语音识别基础,总有一天你会用到
-

-
sunnight 这家伙很懒,还没有设置简介...
0 人点赞了该文章 · 126 浏览
本文为PMCAFF专栏作者rui_liu出品
语音交互将会成为新的入口,也是各大公司务必争夺的资源之一,资源是指数据,不是技术,因为技术会开放,而有价值的有标注的数据才是制胜法宝。
所以,pm们需要了解语音识别技术的基础,总有一天你会用到,并且这一天不会太远。
我会从以下几个方面介绍语音识别:
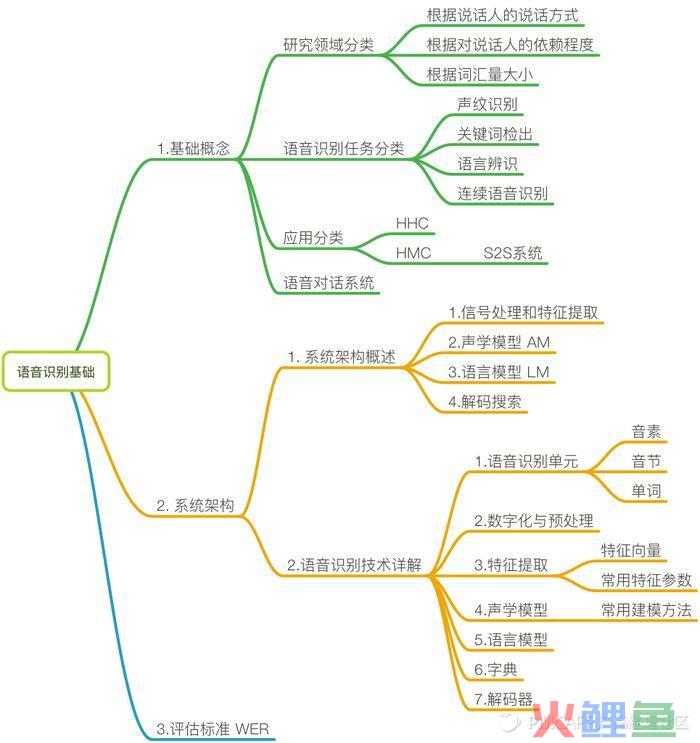
语音识别的基础概念
1
概念
自动语音识别(Automatic Speech Recognition,ASR)技术是一种将人的语音转换为文本的技术。
这项技术被当做是可以使人与人、人与机器更顺畅交流的桥梁,已经在研究领域活跃了50多年。
2
发展
ASR在近几年的流行,与以下几个关键领域的进步有关:
-
摩尔定律持续有效:使得多核处理器、通用计算图形处理器GPGPU、CPU/GPU集群等技术,为训练复杂模型提供了可能,显著降低了ASR系统的错误率。
-
大数据时代:借助互联网和云计算,获得了真实使用场景的大数据训练模型,使得ASR系统更具鲁棒性(健壮性、稳定性)。
-
移动智能时代:移动设备、可穿戴设备、智能家居设备、车载信息娱乐系统,变得越来越流行,语音交互成为新的入口。
3
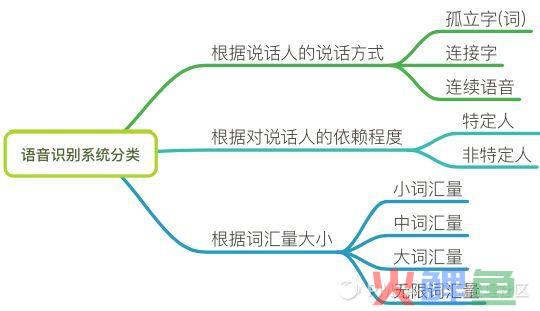
研究领域分类
根据在不同限制条件下的研究任务,产生了不同的研究领域。如图:
4
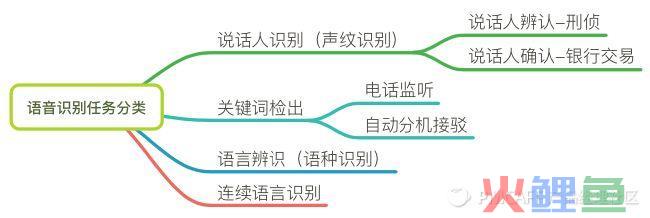
识别任务分类
根据不同任务,语音识别可分为4类:
5
应用
语音交互作为新的入口,主要应用于上图中的两大类:帮助人与人的交流和人与机器的交流。

帮助人与人的交流 HHC:应用场景如,如翻译系统,微信沟通中的语音转文字,语音输入等功能。语音到语音(speech-to-speech,S2S)翻译系统,可以整合到像Skype这样的交流工具中,实现自由的远程交流。S2S组成模块主要是,语音识别–>机器翻译–>文字转语音,可以看到,语音识别是整个流水线中的第一环。
-
帮助人与机器的交流 HMC:应用场景如,语音搜索VS,个人数码助理PDA,游戏,车载信息娱乐系统等。
6
对话系统
要注意的是,我们上面所说的应用场景和系统讨论,都是基于【语音对话系统】的举例。
语音识别技术只是其中关键的一环,想要组建一个完整的语音对话系统,还需要其他技术。
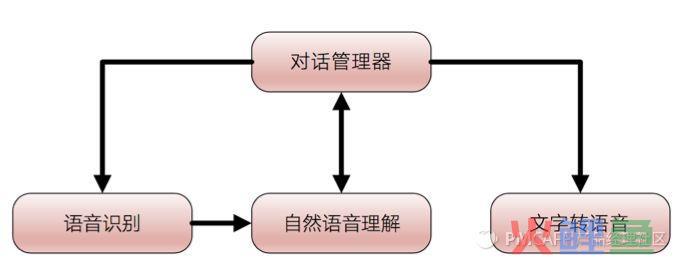
语音对话系统:(包含以下系统的一个或多个)
-
语音识别系统: 语音–>文字
-
语义理解系统:提取用户说话的语音信息
-
文字转语音系统:文字–>语音
-
对话管理系统:1)+ 2)+3)完成实际应用场景的沟通
语音识别系统
语音识别问题,其实是一个模式识别的问题。给你一段声波,机器判别是a还是b。
这个过程有两大块,一个是生成机器能理解的声音向量。第二个是通过模型算法识别这些声音向量,最终给出识别结果。
每一块中间都有很多细小的步骤,我们后面会提到。
1
系统架构概述
下图是语音识别系统的组成结构,主要分4部分:
信号处理和特征提取、声学模型(AM)、语言模型(LM)和解码搜索部分。
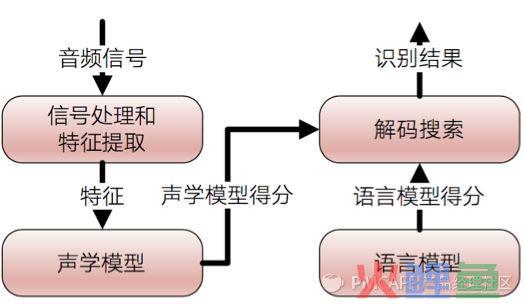
左半部分可以看做是前端,用于处理音频流,从而分隔可能发声的声音片段,并将它们转换成一系列数值。
声学模型就是识别这些数值,给出识别结果。后面我们会详细解释。
右半边看做是后端,是一个专用的搜索引擎,它获取前端产生的输出,在以下三个数据库进行搜索:一个发音模型,一个语言模型,一个词典。
-
【发音模型】表示一种语言的发音声音 ,可通过训练来识别某个特定用户的语音模式和发音环境的特征。
-
【语言模型】表示一种语言的单词如何合并 。
-
【词典】列出该语言的大量单词 ,以及关于每个单词如何发音的信息。
a)信号处理和特征提取:以音频信号为输入,通过消除噪声和信道失真对语音进行增强,将信号从时域转化到频域,并为后面的声学模型提取合适的有代表性的特征向量。
b)声学模型:将声学和发音学的知识进行整合,以特征提取部分生成的特征为输入,并为可变长特征序列生成声学模型分数。
c)语言模型:语言模型估计通过训练语料学习词与词之间的相互关系,来估计假设词序列的可能性,又叫语言模型分数。如果了解领域或任务相关的先验知识,语言模型的分数通常可以估计的更准确。
d)解码搜索:综合声学模型分数与语言模型分数的结果,将总体输出分数最高的词序列当做识别结果。
2
语音识别技术详解
看完上面的架构图,你应该有个大致的印象,知道整个语音识别是怎么回事儿了。下面我们详细说一些重要的过程。
2.1 语音识别单元
我们的语音内容,由基本的语音单元组成。选择要识别的语音单元是语音识别研究的第一步。
就是说,你要识别的结果是以什么为基础单位的?是单词还是元音字母?
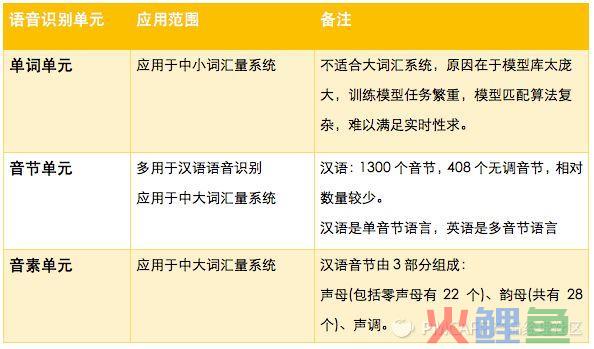
语音识别单元有单词 (句) 、音节和音素三种,具体选择哪一种,根据具体任务来定,如词汇量大小、训练语音数据的多少。
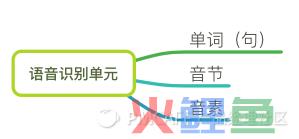
【音素】:在汉语里,最小的语音单位是音素,是从音色的角度分出来的。
-
【音节】:一个音素单独存在或几个音素结合起来,叫做音节。可以从听觉上区分,汉语一般是一字一音节,少数的有两字一音节(如“花儿”)和两音节一字。
2.2 信号的数字化和预处理
接下来就要将收集到的语音转化为一系列的数值,这样机器才可以理解。
a)数字化
声音是作为波的形式传播的。将声波转换成数字包括两个步骤:采样和量化。

为了将声波转换成数字,我们只记录声波在等距点的高度,这被称为采样(sampling)。
采样定理(Nyquist theorem)规定,从间隔的采样中完美重建原始声波——只要我们的采样频率比期望得到的最高频率快至少两倍就行。
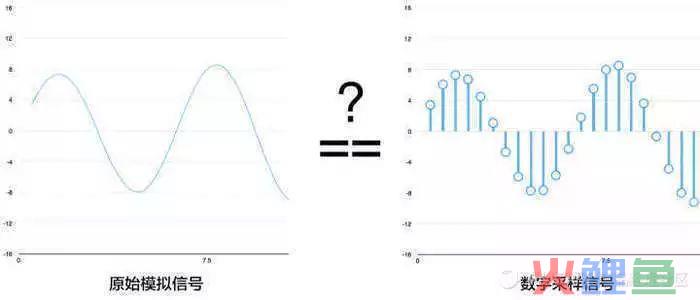
经过采样,我们获取了一系列的数字,这些数字才可以在机器上进行建模或计算。
我们每秒读取数千次,并把声波在该时间点的高度用一个数字记录下来。把每一秒钟所采样的数目称为采样频率或采率,单位为HZ(赫兹)。
「CD 音质」的音频是以 44.1khz(每秒 44100 个读数)进行采样的。但对于语音识别,16khz(每秒 16000 个采样)的采样率就足以覆盖人类语音的频率范围了。
b)采样信号预处理
这里的预处理主要指,分帧处理。
因为语音信号是不平稳的、时长变化的,如下图:
我们把它分隔为一小段一小段(10毫秒-40毫秒)的短语音,我们认为这样的小片段是平稳的,称之为【帧】。
在每个帧上进行信号分析,称为语音的短时分析。
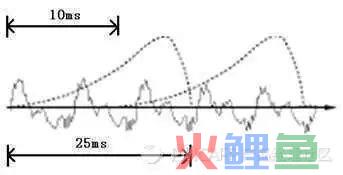
图中,每帧的长度为25毫秒,每两帧之间有25-10=15毫秒的交叠。我们称为帧长25ms、帧移10ms的分帧。
帧移的事情就不详细解释了,它是为了保证语音信息的完整性。感兴趣的同学可以查一下,加窗/窗函数。
那为什么需要平缓的分帧呢?因为我们需要做傅里叶变化,它适用于分析平稳的信号。(想弄明白傅里叶变换的,之后可以参考文章末尾的链接)
人类是根据振动频率判断声音的,而以时间为横轴(时域)的波形图没有振幅描述,我们需要做傅里叶变换,将它变成以频率为横轴(频域)的振幅描述。
2.3 特征提取
特征提取就是从语音波形中提取出能反映语音特征的重要信息,去掉相对无关的信息(如背景噪声),并把这些信息转换为一组离散的参数矢量 。
a)特征提取
如何提取呢?我们经过采样,预处理,将这些数字绘制为简单的折线图,如下所示,我们得到了 20 毫秒内原始声波的大致形状:
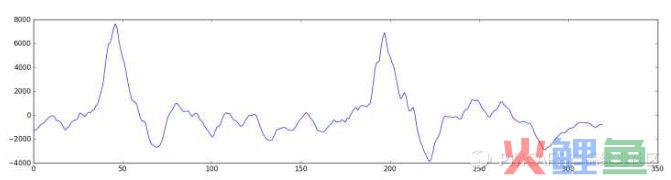
这样的波形图对机器来说没有任何描述信息。这个波形图背后是很多不同频率的波叠加产生的。(准确的讲,它在时域上没有描述能力)
我们希望一段声纹能够给出一个人的特性,比如什么时候高,什么时候低,什么时候频率比较密集,什么时候比较平缓等等。
就是我们上面所说的,用傅里叶变化来完成时域到频域的转换。
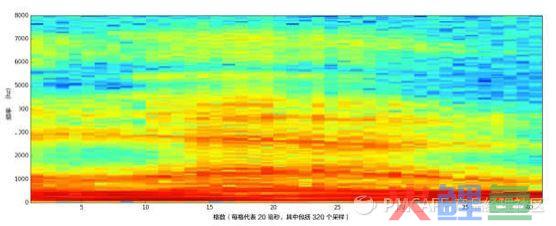
这就需要对每一帧做傅里叶变化,用特征参数MFCC得到每一帧的频谱(这个过程就是特征提取,结果用多维向量表示),最后可以总结为一个频谱图(语谱图)。
如下图所示,是“hello”的频谱图,很酷是吧~
横轴是时间,纵轴是频率。颜色越亮,表示强度越大。
b)常用的特性参数
特性提取时,我们有常用的特征参数作为提取模板,主要有两种:
-
线性预测系数(LPC)
LPC 的基本思想是,当前时刻的信号可以用若干个历史时刻的信号的线性组合来估计。通过使实际语音的采样值和线性预测采样值之间达到均方差最小,即可得到一组线性预测系数。
求解LPC系数可以采用自相关法 (德宾 durbin 法) 、协方差法、格型法等快速算法。
-
倒谱系数
利用同态处理方法,对语音信号求离散傅立叶变换后取对数,再求反变换就可得到倒谱系数。
其中,LPC倒谱(LPCCEP)是建立在LPC谱上的。而梅尔倒谱系数(Mel Frequency Cepstrum Coefficient, MFCC)则是基于MEL谱的。不同于LPC等通过对人的发声机理的研究而得到的声学特征,MFCC 是受人的听觉系统研究成果推动而导出的声学特征。
简单的说,经过梅尔倒谱分析,得到的参数更符合人耳的听觉特性。
c)短语音识别为单词
有了上面的特征提取,每一帧都可以表述为一个多维向量,接下来就是把向量识别为文本。
这里我们需要多介绍一个概念,叫【状态】。
你可以理解为,是比音素更细致的语音单位。通常把一个音素划分成3个状态。
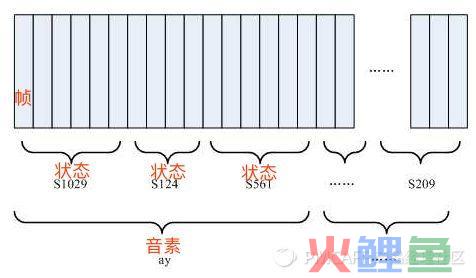
如上图所示,识别过程无非是:
-
把帧识别成状态(难点)。
-
把状态组合成音素。
-
把音素组合成单词。
那每个音素应该对应哪种状态呢?这就需要用到声学模型了。
2.4 声学模型
声学模型是识别系统的底层模型,其目的是提供一种计算语音的特征矢量序列和每个发音模板之间的距离的方法。
也就是说,提取到的语音特性,与某个发音之间的差距越小,越有可能是这个发音。
或者说,某帧对应哪个状态的概率最大,那这帧就属于哪个状态。这个可以用GMM(混合高斯模型,就是一种概率分布)或DNN(深度神经网络)来识别。
但这样识别出来的结果会比较乱,因为一个人讲话的速度不一样,每一帧识别出的结果可能是:….HHH_EE_LL__LLLL__OOO…..,如下图:
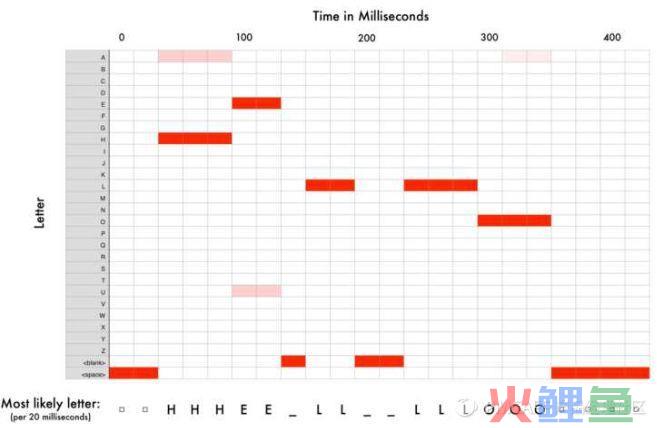
这个问题可以用DTW(动态时间规整)或HMM(隐马尔科夫模型)或CTC(改进的RNN模型)来对齐识别结果,知道单词从哪里开始,从哪里结束,哪些内容是重复的没有必要的。
a)常用的声学建模方法包含以下三种:
-
基于模式匹配的动态时间规整法(DTW);
-
隐马尔可夫模型法(HMM);
-
基于人工神经网络识别法(ANN);
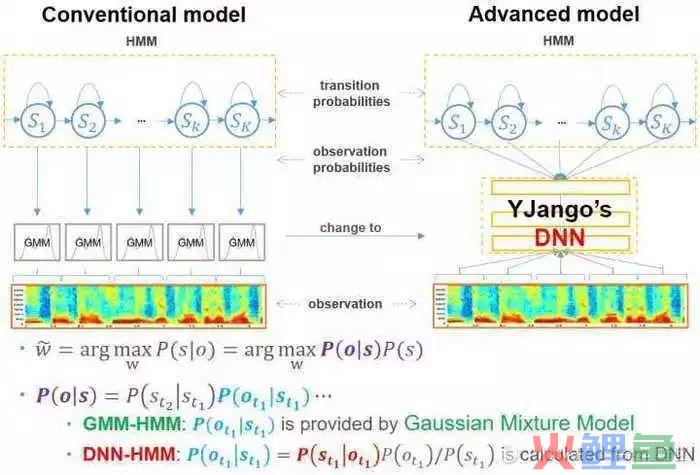
在过去,主流的语音识别系统通常使用梅尔倒谱系数(Mel-Frequency Cepstral Coefficient, MFCC)或者线性感知预测(Perceptual Linear Prediction, PLP)作为特征,使用混合高斯模型-隐马尔科夫模型(GMM-HMM)作为声学模型。
近些年,分层鉴别模型比如DNN,变得可行起来,比如上下文相关的深度神经网络-隐马尔可夫模型(context-dependent DNN-HMM,CD-DNN-HMM)就比传统的GMM-HMM表现要好得多。
如下图,你可以清晰的看到被替换的部分。
b)主要问题:
我们要了解的是,声学模型存在2个问题:
-
特征向量序列的可变长;
每个人说同一个单词的时间长度都不一样,声学模型要能从不同的时间长度的语音信号中识别出是同一个单词。
解决方法就是DTW(动态时间规整)、 HMM(隐马尔可夫模型)。
-
音频信号的丰富变化性;
如说话人的性别,健康状况,紧张程度,说话风格、语速,环境噪音,周围人声,信道扭曲,方言差异,非母语口音等。
c)HMM 声学建模:
对语音识别系统而言,HMM 的输出值通常就是各个帧的声学特征 。 为了降低模型的复杂度,通常 HMM 模型有两个假设前提,一是内部状态的转移只与上一状态有关,一是输出值只与当前状态或当前状态转移有关。除了这两个假设外,HMM 模型还存在着一些理论上的假设,其中之一就是,它假设语音是一个严格的马尔科夫过程 。
2.5 语言模型
如何将识别出的单词,组成有逻辑的句子,如何识别出正确的有歧义的单词,这些就用到语言模型了。
由于语音信号的时变性、噪声和其它一些不稳定因素,单纯靠声学模型无法达到较高的语音识别的准确率。在人类语言中,每一句话的单词直接有密切的联系,这些单词层面的信息可以减少声学模型上的搜索范围,有效地提高识别的准确性,要完成这项任务语言模型是必不可少的,它提供了语言中词之间的上下文信息以及语义信息。
随着统计语言处理方法的发展,统计语言模型成为语音识别中语言处理的主流技术,其中统计语言模型有很多种,如N-Gram语言模型、马尔可夫N元模型(Markov N-gram)、指数模型( Exponential Models)、决策树模型(Decision Tree Models)等。而N元语言模型是最常被使用的统计语言模型,特别是二元语言模型(bigram)、三元语言模型(trigram)。
2.6 字典
字典是存放所有单词的发音的词典,它的作用是用来连接声学模型和语言模型的。
识别出音素,利用字典,就可以查出单词了。
例如,一个句子可以分成若干个单词相连接,每个单词通过查询发音词典得到该单词发音的音素序列。相邻单词的转移概率可以通过语言模型获得,音素的概率模型可以通过声学模型获得。从而生成了这句话的一个概率模型。
2.7 解码器
解码器的作用就是将上述训练好的模型按照一定的规则组合起来,将新输入的语音识别出来。
语音识别评估标准
在语音识别中,常用的评估标准为词错误率(Word Error Rate,WER)。
我们上面讲了帧向量识别为单词,需要用声学模型。因为识别出来的整个词序列是混乱的,需要进行替换、删除、插入某些词,使得次序列有序完整。
WER就是反映上述过程的标准,能直接反映识别系统声学模型的性能,也是其他评估指标如句错误率SER的基础。
传统的词错误率评估算法在语音识别中存在三种典型的词错误:
-
替换错误(Substitution):在识别结果中,正确的词被错误的词代替;
-
删除错误(Deletion):在识别结果中,丢失了正确的词;
-
插入错误(Insertion):在识别结果中,增加了一个多余的词;
所以,词错误率为:
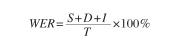
S 为替代错误词数,D 为删除错误词数,I 为插入错误词数。T为参照句子中的所有词数。
需要注意的是,因为有插入词,所以WER有可能大于100%。
以上。
参考文章:
《实用语音识别基础》 王炳锡,2005
《解析深度学习-语音识别实践》邓力,2016
原文始发于微信公众号(PMCAFF)