数据分析能力养成指南23:用Python分析用户消费行为
-

-
kawana55 这家伙很懒,还没有设置简介...
0 人点赞了该文章 · 177 浏览

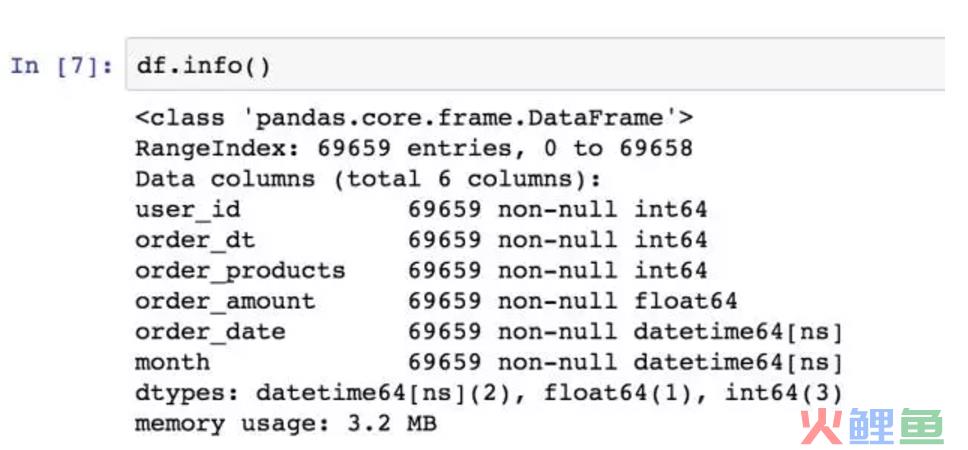
加载包和数据,文件是txt,用read_table方法打开,因为原始数据不包含表头,所以需要赋予。字符串是空格分割,用s+表示匹配任意空白符。
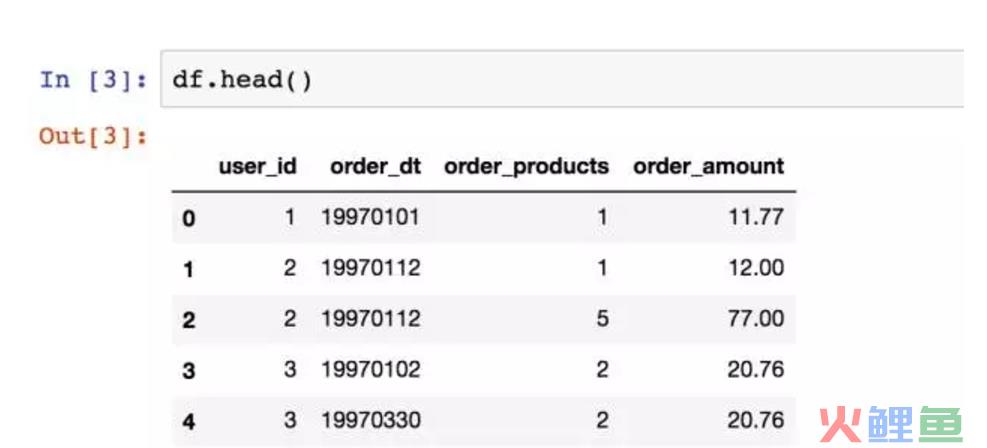
观察数据,order_dt表示时间,但现在它只是年月日组合的一串数字,没有时间含义。购买金额是小数。值得注意的是,一个用户在一天内可能购买多次,用户ID为2的用户就在1月12日买了两次,这个细节不要遗漏。
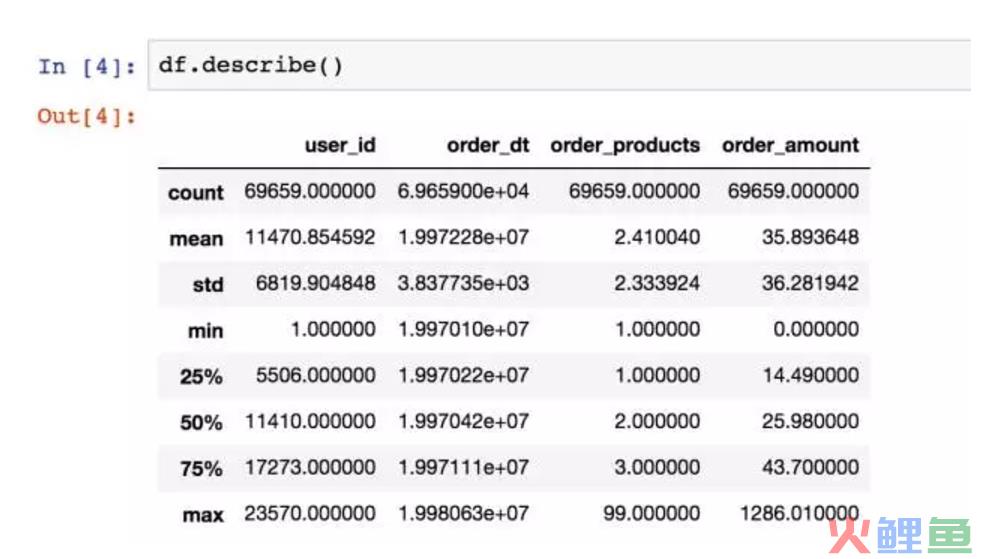
用户平均每笔订单购买2.4个商品,标准差在2.3,稍稍具有波动性。中位数在2个商品,75分位数在3个商品,说明绝大部分订单的购买量都不多。最大值在99个,数字比较高。购买金额的情况差不多,大部分订单都集中在小额。
一般而言,消费类的数据分布,都是长尾形态。大部分用户都是小额,然而小部分用户贡献了收入的大头,俗称二八。
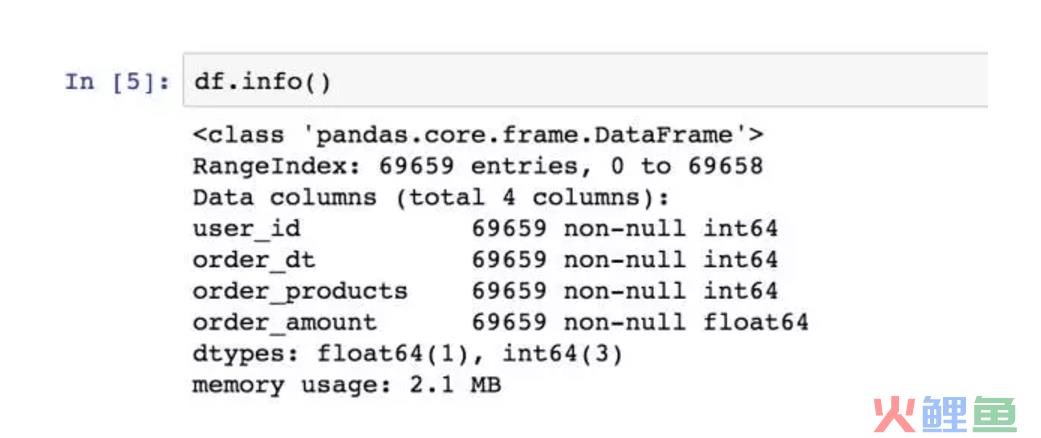
没有空值,很干净的数据。接下来我们要将时间的数据类型转换。

pd.to_datetime可以将特定的字符串或者数字转换成时间格式,其中的format参数用于匹配。例如19970101,%Y匹配前四位数字1997,如果y小写只匹配两位数字97,%m匹配01,%d匹配01。
另外,小时是%h,分钟是%M,注意和月的大小写不一致,秒是%s。若是1997-01-01这形式,则是%Y-%m-%d,以此类推。
astype也可以将时间格式进行转换,比如[M]转化成月份。我们将月份作为消费行为的主要事件窗口,选择哪种时间窗口取决于消费频率。
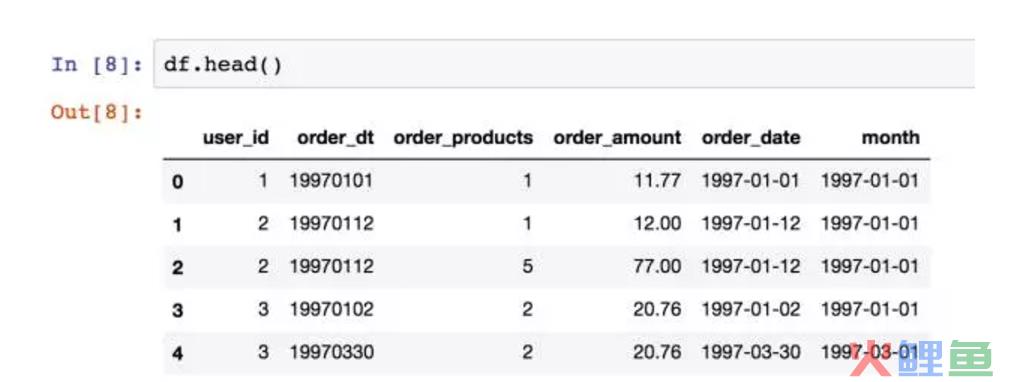
上图是转化后的格式。月份依旧显示日,只是变为月初的形式。
pandas中有专门的时间序列方法tseries,它可以用来进行时间偏移,也是处理时间类型的好方法。时间格式也能作为索引,在金融、财务等领域使用较多,这里不再多叙述了。

上面的消费行为数据粒度是每笔订单,我们转换成每位用户看一下。
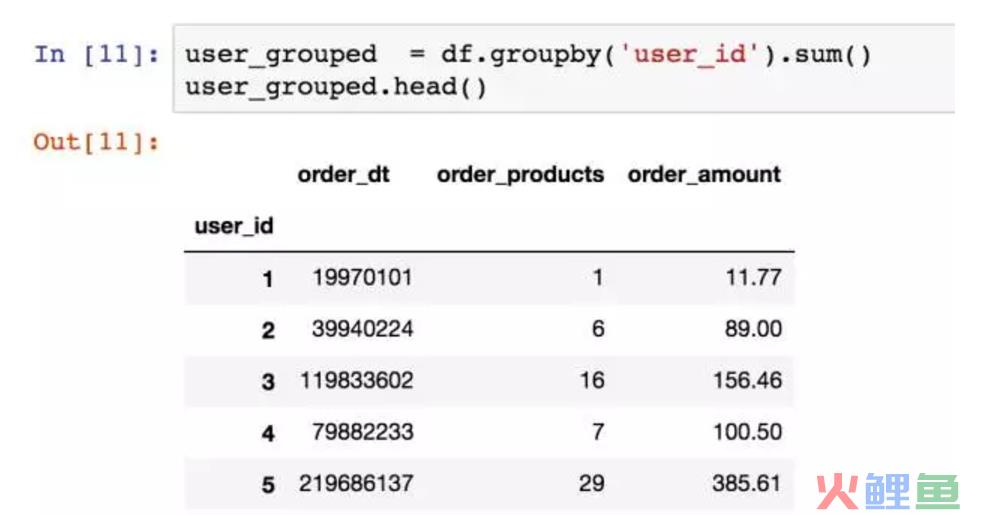
用groupby创建一个新对象。
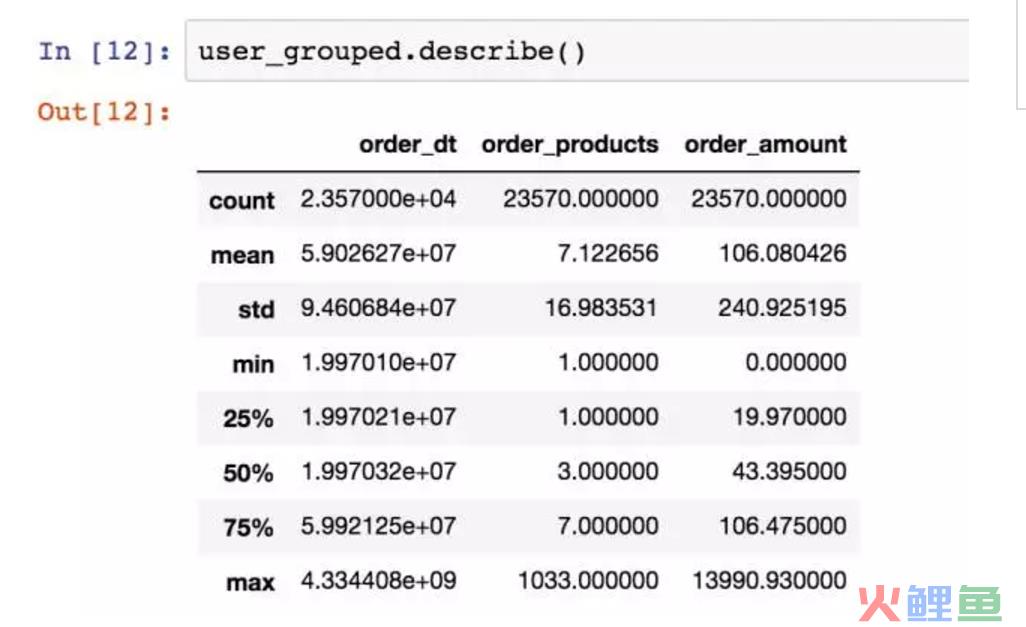
从用户角度看,每位用户平均购买7张CD,最多的用户购买了1033张,属于狂热用户了。用户的平均消费金额(客单价)100元,标准差是240,结合分位数和最大值看,平均值才和75分位接近,肯定存在小部分的高额消费用户。
接下来按月的维度分析。
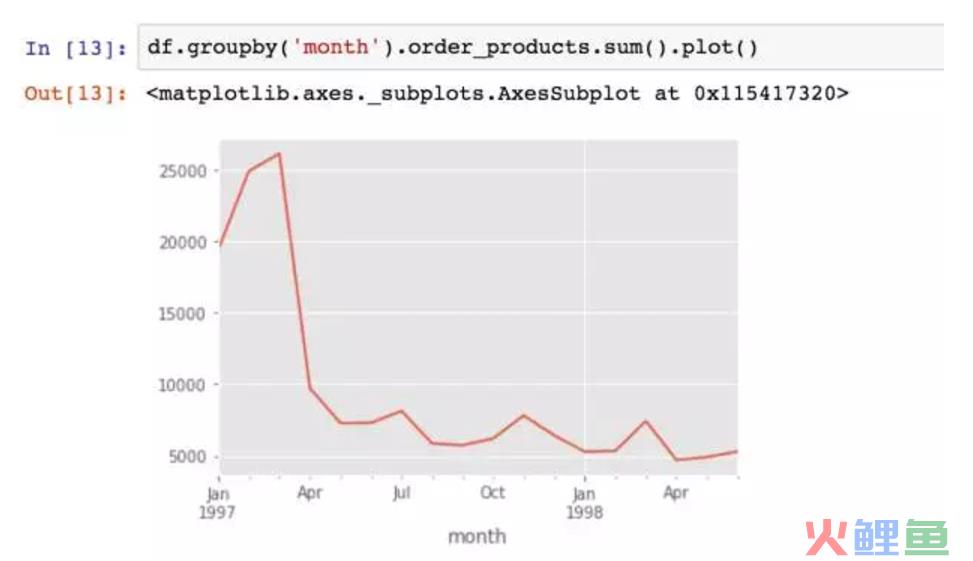
按月统计每个月的CD销量。从图中可以看到,前几个月的销量非常高涨。数据比较异常。而后期的销量则很平稳。
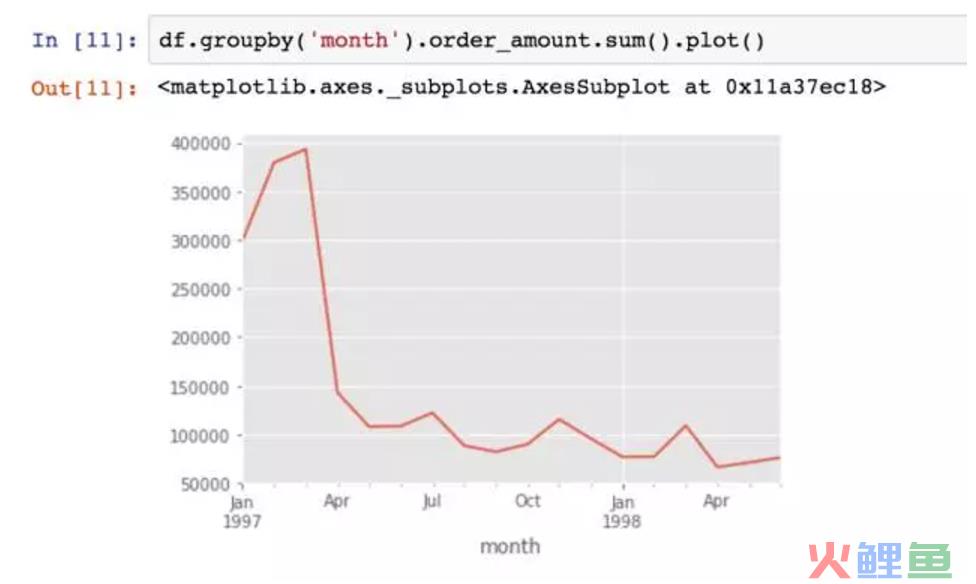
金额一样呈现早期销售额多,后期平稳下降的趋势。为什么会呈现这个原因呢?我们假设是用户身上出了问题,早期时间段的用户中有异常值,第二假设是各类促销营销,但这里只有消费数据,所以无法判断。
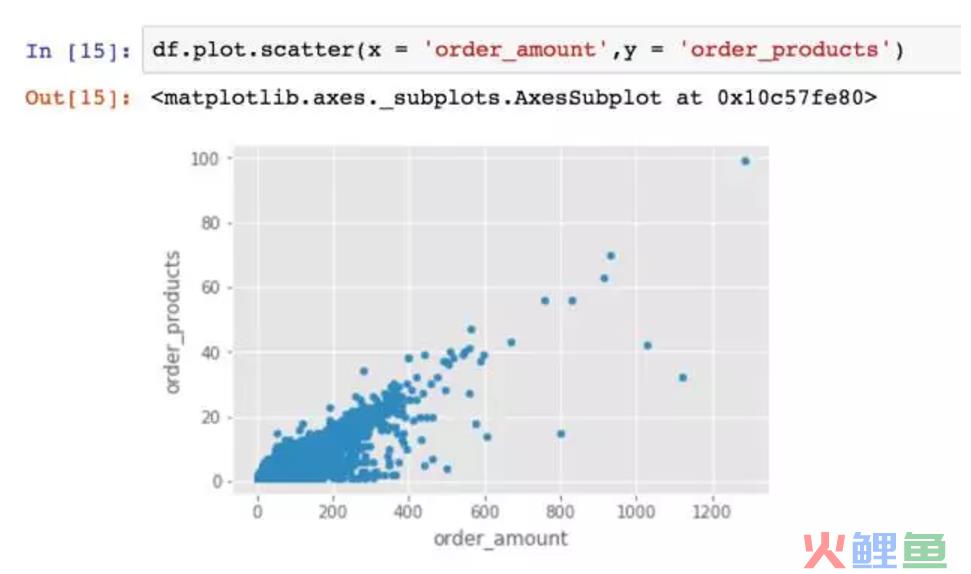
绘制每笔订单的散点图。从图中观察,订单消费金额和订单商品量呈规律性,每个商品十元左右。订单的极值较少,超出1000的就几个。显然不是异常波动的罪魁祸首。
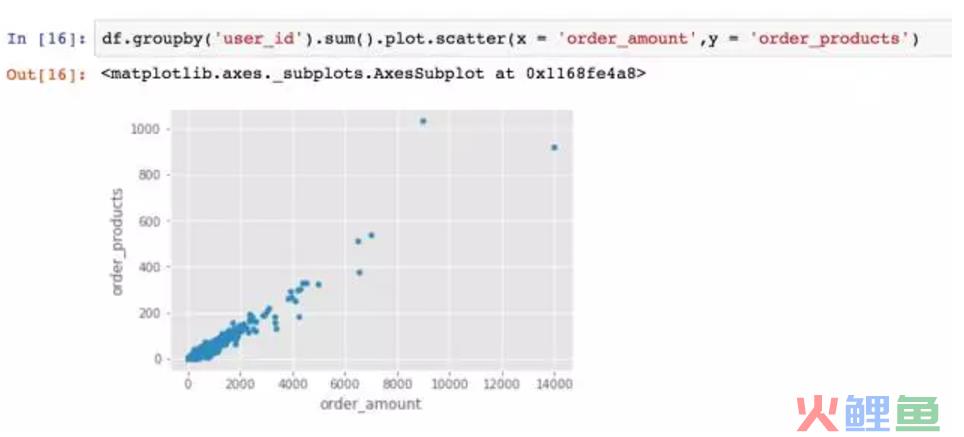
绘制用户的散点图,用户也比较健康,而且规律性比订单更强。因为这是CD网站的销售数据,商品比较单一,金额和商品量的关系也因此呈线性,没几个离群点。
消费能力特别强的用户有,但是数量不多。为了更好的观察,用直方图。
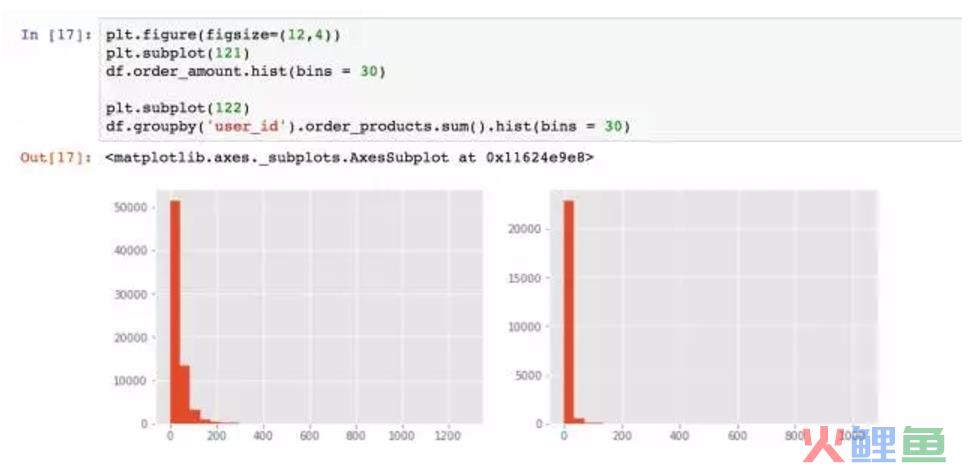
plt.subplot用于绘制子图,子图用数字参数表示。121表示分成1*2个图片区域,占用第一个,即第一行第一列,122表示占用第二个。figure是尺寸函数,为了容纳两张子图,宽设置的大一点即可。
从直方图看,大部分用户的消费能力确实不高,高消费用户在图上几乎看不到。这也确实符合消费行为的行业规律。
观察完用户消费的金额和购买量,接下来看消费的时间节点。
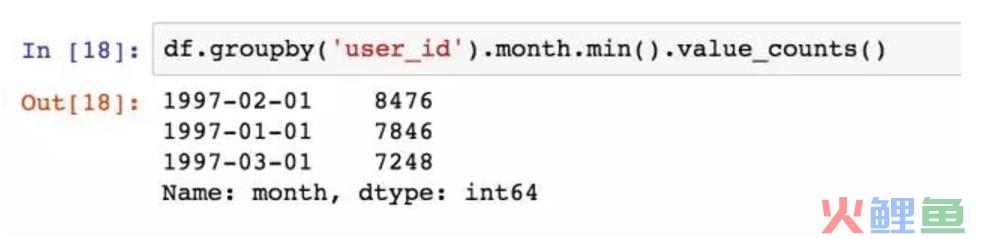
用groupby函数将用户分组,并且求月份的最小值,最小值即用户消费行为中的第一次消费时间。ok,结果出来了,所有用户的第一次消费都集中在前三个月。我们可以这样认为,案例中的订单数据,只是选择了某个时间段消费的用户在18个月内的消费行为。
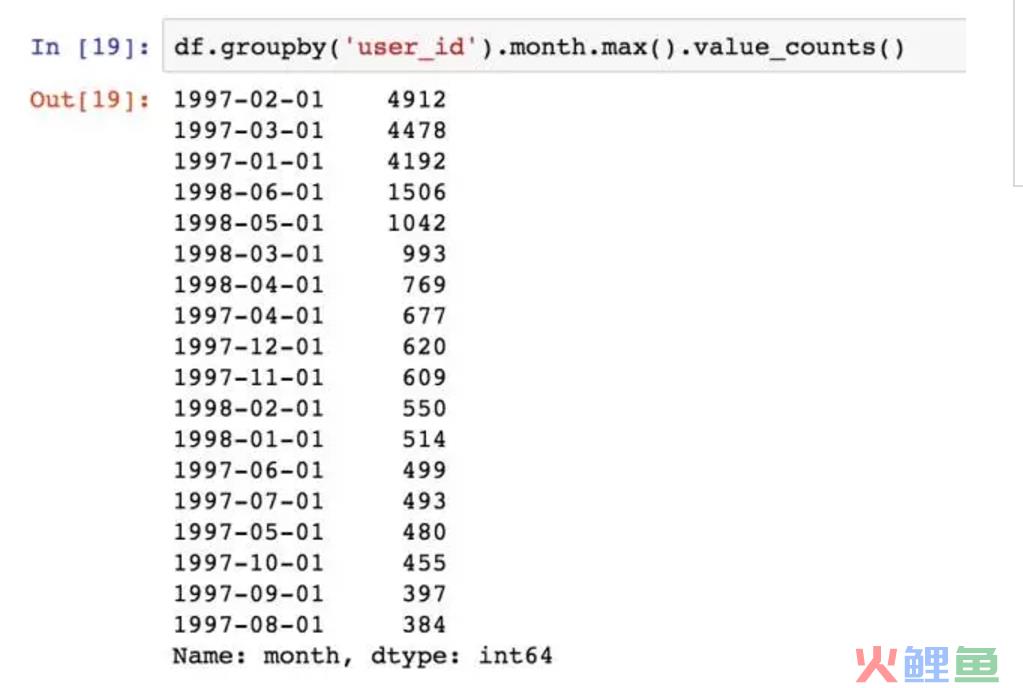
观察用户的最后一次消费时间。绝大部分数据依然集中在前三个月。后续的时间段内,依然有用户在消费,但是缓慢减少。
异常趋势的原因获得了解释,现在针对消费数据进一步细分。我们要明确,这只是部分用户的订单数据,所以有一定局限性。在这里,我们统一将数据上消费的用户定义为新客。
接下来分析消费中的复购率和回购率。首先将用户消费数据进行数据透视。
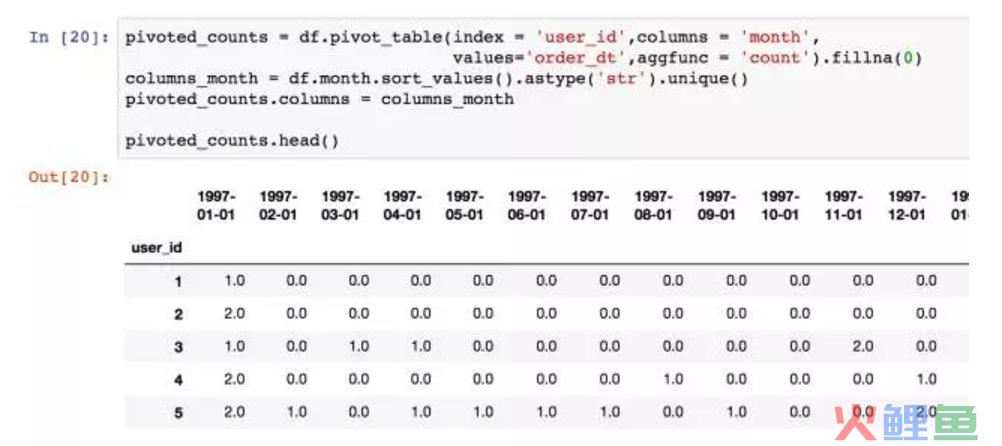
在pandas中,数据透视有专门的函数pivot_table,功能非常强大。pivot_table参数中,index是设置数据透视后的索引,column是设置数据透视后的列,简而言之,index是你想要的行,column是想要的列。案例中,我希望统计每个用户在每月的订单量,所以user_id是index,month是column。
values是将哪个值进行计算,aggfunc是用哪种方法。于是这里用values=order_dt和aggfunc=count,统计里order_dt出现的次数,即多少笔订单。
使用数据透视表,需要明确获得什么结果。有些用户在某月没有进行过消费,会用NaN表示,这里用fillna填充。
生成的数据透视,月份是1997-01-01 00:00:00表示,比较丑。将其优化成标准格式。
首先求复购率,复购率的定义是在某时间窗口内消费两次及以上的用户在总消费用户中占比。这里的时间窗口是月,如果一个用户在同一天下了两笔订单,这里也将他算作复购用户。
将数据转换一下,消费两次及以上记为1,消费一次记为0,没有消费记为NaN。
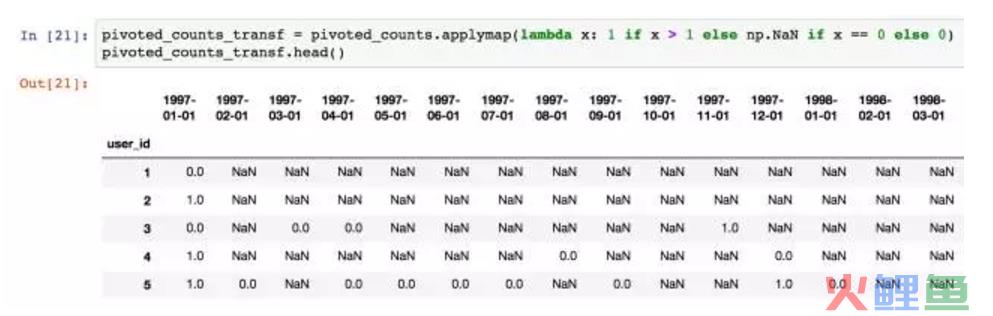
applymap针对DataFrame里的所有数据。用lambda进行判断,因为这里涉及了多个结果,所以要两个if else,记住,lambda没有elif的用法。
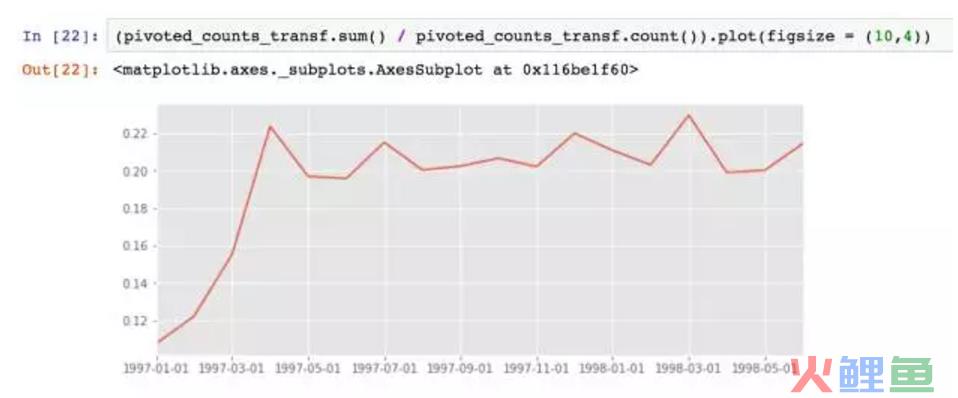
用sum和count相除即可计算出复购率。因为这两个函数都会忽略NaN,而NaN是没有消费的用户,count不论0还是1都会统计,所以是总的消费用户数,而sum求和计算了两次以上的消费用户。这里用了比较巧妙的替代法计算复购率,SQL中也可以用。
图上可以看出复购率在早期,因为大量新用户加入的关系,新客的复购率并不高,譬如1月新客们的复购率只有6%左右。而在后期,这时的用户都是大浪淘沙剩下的老客,复购率比较稳定,在20%左右。
单看新客和老客,复购率有三倍左右的差距。
接下来计算回购率。回购率是某一个时间窗口内消费的用户,在下一个时间窗口仍旧消费的占比。我1月消费用户1000,他们中有300个2月依然消费,回购率是30%。
回购率的计算比较难,因为它设计了横向跨时间窗口的对比。
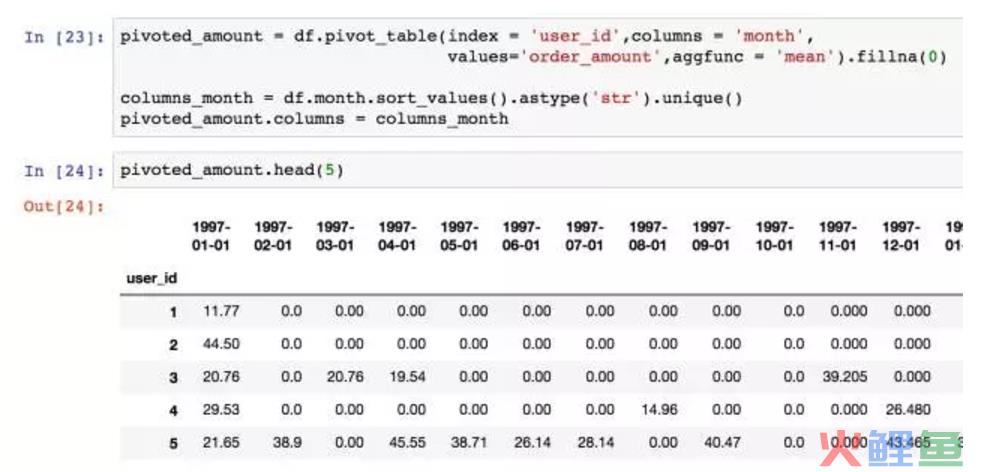
将消费金额进行数据透视,这里作为练习,使用了平均值。
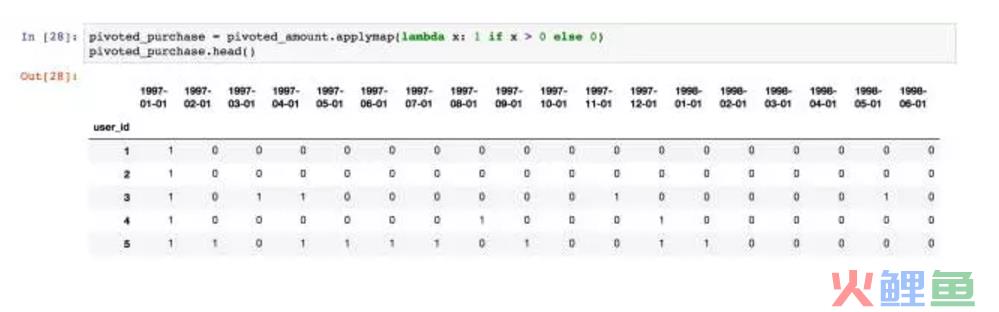
再次用applymap+lambda转换数据,只要有过购买,记为1,反之为0。
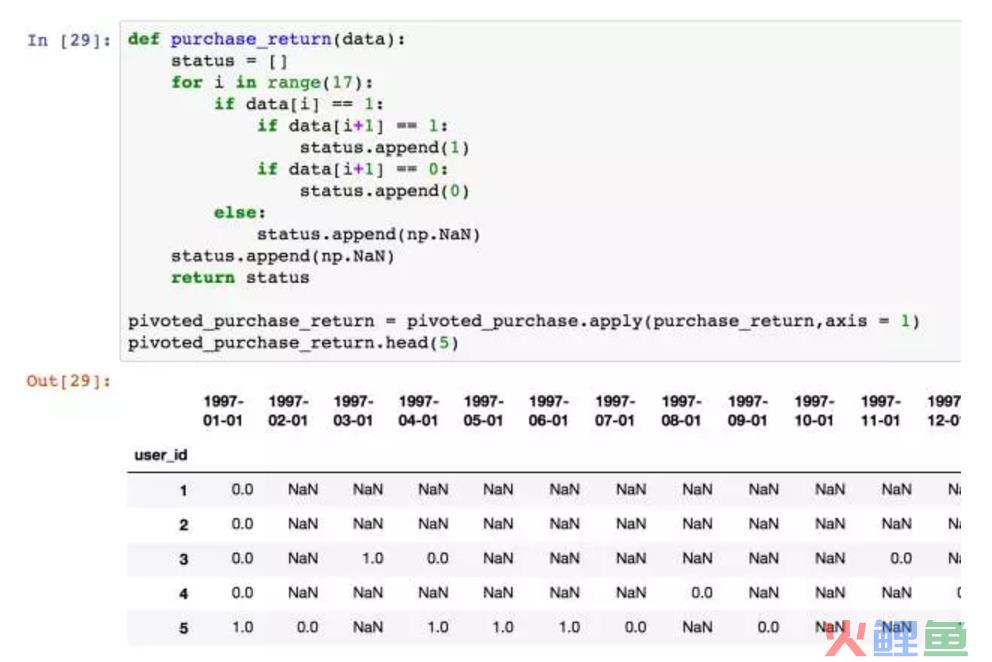
新建一个判断函数。data是输入的数据,即用户在18个月内是否消费的记录,status是空列表,后续用来保存用户是否回购的字段。
因为有18个月,所以每个月都要进行一次判断,需要用到循环。if的主要逻辑是,如果用户本月进行过消费,且下月消费过,记为1,没有消费过是0。本月若没有进行过消费,为NaN,后续的统计中进行排除。
用apply函数应用在所有行上,获得想要的结果。
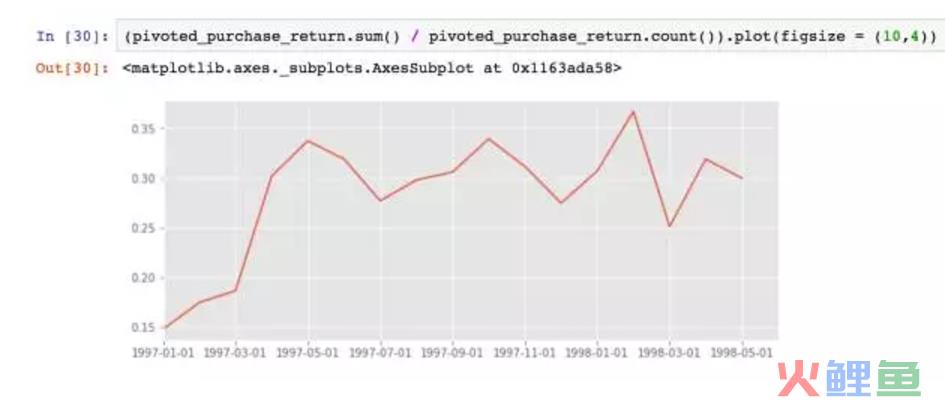
最后的计算和复购率大同小异,用count和sum求出。从图中可以看出,用户的回购率高于复购,约在30%左右,波动性也较强。新用户的回购率在15%左右,和老客差异不大。
将回购率和复购率综合分析,可以得出,新客的整体质量低于老客,老客的忠诚度(回购率)表现较好,消费频次稍次,这是CDNow网站的用户消费特征。
接下来进行用户分层,我们按照用户的消费行为,简单划分成几个维度:新用户、活跃用户、不活跃用户、回流用户。
新用户的定义是第一次消费。活跃用户即老客,在某一个时间窗口内有过消费。不活跃用户则是时间窗口内没有消费过的老客。回流用户是在上一个窗口中没有消费,而在当前时间窗口内有过消费。以上的时间窗口都是按月统计。
比如某用户在1月第一次消费,那么他在1月的分层就是新用户;他在2月消费国,则是活跃用户;3月没有消费,此时是不活跃用户;4月再次消费,此时是回流用户,5月还是消费,是活跃用户。
分层会涉及到比较复杂的逻辑判断。
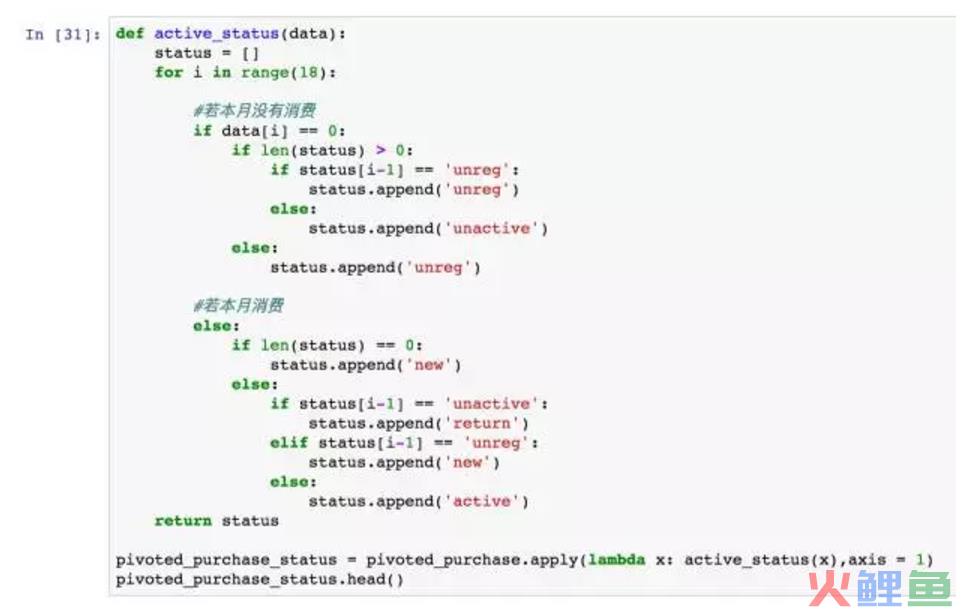
函数写得比较复杂,主要分为两部分的判断,以本月是否消费为界。本月没有消费,还要额外判断他是不是新客,因为部分用户是3月份才消费成为新客,那么在1、2月份他应该连新客都不是,用unreg表示。如果是老客,则为unactive。
本月若有消费,需要判断是不是第一次消费,上一个时间窗口有没有消费。大家可以多调试几次理顺里面的逻辑关系,对用户进行分层,逻辑确实不会简单,而且这里只是简化版本的。

从结果看,用户每个月的分层状态以及变化已经被我们计算出来。我是根据透视出的宽表计算,其实还有一种另外一种写法,只提取时间窗口内的数据和上个窗口对比判断,封装成函数做循环,它适合ETL的增量更新。
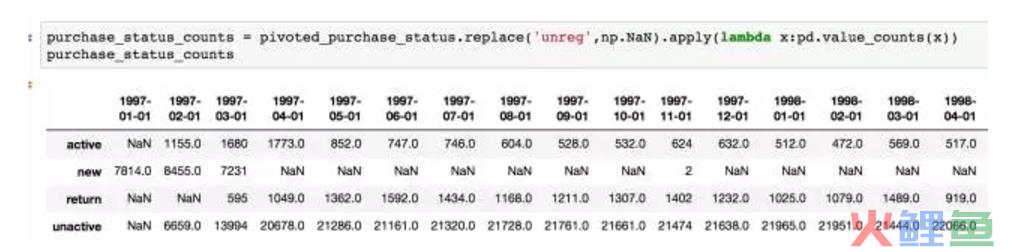 unreg状态排除掉,它是「未来」才作为新客,这么能计数呢。换算成不同分层每月的统计量。
unreg状态排除掉,它是「未来」才作为新客,这么能计数呢。换算成不同分层每月的统计量。
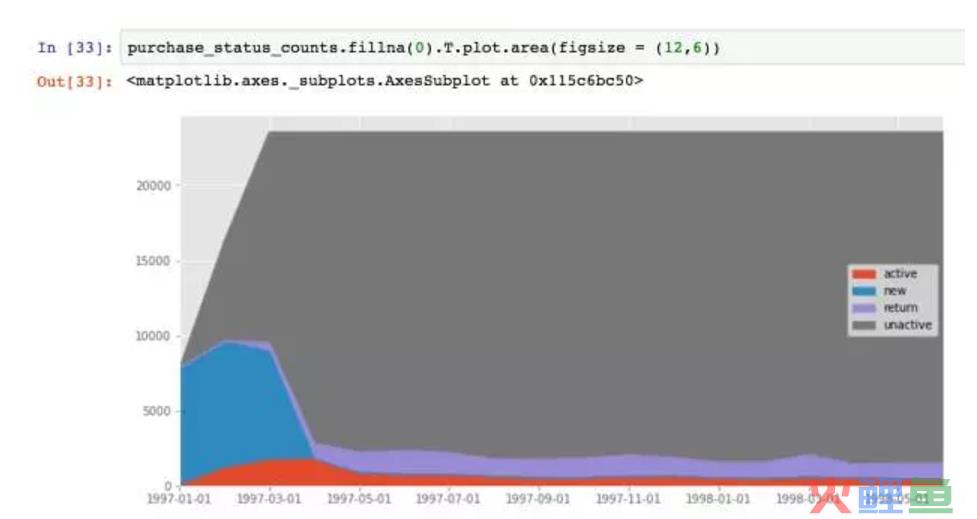
生成面积图,比较丑。因为它只是某时间段消费过的用户的后续行为,蓝色和灰色区域都可以不看。只看紫色回流和红色活跃这两个分层,用户数比较稳定。这两个分层相加,就是消费用户占比(后期没新客)。
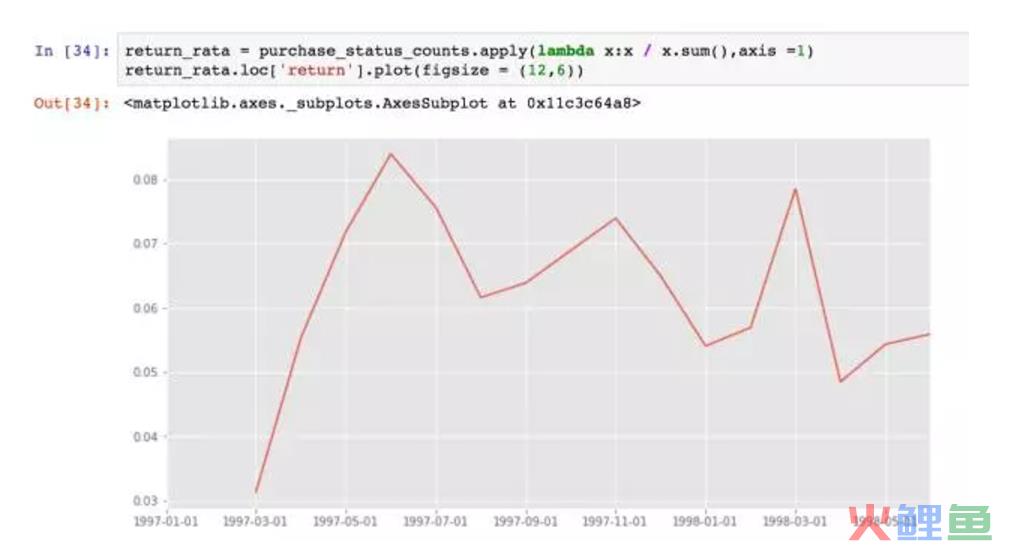
用户回流占比在5%~8%,有下降趋势。所谓回流占比,就是回流用户在总用户中的占比。另外一种指标叫回流率,指上个月多少不活跃/消费用户在本月活跃/消费。因为不活跃的用户总量近似不变,所以这里的回流率也近似回流占比。
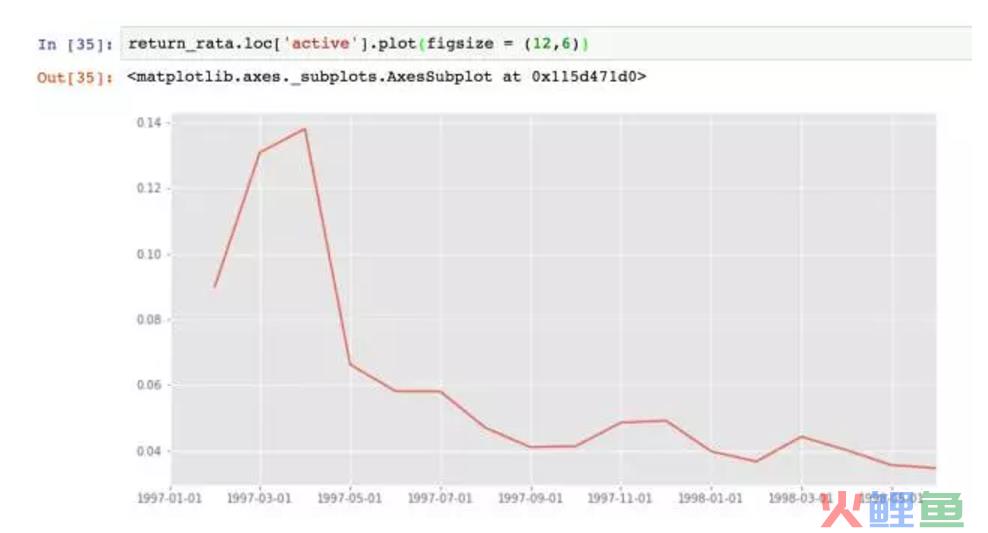
活跃用户的下降趋势更明显,占比在3%~5%间。这里用户活跃可以看作连续消费用户,质量在一定程度上高于回流用户。
结合回流用户和活跃用户看,在后期的消费用户中,60%是回流用户,40%是活跃用户/连续消费用户,整体质量还好,但是针对这两个分层依旧有改进的空间,可以继续细化数据。
接下来分析用户质量,因为消费行为有明显的二八倾向,我们需要知道高质量用户为消费贡献了多少份额。
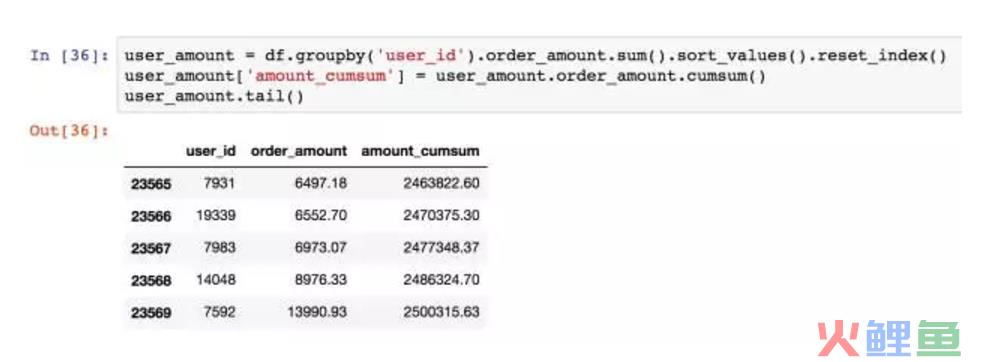
新建一个对象,按用户的消费金额生序。使用cumsum,它是累加函数。逐行计算累计的金额,最后的2500315便是总消费额。
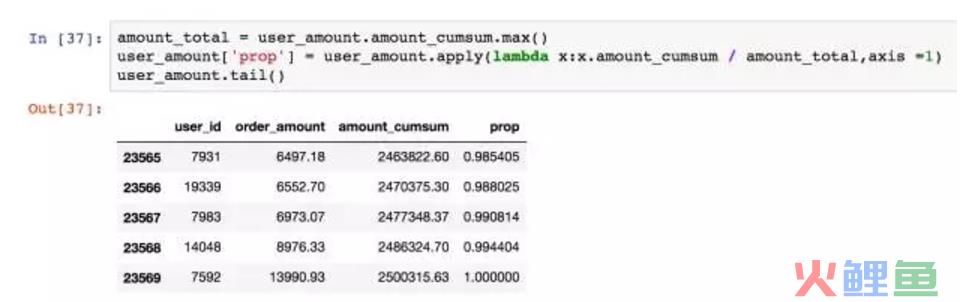
转换成百分比。
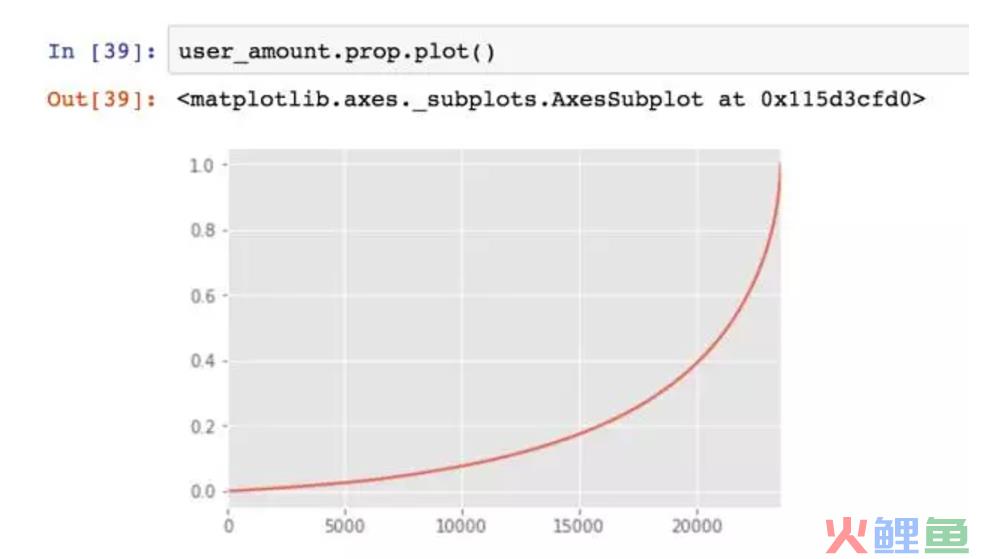
绘制趋势图,横坐标是按贡献金额大小排序而成,纵坐标则是用户累计贡献。可以很清楚的看到,前20000个用户贡献了40%的消费。后面4000位用户贡献了60%,确实呈现28倾向。
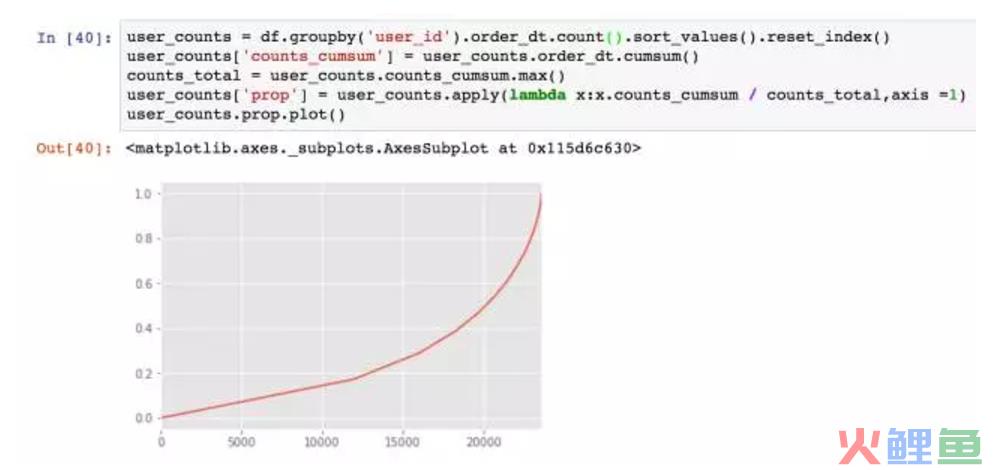
统计一下销量,前两万个用户贡献了45%的销量,高消费用户贡献了55%的销量。在消费领域中,狠抓高质量用户是万古不变的道理。
接下来计算用户生命周期,这里定义第一次消费至最后一次消费为整个用户生命。

统计出用户第一次消费和最后一次消费的时间,相减,得出每一位用户的生命周期。因为数据中的用户都是前三个月第一次消费,所以这里的生命周期代表的是1月~3月用户的生命周期。因为用户会持续消费,所以理论上,随着后续的消费,用户的平均生命周期会增长。

求一下平均,所有用户的平均生命周期是134天,比预想的高,但是平均数不靠谱,还是看一下分布吧,大家有兴趣可以用describe,更详细。
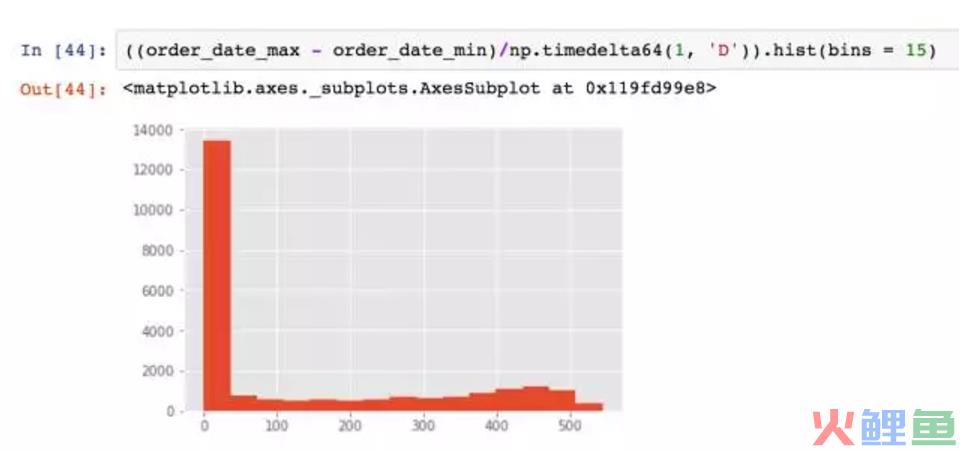
因为这里的数据类型是timedelta时间,它无法直接作出直方图,所以先换算成数值。换算的方式直接除timedelta函数即可,这里的np.timedelta64(1, ‘D’),D表示天,1表示1天,作为单位使用的。因为max-min已经表示为天了,两者相除就是周期的天数。
看到了没有,大部分用户只消费了一次,所有生命周期的大头都集中在了0天。但这不是我们想要的答案,不妨将只消费了一次的新客排除,来计算所有消费过两次以上的老客的生命周期。
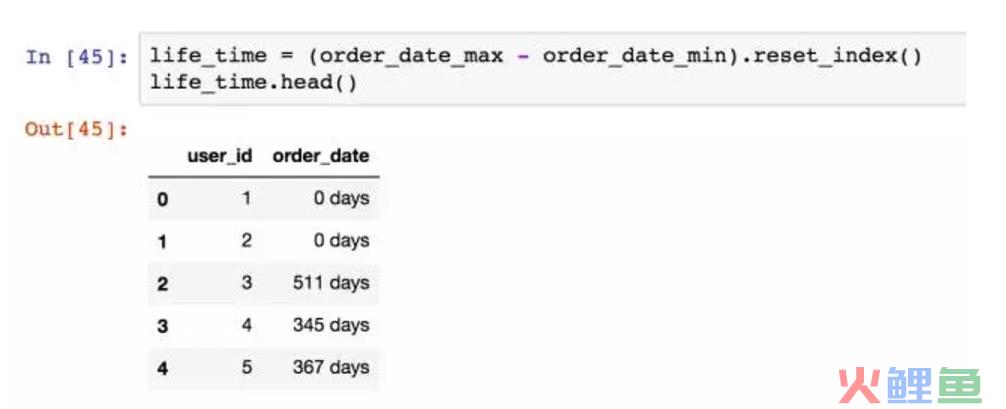
转换成DataFrame。
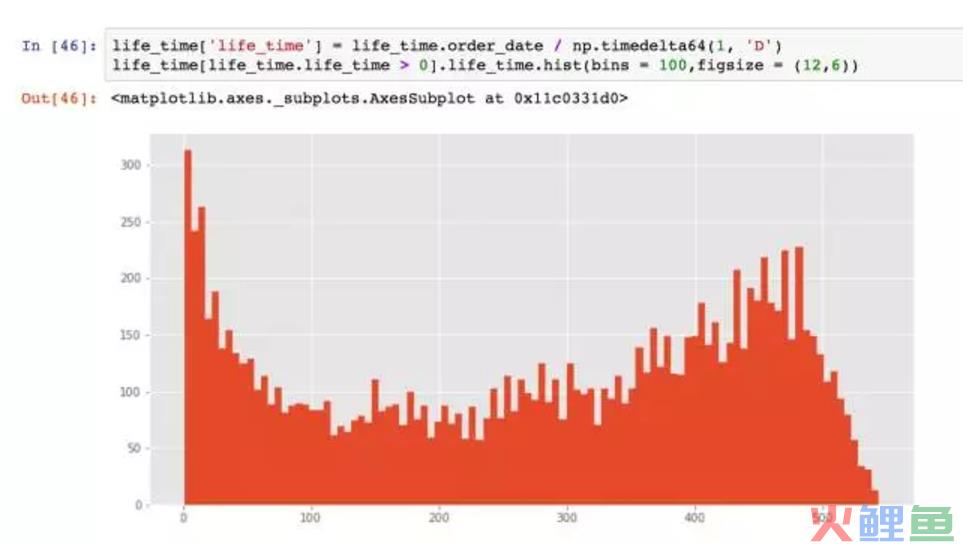
筛选出lifetime>0,即排除了仅消费了一次的那些人。做直方图。
这个图比上面的靠谱多了,虽然仍旧有不少用户生命周期靠拢在0天。这是双峰趋势图。部分质量差的用户,虽然消费了两次,但是仍旧无法持续,在用户首次消费30天内应该尽量引导。少部分用户集中在50天~300天,属于普通型的生命周期,高质量用户的生命周期,集中在400天以后,这已经属于忠诚用户了,大家有兴趣可以跑一下400天+的用户占老客比多少,占总量多少。

消费两次以上的用户生命周期是276天,远高于总体。从策略看,用户首次消费后应该花费更多的引导其进行多次消费,提供生命周期,这会带来2.5倍的增量。
再来计算留存率,留存率也是消费分析领域的经典应用。它指用户在第一次消费后,有多少比率进行第二次消费。和回流率的区别是留存倾向于计算第一次消费,并且有多个时间窗口。
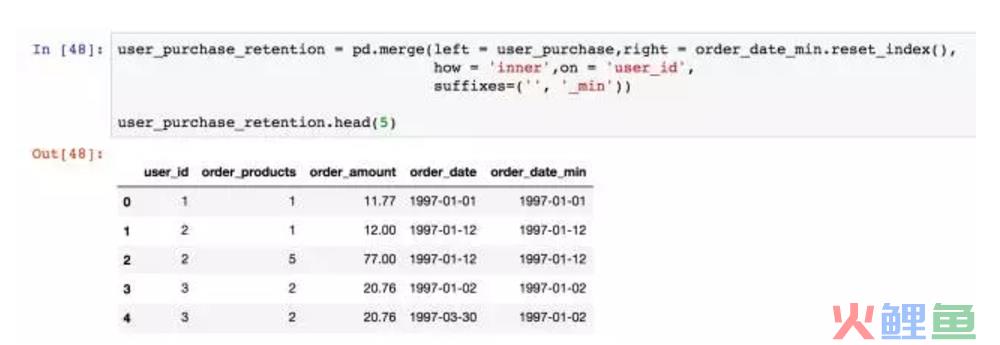
这里用到merge函数,它和SQL中的join差不多,用来将两个DataFrame进行合并。我们选择了inner 的方式,对标inner join。即只合并能对应得上的数据。这里以on=user_id为对应标准。这里merge的目的是将用户消费行为和第一次消费时间对应上,形成一个新的DataFrame。suffxes参数是如果合并的内容中有重名column,加上后缀。除了merge,还有join,concat,用户接近,查看文档即可。
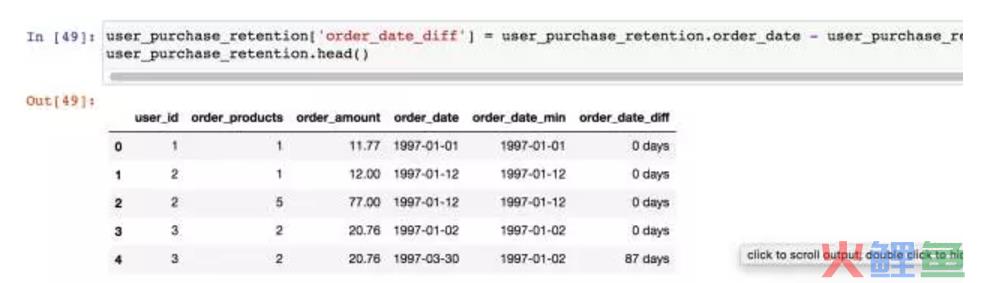
这里将order_date和order_date_min相减。获得一个新的列,为用户每一次消费距第一次消费的时间差值。
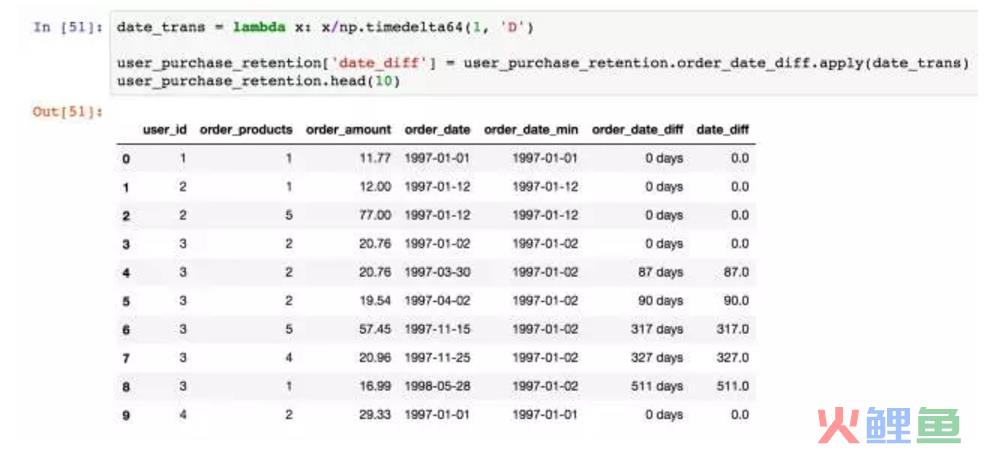
日期转换成时间。
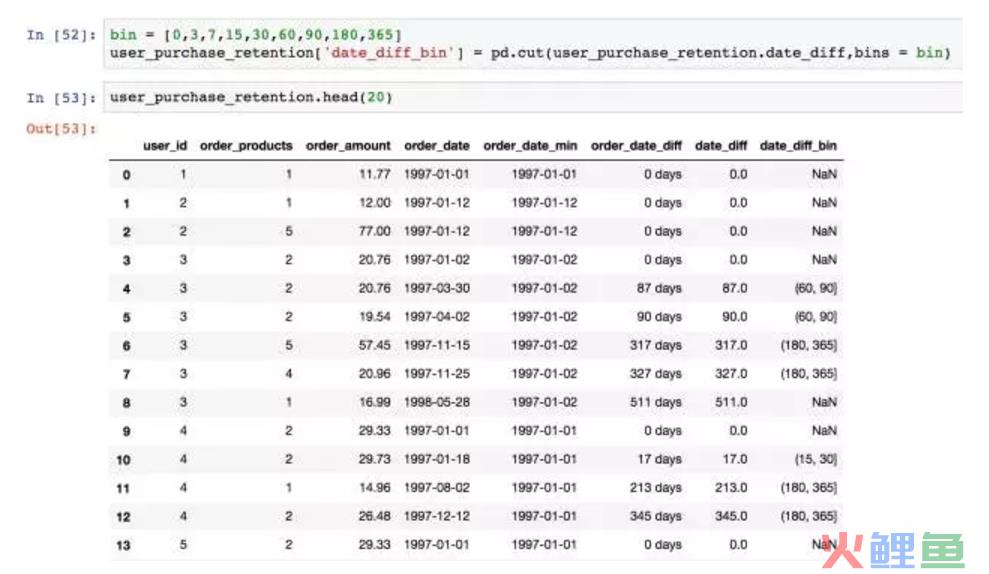
将时间差值分桶。我这里分成0~3天内,3~7天内,7~15天等,代表用户当前消费时间距第一次消费属于哪个时间段呢。这里date_diff=0并没有被划分入0~3天,因为计算的是留存率,如果用户仅消费了一次,留存率应该是0。另外一方面,如果用户第一天内消费了多次,但是往后没有消费,也算作留存率0。
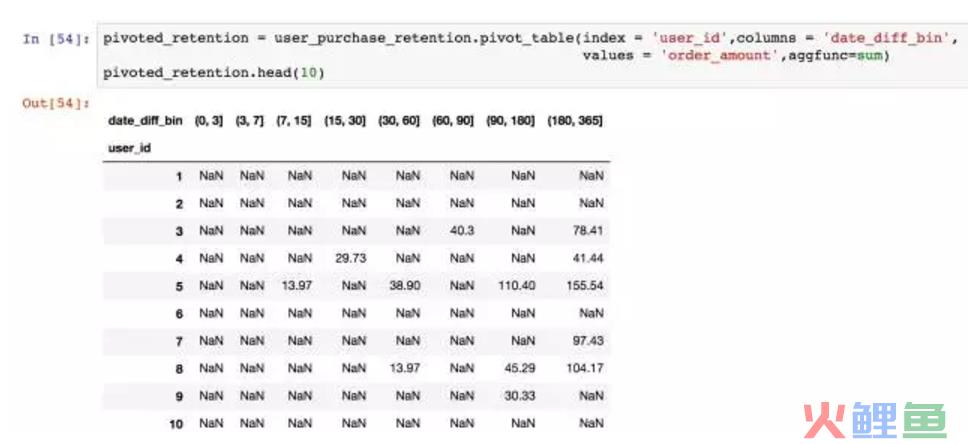
用pivot_table数据透视,获得的结果是用户在第一次消费之后,在后续各时间段内的消费总额。
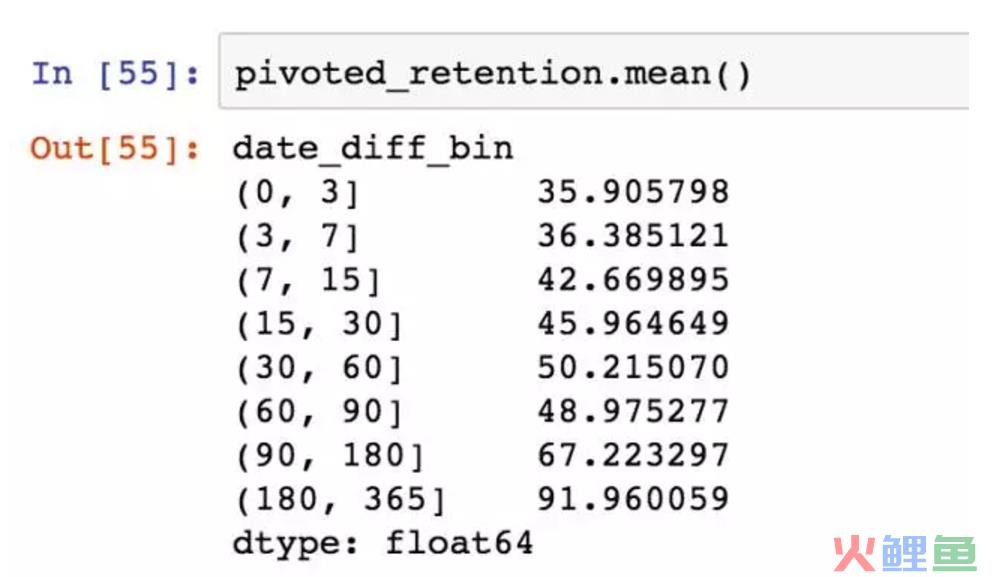
计算一下用户在后续各时间段的平均消费额,这里只统计有消费的平均值。虽然后面时间段的金额高,但是它的时间范围也宽广。从平均效果看,用户第一次消费后的0~3天内,更可能消费更多。
但消费更多是一个相对的概念,我们还要看整体中有多少用户在0~3天消费。
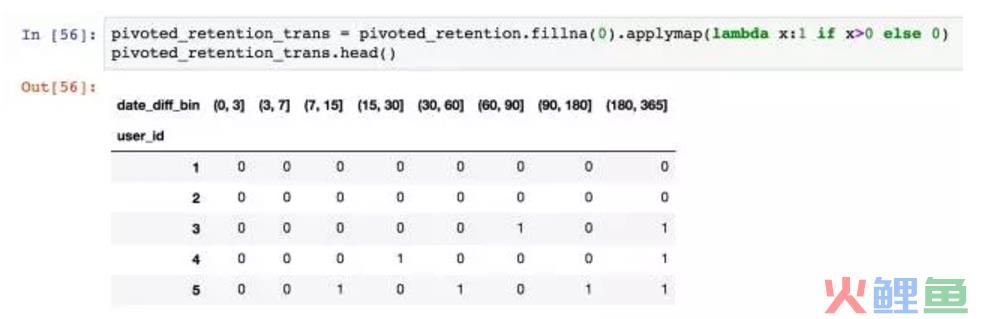
依旧将数据转换成是否,1代表在该时间段内有后续消费,0代表没有。
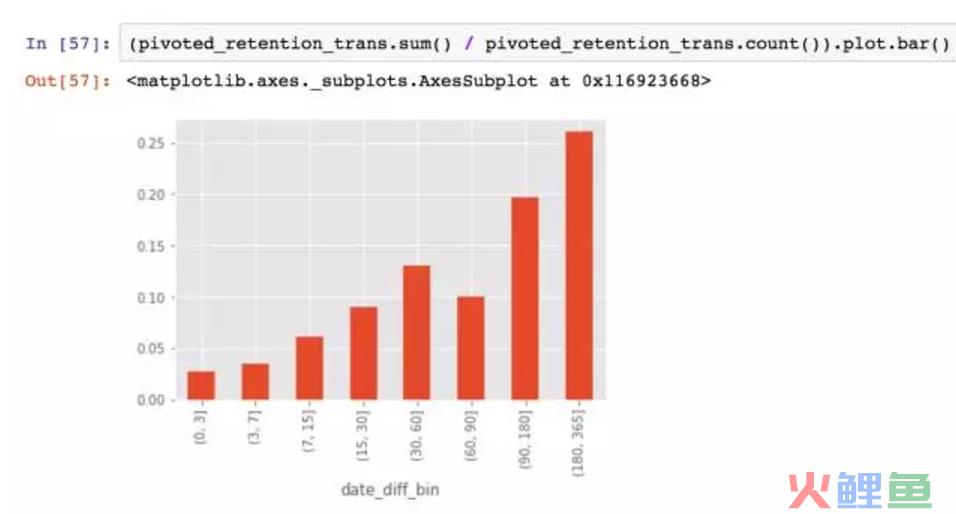
只有2.5%的用户在第一次消费的次日至3天内有过消费,3%的用户在3~7天内有过消费。数字并不好看,CD购买确实不是高频消费行为。时间范围放宽后数字好看了不少,有20%的用户在第一次消费后的三个月到半年之间有过购买,27%的用户在半年后至1年内有过购买。从运营角度看,CD机营销在教育新用户的同时,应该注重用户忠诚度的培养,放长线掉大鱼,在一定时间内召回用户购买。
怎么算放长线掉大鱼呢?我们计算出用户的平均购买周期。
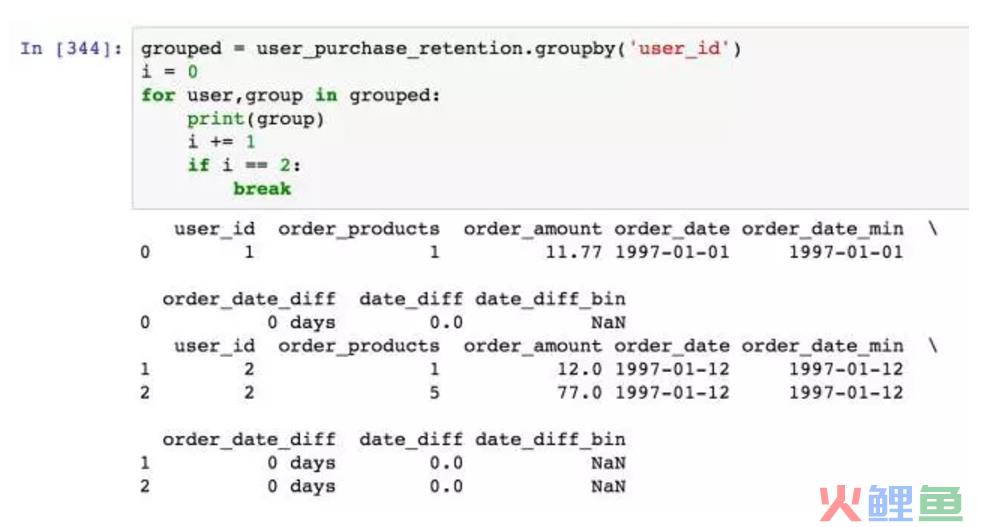
我们将用户分组,groupby分组后的数据,也是能用for进行循环和迭代的。第一个循环对象user,是分组的对象,即user_id;第二个循环对象group,是分组聚合后的结果。为了举例我用了print,它依次输出了user_id=1,user_id=2时的用户消费数据,是一组切割后的DataFrame。
大家应该了解分组循环的用法,但是网不建议大家用for循环,它的效率非常慢。要计算用户的消费间隔,确实需要用户分组,但是用apply效率更快。
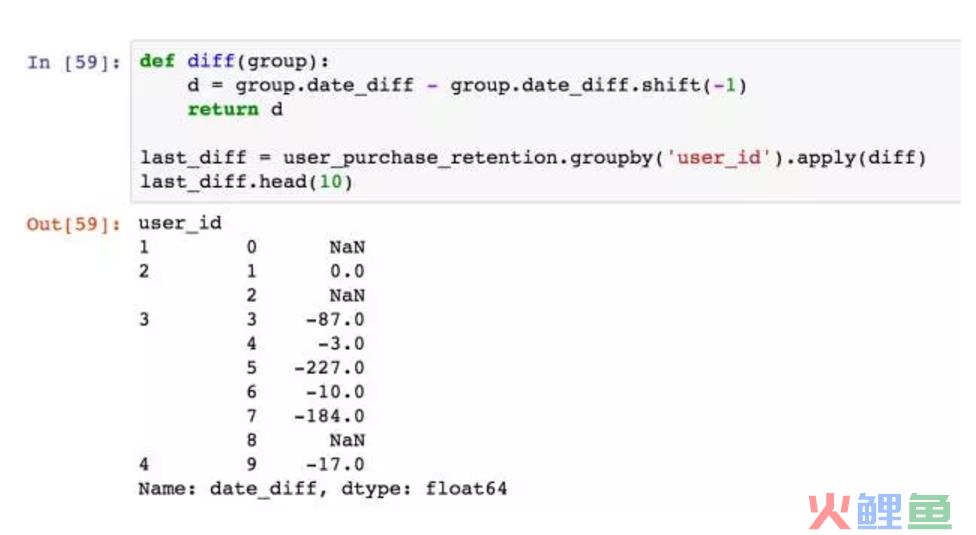
定义一个计算间隔的函数diff,输入的是group,通过上面的演示,大家也应该知道分组后的数据依旧是DataFrame。我们将用户上下两次消费时间相减将能求出消费间隔了。shift函数是一个偏移函数,和excel上的offset差不多。
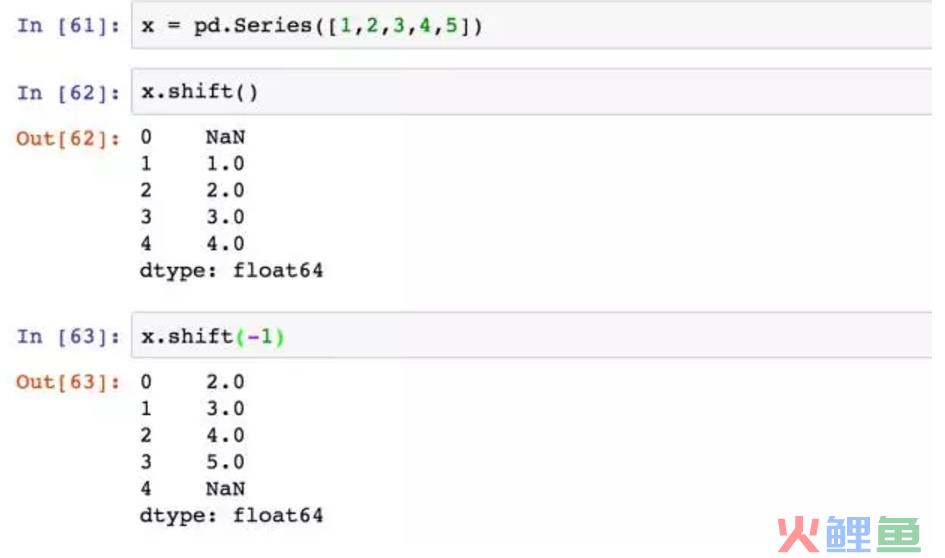
x.shift()是往上偏移一个位置,x.shift(-1)是往下偏移一个位置,加参数axis=1则是左右偏移。当我想将求用户下一次距本次消费的时间间隔,用shift(-1)减当前值即可。案例用的diff函数便借助shift方法,巧妙的求出了每位用户的两次消费间隔,若为NaN,则没有下一次。
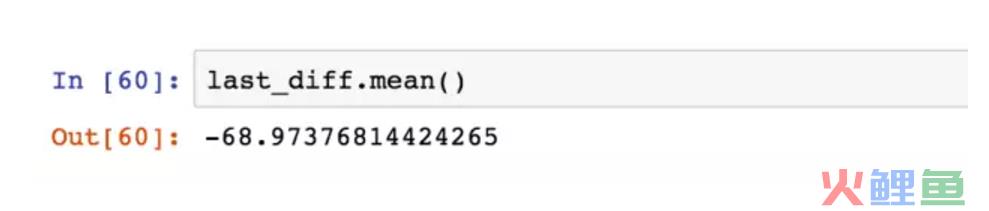
然后就简单了,用mean函数即可求出用户的平均消费间隔时间是68天。想要召回用户,在60天左右的消费间隔是比较好的。
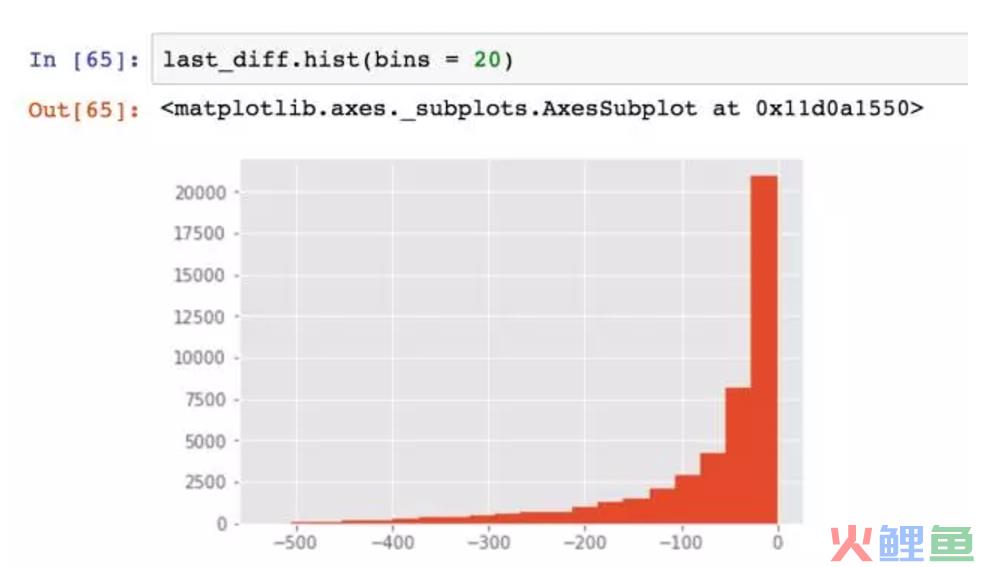
看一下直方图,典型的长尾分布,大部分用户的消费间隔确实比较短。不妨将时间召回点设为消费后立即赠送优惠券,消费后10天询问用户CD怎么样,消费后30天提醒优惠券到期,消费后60天短信推送。这便是数据的应用了。
假若大家有兴趣,不妨多做几个分析假设,看能不能用Python挖掘出更有意思的数据,1月、2月、3月的新用户在留存率有没有差异?不同生命周期的用户,他们的消费累加图是什么样的?消费留存,划分其他时间段怎么样?
你若想要追求更好的Python技术,可以把上述的分析过程都封装成函数。当下次想要再次分析的时候,怎么样只用几个函数就搞定,而不是继续重复码代码。
这里的数据只是用户ID,消费时间,购买量和消费金额。如果换成用户ID,浏览时间,浏览量,能不能直接套用?浏览变成评论、点赞又行不行?消费行为变成用户其他行为呢?我可以明确地告诉你,大部分代码只要替换部分就能直接用了。把所有的结果分析出来需要花费多少时间呢?
Python的优势就在于快速和灵活,远比Excel和SQL快。这次是CD网站的消费行为,下次换成电商,换成O2O,一样可以在几分钟内计算出用户生命周期,用户购买频次,留存率复购率回购率等等。这对你的效率提升有多大帮助?
经过一系列的讲解,你是否掌握了Python的数据分析姿势?这里的很多技巧,都和我以前的文章相关,有excel的函数影子,有数据可视化的用法,有分析思路,有描述统计的知识,有各种业务指标,有接近SQL的数据规整,虽然是Python进行数据分析,也是整个数据分析的总结。
所以,所有的课程都结束啦。在网络上,大概也找不出几篇像本文一样,将各方面结合地很好的内容了。更希望你时常复习,学无止境。
谢谢大家,七周成为数据分析师,告一段落。后续还有一篇汇总。
相关阅读
一份七周的互联网数据分析能力养成提纲
数据分析能力养成指南01:Excel函数应用汇总
数据分析能力养成指南02:Excel技巧大揭秘
数据分析能力养成指南03:手把手教你Excel实战
数据分析能力养成指南:Excel技巧之甘特图绘制(项目管理)
数据分析能力养成指南:Excel技巧之打造多级菜单
数据分析能力养成指南04:数据可视化之经典图表合集
数据分析能力养成指南05:数据可视化之打造升职加薪的报表
数据分析能力养成指南06:数据可视化之手把手打造BI
数据分析能力养成指南07:快速掌握麦肯锡的分析思维
数据分析能力养成指南08:如何建立数据分析的思维框架?
数据分析能力养成指南09:写给新人的数据库指南
数据分析能力养成指南10:SQL,从入门到熟练
数据分析能力养成指南11:SQL,从熟练到掌握
数据分析能力养成指南12:解锁数据分析的正确姿势(上)
数据分析能力养成指南13:解锁数据分析的正确姿势(下)
数据分析能力养成指南14:概率论的入门指南
数据分析能力养成指南15:读了本文,你就懂了概率分布
数据分析能力养成指南16:数据分析必须懂的假设检验
数据分析能力养成指南17:全面的数据指标分析框架
数据分析能力养成指南18:Python的新手教程
数据分析能力养成指南19:Python的数据结构
数据分析能力养成指南20:了解和掌握Python的函数
数据分析能力养成指南21:Python分析之numpy和pandas入门
数据分析能力养成指南22:用pandas进行数据分析实战
本文由 @秦路 原创发布。未经许可,禁止转载。