AI产品经理必修课:NLP技术原理与应用
-

-
小东邪 这家伙很懒,还没有设置简介...
0 人点赞了该文章 · 149 浏览

本文简单介绍了NLP的主要技术以及应用领域,适合希望成为人工智能产品经理的产品新人阅读。
一、前言
Google 2018年10月11日提出的BERT模型在11个NLP任务上的表现刷新了记录(下图),其中包括斯坦福大学著名的测试Question Answering(SQuAD v1.1),BERT在SQuAD全部两个衡量指标上超越了人类表现。
有人说这是自然语言理解领域几个月来最重大的事件。Google BERT的出现,被一些人认为将改变NLP的研究模式。“这不是NLP的结束,甚至不是结束的开始。这可能是开始的结束。”有人借用丘吉尔的《The End of the Beginning》来形容这一突破的意义。
那么,什么是NLP,NLP又涉及了哪些技术?

图片来源:https://rajpurkar.github.io/SQuAD-explorer/
二、什么是NLP?
1. 什么是语言?
语言是指生物同类之间由于沟通需要而制定的指令系统,语言与逻辑相关,目前只有人类才能使用体系完整的语言进行沟通和思想交流。
2. 什么是自然语言?
自然语言通常会自然地随文化发生演化,英语、汉语、日语都是具体种类的自然语言,这些自然语言履行着语言最原始的作用:人们进行交互和思想交流的媒介性工具。
-
语音:与发音有关的学问,主要在语音技术中发挥作用。
-
音韵:由语音组合起来的读音,即汉语拼音和四声调。
-
词态:封装了可用于自然语言理解的有用信息,其中信息量的大小取决于具体的语言种类。中文没有太多的词态变换,仅存在不同的偏旁,导致出现词的性别转换的情况。
-
句法:主要研究词语如何组成合乎语法的句子,句法提供单词组成句子的约束条件,为语义的合成提供框架。
-
语义和语用:自然语言所包含和表达的意思。
3. 什么是自然语言处理?
自然语言处理(Natural Language Processing,NLP):是计算机科学,人工智能和语言学的交叉领域。目标是让计算机处理或“理解”自然语言,以执行语言翻译和问题回答等任务。
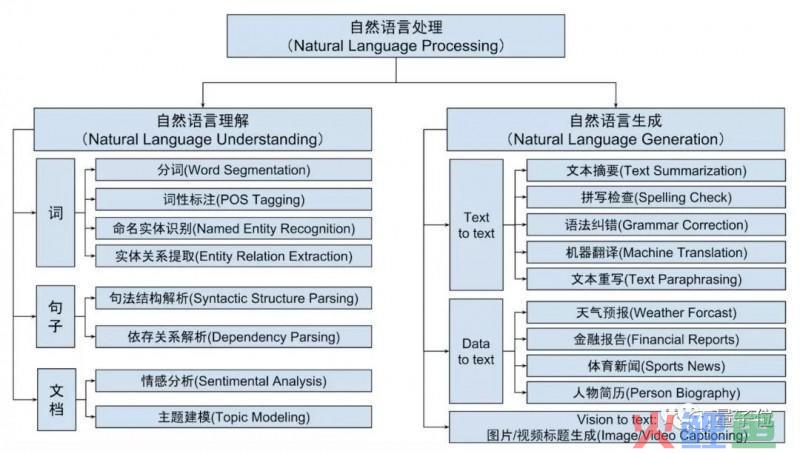
NLP包含自然语言理解(Natural Language Understanding,NLU) 和自然语言生成(Natural Language Generation, NLG)两个重要方向,如下图所示。
-
自然语言理解NLU旨在将人的语言形式转化为机器可理解的、结构化的、完整的语义表示,通俗来讲就是让计算机能够理解和生成人类语言。
-
自然语言生成NLG旨在让机器根据确定的结构化数据、文本、音视频等生成人类可以理解的自然语言形式的文本。
4. 自然语言处理的难度
-
自然语言千变万化,没有固定格式。同样的意思可以使用多种句式来表达,同样的句子调整一个字、调整语调或者调整语序,表达的意思可能相差很多。
-
不断有新的词汇出现,计算机需要不断学习新的词汇。
-
受语音识别准确率的影响。
-
自然语言所表达的语义本身存在一定的不确定性,同一句话在不同场景/语境下的语义可能完全不同。
-
人类讲话时往往出现不流畅、错误、重复等现象,而对机器来说,在它理解一句话时,这句话整体所表达的意思比其中每个词的确切含义更加重要。
三、自然语言理解技术概述
1. 含义
自然语言理解以语言学为基础,融合逻辑学、计算机科学等学科,通过对语法、语义、语用的分析,获取自然语言的语义表示。
2. 自然语言理解技术概述
2.1 基于规则的方法
(1)指利用规则定义如何如何从文本中提取语义。大致思路是人工定义很多语法规则,它们是表达某种特定语义的具体方式,然后自然语言理解模块根据这些规则解析输入该模块的文本。
(2)优点:灵活,可以定义各种各样的规则,而且不依赖训练数据;
(3)缺点:需要大量的、覆盖不同场景的规则,且随着规则数量的增长,对规则进行人工维护的难度也会增加。
(4)结论:只适合用在相对简单的场景,其优势在于可以快速实现一个简单可用的语义理解模块。
2.2 基于统计的方法
(1)通常使用大量的数据训练模型,并使用训练所得的模型执行各种上层语义任务。
(2)优点:数据驱动且健壮性较好;
(3)缺点:训练数据难以获得且模型难以解释和调参;
(4)通常使用数据驱动的方法解决分类和序列标注方法。
2.3 在具体实践中,通常将这两种方法结合起来使用
(1)没有数据及数据较少时先采取基于规则的方法,当数据积累到一定规模时转为使用基于统计的方法。
(2)在一些基于统计的方法可以覆盖绝大多数场景,在一些其覆盖不到的场景中使用基于规则的方法兜底,以此来保证自然语言理解的效果。
2.4 应用
(1)意图识别
-
实质:分类问题
-
输入:句子的文本特征
-
输出:句子文本特征所属的意图分类
-
算法:SVM、AdaBoost算法等
(2)实体抽取
-
实质:序列标注
-
输入:句子的文本特征
-
输出:文本特征中的每个词或每个字属于某一实体的概率
-
算法:隐马尔可夫模型(hidden Markov model,HMM),条件随机场(conditional random field,CRF)
注:当数据量足够大时,使用基于神经网络的深度学习方法处理意图识别和实体抽取任务可以取得更好的效果。
四、自然语言理解基本技术
自然语言理解基本技术分为词法分析、句法分析、语义分析三类。
1. 词法分析
词法分析包括分词和词性标注。
1.1 分词 word segmentation
(1)含义:中文不同于英文,其没有自然分隔符(明显的空格标记),因此汉语自然语言处理的首要工作就是将输入的字串切分为单独的词语。
(2)分词方法:
A、基于词表匹配的方法:会逐字对字符串进行扫描,发现字符串的子串和词表中的词相同就算匹配。
常见方法:有正向最大匹配法、逆向最大匹配法、双向扫描法和逐词遍历法。
常见的基于词表的分词工具:IKAnalyzer、庖丁解牛等。
B、基于统计模型的方法:根据人工标注的词性和统计特征对中文进行建模,通过模型计算各种分词出现的概率,将概率最大的分词结果作为最终结果。
常见算法:HMM、CRF
常见的基于统计模型的分词工具:ICTCLAS、Stanford word segmenter等。深度学习兴起后,长短期记忆网络LSTM结合CRF的方法得到了快速发展。
1.2 词性标注
(1)含义:词性是词语最基础的语法属性之一,因此词性标注Part-Of-Speech Tagging,POS Tagging是词法分析的一部分。
(2)目的是为句子中的每个词赋予一个特定的类别,即为分词结果中的每个单词标注词性。
(3)最重要的词性为名词、动词、形容词和副词。
(4)模型:最初隐马尔可夫、之后最大熵模型、支持向量机模型
(5)两种方法:基于规则的方法、基于统计模型的方法
基于规则的词性标注:兼类词搭配关系和上下文语境建造词类消歧规则;
基于统计模型的词性标注:通过模型计算各类词性出现的概率,将概率最大的词性作为最终结果。
(6)常见方法:结构感知器模型和条件随机场模型。随着深度学习技术的发展,也提出了基于深层神经网络的词性标注方法。
(7)工具:standford log-linear part-of-speech tagger、哈工大的LTP工具等。
2. 句法分析
(1)含义:句法分析syntactic parsing的主要任务是对输入的文本句子(字符串)进行分析以得到句子句法结构syntactic structure。
(2)原因:一方面是nlu任务自身的需求,另一方面可以为其他nlu任务提供支持。
(3)分类:根据句法结构的不同表示形式,任务分为以下3类:
-
依存句法分析dependency syntactic parsing,主要任务是识别句子中词汇之间的相互依存关系。
-
短语结构句法分析phrase-structure syntactic parsing,也称作为分句法分析constituent syntactic parsing,主要任务是识别句子中短语结构和短语之间的层次句法关系。
-
深层文法句法分析,主要任务是利用深层文法,对句子进行深层的句法及语义分析,这些深层文法包括词汇化树邻接文法、词汇功能文法、组合范畴文法等。
3. 语义分析
(1)语义,指的是自然语言所包含的意义,在计算机科学领域,可以将语义理解为数据对应的现实世界中的事物所代表概念的含义。
(2)语义分析semantic analysis,指运用各种机器学习方法,让机器学习与理解一段文本所表示的语义内容。任何对语言的理解都可以归为语义分析的范畴,涉及语言学、计算语言学、人工智能、机器学习,甚至认知语言。
(3)语义分析的最终目的是理解句子表达的真实含义。
-
语义分析在机器翻译任务中有重要应用。
-
基于语义的搜索一直是搜索追求的目标。
-
语义分析是实现大数据的理解与价值发现的有效手段。
五、三种常用的自然语言表示模型
1. 词袋模型,bag of words,BOW
(1)含义:词袋模型认为文档中任意位置出现的任何单词,都与该文档的语义无关。通过词袋模型,一个文档可以转化为一个向量,向量中的每个元素表示词典中相应元素在文档中出现的次数。
(2)优点:便于将源文档模型化。
(3)缺点:并没有表达单词在原来句子中出现的次序。
2. TF-IDF(term frequency-inverse document frequency,词频-逆文档频率)
(1)含义:是一种基于统计的加权方法,常用于信息检索领域,用具体词汇在文档中出现的次数和该词汇在语料中出现的次数两个值评估该词汇对相关文档的重要程度。TF指某词语在该文档中出现的次数,IDF是词语普遍重要性的度量。
(2)用途:常被搜索引擎用来评估文档与用户查询之间的相关程度。
(3)核心思想:在一篇文档中出现频率高且在其他文档中很少出现的词汇有较好的类别区分能力,适用于分档分类。
3. 词嵌入word embedding
(1)用词嵌入表示单词是将深度学习引入自然语言处理的核心技术之一。
(2)来源:欲在自然语言理解领域使用机器学习技术,则需要找到一种合适的、将自然语言数学化的方法。
(3)方法:最初使用独热表示one hot representation,即使用词表大小维度的向量描述单词,每个向量中多数元素为0,只有该词汇在词表中对应位置的维度为1。独热表示难以发现同义、反义等关系。
(4)词嵌入法在基于独热表示法的基本思想的同时,增加了单词间的语义联系,并降低了词向量维度以避免维度灾难。
六、基于知识图谱的自然语言理解
知识图谱是知识表示与推理、数据库、信息检索、自然语言处理等多种技术发展和融合的产物。
更多关于知识图谱的介绍可以查看笔者的另一篇文章:AI产品经理必修课:知识图谱的入门与应用
七、自然语言生成NLG
1. 含义
自然语言生成作为人工智能和计算语言学的分支,其对应的语言生成系统可以被看作基于语言信息处理的计算机模型,该模型从抽象的概念层次开始,通过选择并执行一定的语法和语义规则生成自然语言文本。
2. 自然语言生成和自然语言理解的异同
2.1 差异点:
自然语言理解实际上是被分析的文本的结构和语义逐步清晰的过程;自然语言生成的研究重点是确定哪些内容是满足用户需要必须生成的,哪些内容是冗余的。
2.2 相同点:
(1)二者都需要利用词典;
(2)二者都需要利用语法规则;
(3)二者都要解决指代、省略等语用问题。
3. 两种架构类型
3.1 流线型 pipeline
(1)含义:流线型的自然语言生成系统由几个不同的模块组成,每个模块之间的交互仅限于输入输出,各模块之间不透明、相互独立。
(2)系统架构
流线型的自然语言生成系统包括文本规划、句子规划、句法实现3个模块。文本规划决定说什么,句法实现决定怎么说,句子规划负责让句子更加连贯。
流程:文本规划(交际目的、知识库、规划库、用户模型、话语历史)、话语计划、句子规划(话语历史、句子规划规则)、句子计划、句法实现(语法规则、词典)、文本。
3.2 一体化型integrated
一体化型的自然语言生成系统是相互作用的,当一个模块内部无法作出决策时,后续模块可以参与该模块的决策。
3.3 两类架构的差异
一体化型的自然语言生成系统更符合人脑的思维过程,但是实现较为困难,现实中较常用的是流线型的自然语言生成系统。
4. 两种对话生成技术
4.1 检索式对话生成技术
通过排序技术和深度匹配技术在已有的对话语料库中找到适合当前输入的最佳回复。局限性:仅能以固定的语言模式对用户输入进行回复,而无法实现词语的多样性组合,因此无法满足回复多样性要求。
4.2 生成式对话生成技术
代表性技术是从已有的“人-人”对话中学习语言的组合模式,是在一种类似机器翻译中常用的“编码-解码”的过程中逐字或逐词地生成回复,生成的回复有可能是从未在语料库中出现的、由聊天机器人自己“创造”的句子。
5. 自然语言生成的挑战
涉及文法开发,需要将文法结构和应用特有的语义表征相关联,但由于自然语言中存在海量的文法结构,造成搜索空间巨大,如何避免生成有歧义输出成了一个有挑战的问题。
由于语言的上下文敏感性,生成语言时如何整合包括时间、地点、位置、用户信息等在内的上下文信息也是一个难题。
基于深度学习技术生成回复的对话模型很难解释,也很难被人类理解,只能通过更好的语料和参数调整来改善对话模型。
6. 三种自然语言生成方式
6.1 基于检索的自然语言生成
基于检索的自然语言生成并不是如字面意思一样生成自然语言,更多是在已有的对话语料中检索出合适的回复。
优点:实现相对简单、容易部署美因茨在实际工程中得到了大量的应用。
缺点:依赖于对话库、回复不够灵活等
6.2 基于模板的自然语言生成
自然语言生成模板由句子sentence模板,词汇word模版组成。句子模版包含若干个含有变量的句子,词汇模板则是句子模块中的变量对应的所有可能的值。
6.3 基于深度学习的自然语言生成
八、NLP在聊天机器人中的应用
1. NLP应用概览
NLP作为人工智能的核心技术,在机器翻译、聊天机器人、语音识别等领域都有重要的应用。
机器翻译的代表如科大讯飞的翻译机;聊天机器人例如微软小冰、Amazon Alexa;语音识别如各种智能音箱。

NLP主要应用领域,图片来源:stateoftheart.ai
2. 聊天机器人的分类与应用场景
聊天机器人作为NLP应用的重点产品之一,可以按不同维度进行细分。
基于应用场景的聊天机器人分类:在线客服、娱乐、教育、个人助理、智能问答类。
基于实现方式的聊天机器人分类:检索式和生成式。
基于功能的聊天机器人分类:问答系统、面向任务的对话系统、闲聊系统和主动推荐系统。
3. 聊天机器人系统框架
一个完整聊天机器人的系统架构主要由语言识别、自然语言理解、对话管理、自然语言生成、语音合成等5个部分组成。
自动语音识别automatic speech recognition,ASR,负责将原始的语音信号转换成文本信息。
自然语言理解natural language understanding,NLU,负责将识别到的文本信息转换为机器可以理解的语义表示。
对话管理dialogue management,DM,负责基于当前对话的状态判断系统应该采取怎样的动作。
自然语言生成natural language generation,NLG,负责将系统动作/系统回复转变成自然语言文本。
语音合成text-to-speech,TTS,负责将自然语言文本转变成语音信号输出给用户。
4. 聊天机器人的典型代表
硬件形态:amazon echo、公子小白。
软件形态:Apple Siri、微软小冰、微软cortana、IBM watson、Google Now。
平台:谷歌、微软等公司对外提供聊天机器人框架bot framework,以sdk或saas服务的方式像第三方公司或个人开发者提供可以用于构建特定应用和领域的聊天机器人。代表:amazon Alexa(服务amazon lex)、微软luis with bot(认知服务cognitive services)、谷歌api.ai、Facebook wit.ai。
5. 聊天机器人的技术原理
常见的聊天机器人系统包括问答系统、面向任务的对话系统、闲聊系统、主动推荐系统。
问答系统
QA问答系统偏重于问句分析,旨在获取问句的主题词、问题词、中心动词。主要采取模板匹配和语义理解两种方式。
面向任务的对话系统
通过对话管理(重点)和跟踪当前的对话状态,进而明确用户的目的和需求。聚焦于将用户输入的自然语言映射为用户的意图和相应的槽位值。
闲聊系统
针对用户没有特定目的、没有具体需求情况下的多轮人机对话,重点是对话管理(上下多轮交互)和自然语言理解两个模块。
主动推荐系统
处于起步阶段,是人机自然交互的关键一环,其作用更多是体现聊天机器人的认知能力。
6. 聊天机器人系统中的自然语言理解模块
聊天机器人系统中的自然语言理解模块主要包括:实体识别named entity recognition、用户意图识别、用户情感识别、指代消解、省略恢复、回复确认及拒识判断等。
实体识别:指识别自然语言中具有特定意义的实体,如人名、时间、地名及各种专有名词。
用户意图识别:包括显式意图和隐式意图,前者通常对应一个明确的用户需求,后者较难判断。
情感识别:与用户意图类似,也分为显式和隐式。
指代消解:指聊天主题背景一致的情况下,人们在对话过程中通常会习惯性地使用代词指代出现过的某个实体或事件,或者为了方便表述省略句子部分成分的情况。
省略恢复:自然语言理解模块需要明确代词指代的成分和句子中的省略的成分,唯有如此,聊天机器人才能正确理解用户的输入,给出合乎上下文语义的回复。
回复确认:当用户意图、聊天信息等带有一定的模糊性时,需要聊天机器人主动向用户询问,确认用户的意图。
拒识判断:指聊天机器人系统应当具备一定的拒识能力,主动拒绝识别及回复超出自身理解/回复范围或者涉及敏感话题的用户输入。
参考资料:
1、参考书籍:
《自然语言处理实践—聊天机器人技术原理与应用》,王昊奋,邵浩等
《人工智能产品经理:人机对话系统设计逻辑探究》,朱鹏臻
2、NLP相关重要会议:
ACL、COLING、LREC、AAAI
3、相关网址:
中国科学院计算技术研究所·数字化室&软件室:http://www.nlp.org.cn/
北大计算语言所:http://icl.pku.edu.cn/
麻省理工人工智能实验室:http://www.csail.mit.edu/index.php
哈工大:http://ltp.ai/
复旦知识工厂:http://kw.fudan.edu.cn/
本文由 @Alan 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议
爱盈利-运营小咖秀(www.aiyingli.com) 始终坚持研究分享移动互联网App运营推广经验、策略、全案、渠道等纯干货知识内容;是广大App运营从业者的知识启蒙、成长指导、进阶学习的集聚平台;
想了解更多移动互联网干货知识,请关注微信公众号运营小咖秀(ID: yunyingshow)