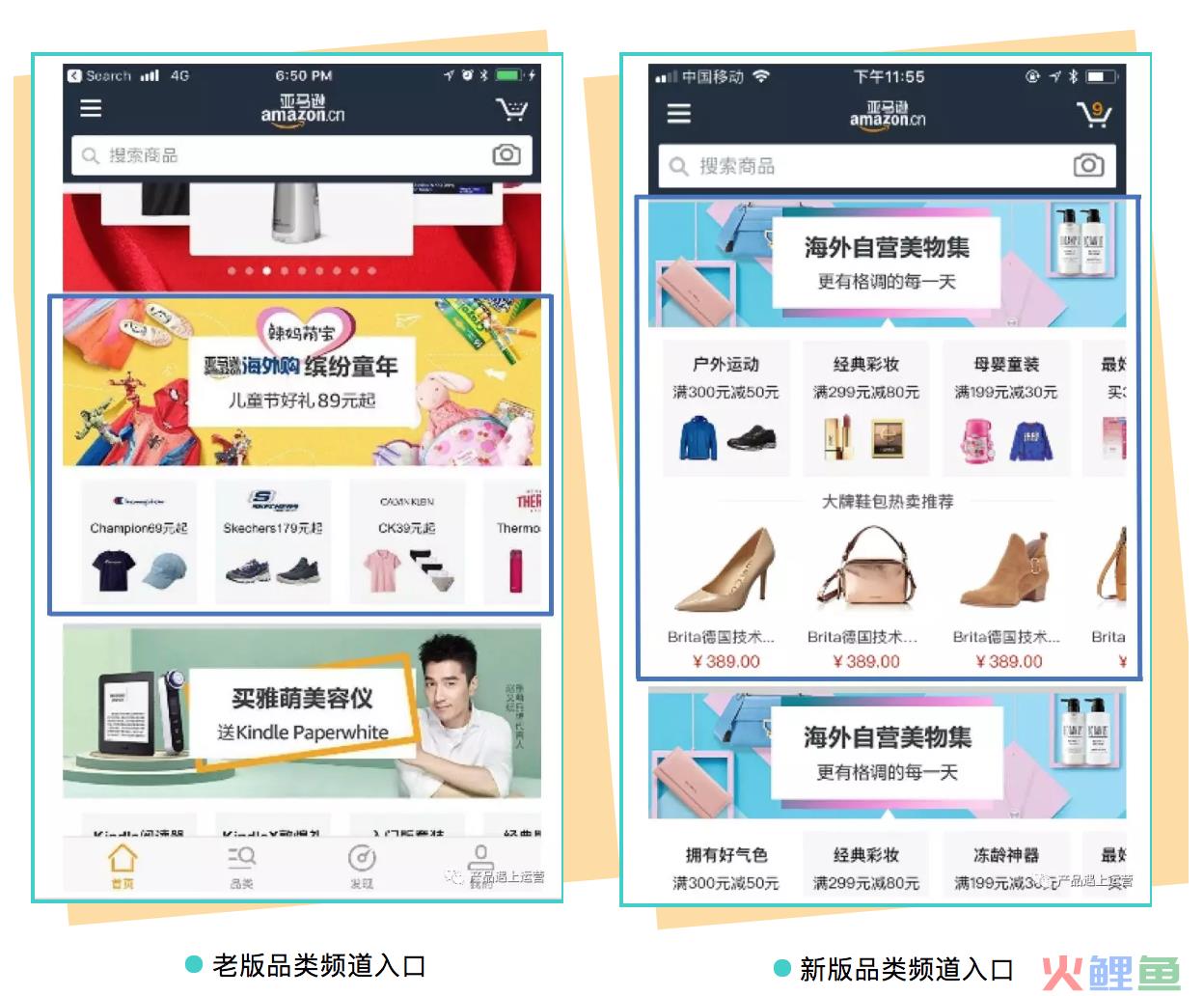
我的团队曾经针对“做浅”做过一个产品改造,在移动端首页的所有类目频道入口直接增加展示单品,以驱动商品曝光,带来更多的商详页浏览量,并通过个性化算法向不同用户推荐不同的活动和单品,以提升转化率。如下图,
首页流量非常大,这样的首页商品曝光+个性化算法选品,我们认为必然能带来商详页流量的明显提升。这个项目如果是我以前负责本地电商产品时,可能会直接安排上线,因为主观预期非常明确。
但是,公司有严格的规定,所有新功能上线都必须要经过Weblab的数据验证。Weblab系统实际上就是一个AB测试的系统,可以输入观察的目标数据项,系统会用一段时间跑出结果,对比有新功能的分组(Treatment Group,简称T)和没有新功能的分组(Control Group,简称C),直接体现目标数据项的增减情况。
经过四周的Weblab测试,数据结果表明,T与C相对比,商详页流量下降了1.32%!!!
这是一个非常意外的结果,产品和BA团队随后立即进行了深入的专题数据分析。

请仔细观察上图,图中每个“Grid”对应的是首页各品类频道入口对商详页的导流数据,在Weblab测试结果中,C的数据为左边橙色柱,T的数据为右边褐色柱。从左到右的每组柱体,代表一个品类频道入口数据,在首页自上而下排序。
从图中我们可以看到:在第二、第三个栏目中(Grid-18,Grid-19),新版本带给商详页的流量确实超越了老版本;但从第四个栏目(Grid-20)开始出现逆转;越深的栏目,贡献给商详页的流量下跌越多;最后计算总体数据,发现老版本的商详页导流能力更强!
产品分析的结论是:新版设计加大了单个品类频道的入口高度,虽然单个品类频道的商详导流能力增强了;但在同样的移动端屏数里,得到曝光的品类频道入口减少了。由于移动端流量随着屏数加深而迅速衰减,导致向用户曝光的品类频道减少,所以全局上商详流量出现了下降。根据这个结果,最后技术团队回滚了这个功能。
这个案例表明,很多主观上看似明显更好的设计,在数据结果上往往出人意料。
因此,如果条件具备的话,所有的新功能迭代都应当进行AB测试,并保持一个合理的时长,来验证预期效果是否达到;尤其要谨慎的是,局部优化,是否在全局上反而得不偿失。
多提一句,也许有产品同学会有疑问,做浅既然是正确的大趋势,那么这个改造为什么失败了?
主要是因为这个方式考虑不够全面,如何正确地“做浅”不在本文范围,后面谈首页和频道页设计的时候我们再深入探讨。这里主要是通过这个案例说明,AB测试常常会否决想当然的推测。
02
进行AB测试时,我们可以多注意以下的问题,避免踩雷。
1. 进行局部AB测试
有时一个新功能至关重要,或者来自领导层的明确要求,不适合在全局只上一半,此时可以考虑进行局部AB测试。
例如:
把A和B分组从50:50调整成90:10(如果流量足够大,甚至可以99:1),然后用那10%的局部测试的结果数据乘以9,来和那90%进行对比,得到结论。
要特别说明的一个误区是——目前很多App是采用灰度发布的模式,慢慢把上线流量从5%提升到100%,这和AB测试是完全不同的策略。
灰度发布的目的是防止未知的错误影响全局,往往先从新疆西藏等小流量地区上线,没问题再扩大到陕西湖南湖北,再没问题则延伸到江浙沪京广深等大流量区域,直至全局上线。每步推进往往只间隔几个小时,最多一天。
而切分部分流量进行AB测试,则需要十分科学、均衡、对等、随机地选取流量,并进行相对更为长期的测试(至少在2~4周),以取得足够的结果样本,提高结果的正确性。
2. 在A和B样本选取的时候,需要对影响因素尽量保持完全对等
例如:
平台的50%流量来自北京,50%流量来自上海,在做对比分组的时候,就不宜把北京作为A分组,把上海作为B分组;因为北京和上海的用户,本身很可能就存在较大的特性差异。
此时最好通过系统随机抽取样本,让各种影响因素在两个样本里均匀分布(例如IP地址最后一位为奇数的为A组,偶数的为B组),通过精心设计的对等性屏蔽所有除被测因素以外的影响因子。
3. 要注意用户对新功能新用法有一个习惯培养过程
例如:
出于不加大首页长度、牺牲下方栏目流量,以及在首页展示更多单品的理由下,我们曾经把秒杀频道在首页展示的单品,由纵向平铺改成横向划动。
当时的全局的AB测试证明这是一个失败的尝试;但时隔一年再次尝试,却取得了相反的结果!
通过分析,我们发现是在做AB测试时,有一批老用户习惯了纵向划动浏览秒杀栏目,不习惯新的交互方式,带来了较差的预期效果,影响了整体数据。然而,对于新用户来说,横划浏览是一个非常高效的方式(注意对横划的引导设计),而老用户随着时间推移也会接受这个新交互方式,此时效果就会体现出来。因此,对于这种高度受使用习惯影响的功能,应当把测试数据集限定在不受固有习惯影响的新用户中,或把测试周期拉到足够长。
4. 战略性的新功能并不适用于AB测试
战略往往专注于未来,但AB测试只反应当前。新业务功能开发出来时,因为某些环境支持因素、用户使用习惯、或配套条件还不完全具备,数据上可能居于劣势。
例如:
在商详页商品图首次使用视频时,可能由于4G网络还不够普及,或者视频素材制作水平还不够规范,导致视频商详图片带来的效果并不理想。但只要相信这是正确的方向,就应该坚持下去。
5. 避免投入的浪费
有时大家可能会有这样的矛盾:一个功能如果没做,是没法做AB测试的;如果做了,那么研发成本都付出了,不上线多可惜。再或者,两个方案不知道哪个好,如果不都开发出来,是无法进行AB测试的;如果都开发了,那么付出了双倍的成本,如何避免投入的浪费?
其实这类问题并没有标准答案。本土互联网公司讲究“试错”,讲究速度,不管对错,做了再说,总有碰对的。而亚马逊这样的国际巨头,则极其严谨,宁可不做,也不做错误的。
以前我在1号店,一个迭代两周就平均上线60多个功能,看到数据变化了,却没有准确地知道谁带来了多少增长或导致了多少下跌,懵懵懂懂往前狂奔。
而亚马逊则十分严谨,每个功能必须做AB测试,达到了确信的提升才允许上线;一个项目上线前会不断被AB测试专家、用户体验专家、技术团队、业务团队所挑战。
狂奔,有时候其实只是在兜圈子;而太谨慎,则可能输了速度,win the battle lose the war。
在我看,没什么对错,要敢赌;但出手前要审慎地推敲,不打无把握的仗,事后则要想办法清晰准确地知道每件事的成败得失。
带着这个思路回看前面的问题,我的观点是:如果做了之后证明效果不佳或者平平,不上更好,止损好过进一步损失,也减少折腾用户。付出的都是沉没成本,不能因为舍不得而影响未来决策(是不是觉得心有点痛,做都做了,不上好可惜~)。
两个方案做哪个好,仔细分析下,做更有信心的,赌一把。如果确实差不多又是重大功能,就都做,根据AB测试取好的,因为A和B的价值差异,可能都超过成本本身。但如果这个功能不太重要,那都别做了,把时间省下来做更重要但事。半重要不重要的,抛个硬币吧。
二、AB测试时,如何判定正确观察指标?
AB测试之前,大家都会选定若干关键指标作为核心被测指标,来对比两个测试集之间的效果差异。这里常见的一个错误是,所选择的判定指标较为片面,不能正确全面体现方案效果,得出错误结论。
下面我们来看一个实际案例:
在中国的电商应用中,大家可能习惯把购物车当做收藏夹,把有可能会购买的商品放进购物车,在最后结算时勾选本次要买的商品进入结算流程,剩下的则继续收藏在购物车里,留在以后下单。真正的收藏夹反而使用较少,或用来收藏店铺或重度复购商品。
某亚的购物车逻辑有所不同。它更类似用户在超市中实际推的购物车;在最后结算时,必须要从购物车中移除所有本次不购买的商品,然后把购物车所有商品一起结算。如果不想直接删除,可以移入收藏夹。
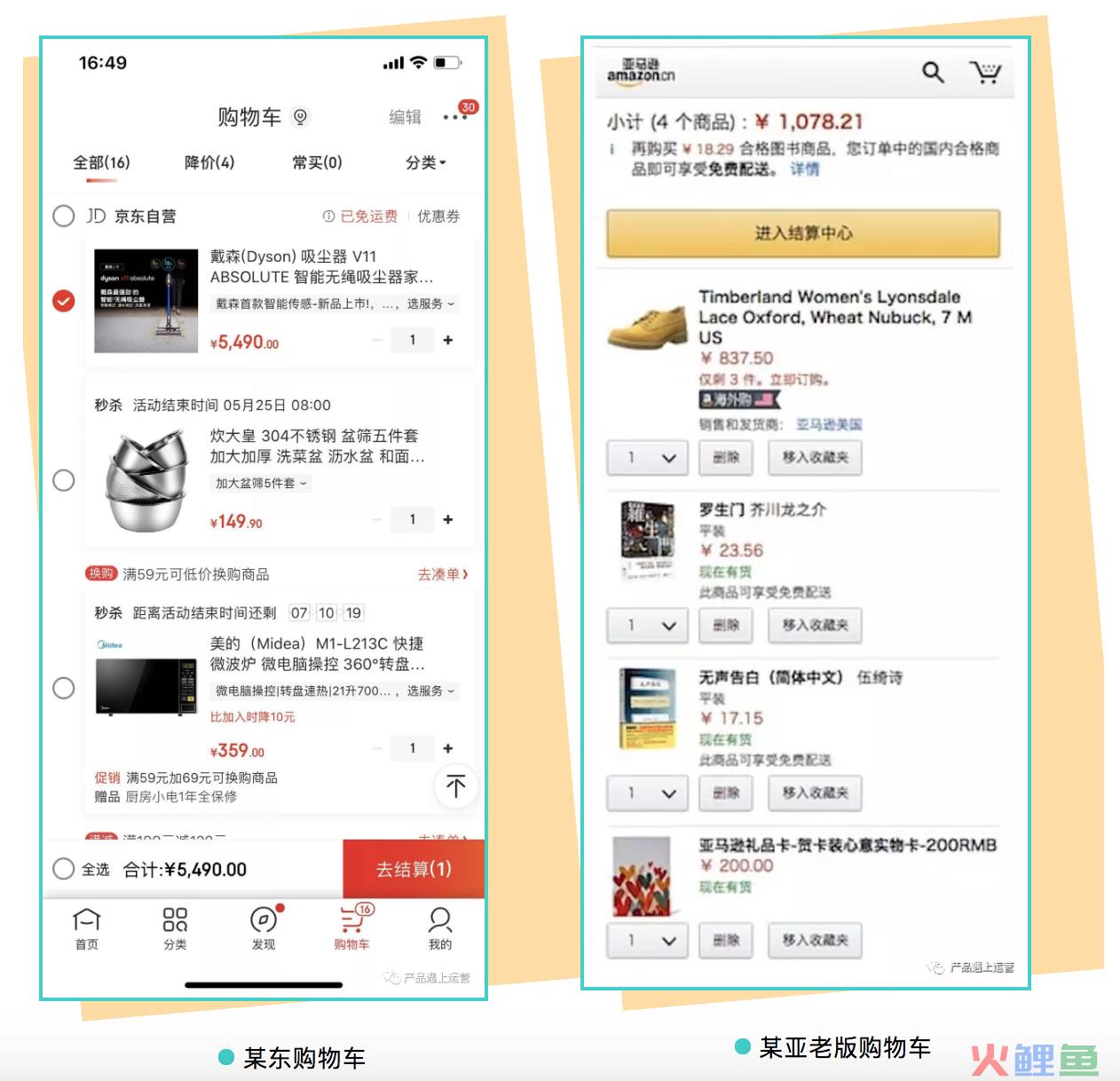
前者在中国用户用得很好,而后者则在全世界用户那里用得很好,除了中国。两者可能没有绝对的好坏之分,都是用户习惯培养的问题,只是两边培养的用户习惯不太一样。
那么问题来了,某亚中国app该怎么办?我看到很多用户反馈,某亚购物车和大家习惯的不一样,会买错东西,很不方便,等等。
这个问题由来已久,两年前某亚购物车团队也曾上线过类似中国购物车的部分结算版本(称为Partial Checkout);但经过AB测试验证,Partial Checkout版本以销售额作为对比指标,在为期一个月的AB测试中输给了原来的版本,因此该版本最终被回滚。
这是一个有些意外的结果,我们做了跟进分析,得到如下结论:
1. 用户习惯尚未形成时,刚接触全部结算版本购物车的新用户,有可能把一些本来没打算当次购买的商品纳入订单,也就是说,一不小心多买了。如果只是简单地以销售额来衡量,全部结算的老版本反而占到了优势。
2. 一不小心多买了的用户,事后发现时有一部分人会选择退货,由此造成了退货率的提升。同时,用户满意度会受到影响。但因为不是所有人都会退货,老版本销售额显得更高。
3. 部分结算版本购物车,用户可以保留不立即结算的商品,因此这些在购物车中保留的商品具有未来潜在的销售机会。而对于全部结算版本购物车,数据表明:大约有40%的用户会把不结算商品移入收藏夹,其余用户则会直接删除。这一定程度地损失了这些商品的后续销售机会。然而,后续销售会有一个时间后置,未来的损失不会在为期一个月的AB测试阶段被捕获。
通过以上分析我们看到,这个购物车的改动直接影响到四个因素:直接销售、未来潜在销售、退货率、用户满意度。
此外,由于操作步骤更加复杂(必须删除不结算商品),导致结算步骤可能有更高的跳失率。在前次的AB测试中,测试指标只考虑了直接销售因素,由此得出了可能比较片面的结论。
不过想要全面衡量上述指标,难点在于:
1. 未来潜在销售无法拉取未来数据,除非做一个历时较长的AB测试,但即使时长覆盖多个用户平均下单周期,也无法准确衡量全部未来销售影响。下篇文章我会介绍一个非常有价值的方法,来计算未来价值。
2. 用户满意度是一个综合性指标,同时受到非常多因素的影响,此外它的获取方式也很不同于AB测试的功能投放,较难直接剥离出来纳入AB测试结果的综合分析。
在综合考量后,产品团队再次推动部分结算版本的购物车,并在新一轮的考量更全面的指标后,该版本赢得了AB测试,获得了0.34%的综合销售提升和0.66%的下单频度提升,最终得以成功上线。
以上案例说明,在进行AB测试时应当根据被测功能的综合价值,对考量指标做一个全面分析,考虑多维度价值以及中长期影响,做出一个更为全面和长远的决策。
在后续的实战中,我们也把观测指标做出了更为复杂的定义,分为核心判定指标,辅助观察指标,以及否决指标。
例如:导购功能做AB测试时,以商详页浏览数作为核心判定指标,以转化率、用户获取能力作为辅助观察指标,以销售额作为否决指标。只要商详页浏览数有明显的增长,或者转化率、用户获取数有较好增长但商详页浏览数不为负,就可以作为上线候选,最后校验销售额;如果销售额下降,就一票否决,否则可以全面上线。
三、如何同时测试多个相互叠加的因素?
有时我们想要同时测试多个因素,或者测试本身受到很多因素的同时影响,比如,我曾有一篇文章想要测试一下“标题党”玩儿法带来的阅读量波动。阅读量虽然与标题强相关,但也与我的发文日期在工作日还是周末、发文时间点是早晨还是傍晚都有较大关系。最终那篇“标题党”文章是在周日早上8点左右发出,最后我观察到有较大的阅读量提升。
那么问题来了,这个提升,到底是因为标题吸引人带来的?还是因为周日大家有闲暇时间阅读带来的?还是因为早上是个黄金时间带来的?
在这个例子里,上述三个主要因素共同构成影响,因此如果想要做最客观的测试,就应该对任何一个因素选两个差异最大的情况,进行排列组合,3^2=8,因此把测试集8等分,做等量的投放,由此可以看到每个因素带来的影响量。
人工做这样的流量切分和差异化投放比较难,最好能够有系统层面的支持,把多个要做AB测试的功能独立叠加上去,并且制定每个AB测试的时间段,让系统在时间范围内自动对流量做随机切分和功能投放,以获取相对准确对结果。
有些大型公司的系统很好地支持多参数AB测试,但如果没有这样的自动测试平台,那么通过人工方式选取流量和投放也是可行的,但一定要垂直正交地做流量拆分,让除被测因素以外的其它因素都互不干扰。
换句话说,在两个被测分支A和B上,除单一的测试因素外,所有其它因素都完全对等。
四、AB测试结果真的正确吗?
假设我们在做一个转化效果的功能测试,当历时四周的AB测试终于完成了,对比两边数据,发现投放了设计一的A分支比投放了设计二的B分支多销售了1%。那么,我们可以结论设计一的转化会更优于设计二吗?
您猜对了,不能!很多原因都会造成AB测试的错误。
上述案例我们很容易作出结论——设计一更好。
但当产品经理深入观察数据时,比如拆分到具体每一天去看数据趋势,也许会发现大部分的日子里,版本二表现更加优异;只是有少数日子,版本一的样本中出现了大订单(偶然事件),极大影响了总体数据,最后造成了版本一胜出。这样我们不难推测,如果除去这类偶然事件,版本二实际上更好。
此类偶然因素本身不可避免,但它会对结果造成致命的影响,导致AB测试的结果出现偏差。消除的方法有多种:
1. 取更大的数据样本,或者把测试运行更长的时间。通过数据结果样本的大幅增加来减少偶然因素带来的影响。
2. 设置置信阈值,除去超出置信阈值的数据。例如,一个生鲜电商平台的订单通常在几十到几百元,那么万元以上的大单,往往十分偶然和蹊跷,或者不出自普通消费者,甚至是刷单结果,应当从结果中除去。
3. 对测试结果数据进行对数处理(取log)。这是一种消除随机结果中的“毛刺”,把结果波动变得平滑,但又可以保留结果的波动特性的有效数学手段。对该方法感兴趣对朋友可以进一步看一下相关数学或者信号处理理论。
除了对上述偶然性的理解和处理,另外有一个因素也是在做AB测试的流量投放测试中必须要慎重考虑的,那就是投放对象和被测因素的相关性。
例如:运营测“排行榜”频道的入口文案效果,如果投放的人群是纯精准型人群(典型行为是,绝大多数浏览的商品是通过搜索到达的),由于这些人群基本不会浏览和使用“排行榜”频道,那测试结果其实都是随机噪声,并没有实际意义。
在亚马逊的系统中有一个非常实用的概念,就是对于每一个AB测试结果,系统都会给出一个置信度数值,称之为P-Value。这个值代表着结果的不确定性。
例如,如果P-Value=0.05,意味着如果系统说A比B好,那么只有5%的情况会出现相反的结果。对于P-Value产生影响的主要是:
虽然大家所使用的平台未必有类似的功能,但带着统计学观点进行AB测试的设计和结果观察,会对透彻理解测试结果和作出正确决策非常有帮助。
最后要说的一点是,数据是用来验证猜想,反映客观事实的。但数据只是工具,也会被人断章取义。我们有时会看到为了让结果看起来很美而做AB测试造假的项目。
例如:某功能对10%的用户有正向结果,对90%的用户有负面影响,于是这10%的用户被刻意选择作为测试范围,然后用测试数据欢呼该功能具有“高价值”(当然也有在测试指标的选取、测试时长定义上玩儿花样)。这背后,也需要职业操守,领导者最好能具备一定的AB测试知识,才不容易被蒙蔽。
到这里,我对AB测试的实战经验分享告一段落。做一个简单总结:
作者:徐霄鹏
微信公众号:产品遇上运营