我眼中的策略产品经理
-

-
sari 这家伙很懒,还没有设置简介...
0 人点赞了该文章 · 147 浏览

转眼,做策略产品经理已经有190天了。当初想做策略产品经理,一是想了解策略产品经理到底和功能产品经理有什么不同,二是觉得满足个性化需求是未来的趋势。
一、为什么需要策略产品经理
策略产品经理属于产品经理的一个细分工种,为什么会出现这种细分,我理解是因为信息以及用户与信息的交互方式已经发生了天翻地覆的变化。 早期人们只能从报纸,电视,门户等有限媒介获取有限的信息,这个时候信息的生成门槛高,生成速度慢,用户只能在有限的范围内去选择,更多的是通过主动表达的方式去获取新知识(搜索)。随着信息技术的发展,信息的生产成本显著降低,人人都在生成信息,这种爆炸式增加的信息和用户有限的注意力、有限的时间,形成了尖锐的矛盾,用户的需求也由明确需求向更高级的模糊需求转变。同一代人看五六遍西游记的时代已经过去了。 除了用户需求,另一个让个性化推荐快速发展的原因,在于大数据、机器学习、云计算、分布式计算等技术的发展。用户需求,大数据,算法以及计算硬件共同促进了用户需求向个性化的方向前进。二、什么是信息流的策略产品经理
策略产品经理需要解决的核心问题,是人与物(信息)的匹配问题。让用户在有限的碎片化时间里,尽可能多地看到他感兴趣且尽可能有价值的内容。 个性化推荐的效果极强地依赖技术方案,在工作期间,经常会困扰我的一个问题是策略产品经理的价值在哪?不同于功能产品经理,策略产品经理写不出几十页的需求文档,不需要定义清楚每一个按钮的逻辑,每一种交互的边界情况,策略产品经理的价值更多的体现在对用户价值和用户体验的判断。 例如,拿一种新的资源来说,策略产品经理需要思考这类资源对于目标用户有什么价值,目标用户都会满足哪些特征,这种资源用什么样的形式,什么样的比例,什么样的方式出现在用户的信息流中,哪些因素会影响用户的最终体验,怎样衡量最终为用户带来了什么价值等等。 上述这些虽然很多也受制于技术实现方案,但是策略产品经理需要思考清楚以及把控底线。举个极端的例子,纯粹依赖机器和算法进行个性化推荐,最终绝大多数展现的资源都是偏低俗敏感的低价值资源,机器更擅长的是根据用户的行为去迎合用户的喜好,而策略产品经理需要能够从人的角度,去权衡用户喜好和用户价值之间的关系。三、常见的推荐算法
吴军在《智能时代》中说到,解决不确定问题最好的方法是大数据。所谓的不确定性,是指无法用因果关系来描述,根据统计学原理,通过足够多的数据,可以发现其中的相关性,来把握不确定问题的规律。这里值得一提的是,大数据背后代表的是一种思维方式的改变,即解决问题的思路由传统的因果关系代表的确定性思维转向为以大数据为代表的不确定性思维。工业革命代表的确定性思维开始逐渐转变为以大数据为核心的不确定性思维。 为了更简单地了解推荐算法,我们可以将一篇资源X和一个用户Y之间的匹配程度抽象定义为相关系数P,P值越高,代表这个用户对这篇资源的点击欲望越强,P=1代表这个用户一定会点这篇文章,P=0代表这个用户一定不会点这篇文章。推荐算法的本质就是计算这个P值,然后将P值最高的那篇内容推荐给用户。推荐效果好坏的关键取决于P值计算的准确性。根据香农信息熵理论,数据之间的相关性,可以消除噪音,降低信息熵,从而降低不确定性。1、热度算法
顾名思义,按照资源的热度,对资源进行排序。认为热度高的资源,P值越高,用户点击的可能性就越大。实质是利用资源的热度来消除资源和用户匹配的不确定性,热度为500的资源相对于热度100的资源而言,用户点击前者的可能性(概率)更高。 这种算法的优点是,启动成本低,只要定义清楚了热度的计算方法,每篇资源都可以计算出热度值,可以作为冷启动方式,为个性化推荐策略积累数据。自然,这种简单粗暴的方式也会有很多明显的缺点: 1.1、 单篇文章每个用户的P值都是一样的 实际需求中,每个人对热度的定义是不一样。例如:我爱看NBA,那同样是热度500的NBA和美妆的两篇文章,很明显NBA的文章对我来说更热,我点击的可能性更大。 所以在热度算法中,需要考虑一些对用户有价值的因素,以提高P值的准确性。例如,有没有一个初始热度值,初始热度值有没有类别差异?需要找出有价值的信息维度,提高P值的准确度。判断这些信息是否有价值,可以看这个场景是否对于绝大多数的用户都是成立的。 1.2、无法做到个性化推荐 热度算法无法根据用户的兴趣点和行为实现细粒度的个性化推荐。 1.3、对新资源和强时效资源没有保护 新入库的资源由于没有历史数据的累积,很难被展现,需要对新资源制定一些保护策略。尤其对一些强时效的重大事件,可以维系一个热词词典进行提权,如有必要,甚至可以结合人工干预,进行强制展现,以保证快速的时效性要求,例如”九寨沟地震事件”。 1.4、避免滚雪球式的放大效应 热度高的资源会排在前面,得到更多的展现,反过来会进一步提高资源的热度,为了避免这种滚雪球式的马太效应,提高资源时效性的感知,需要对热度进行合理的衰减,衰减趋势应该是越来越快,也就是说用户此时此刻的行为价值最大,一篇资源今天被点击了100次的热度价值高于昨天被点击100次,明显高于前天被点击的100次。2、协同过滤
协同的百科解释是协调两个或者两个以上的不同资源或者个体,协同一致地完成某一目标的过程或能力。我理解协同就是相关熵的概念,利用两个及以上资源(用户)之间的相关性来进行推荐,降低不确定性,提高P值的准确性。目前,常见的协同过滤有三种,基于内容的协同过滤,基于用户的协调过滤和基于模型的协同过滤。 2.1基于内容的协同过滤 基于内容的协同过滤,就是计算内容之间的相似度,将和用户以往喜欢资源相似的资源推荐给该用户,例如下图用户A喜欢资源A、B、C,系统发现资源A和资源D非常相似,就会尝试把资源D推荐给用户A。这是利用两个资源的相似度来降低资源与用户匹配的不确定性程度。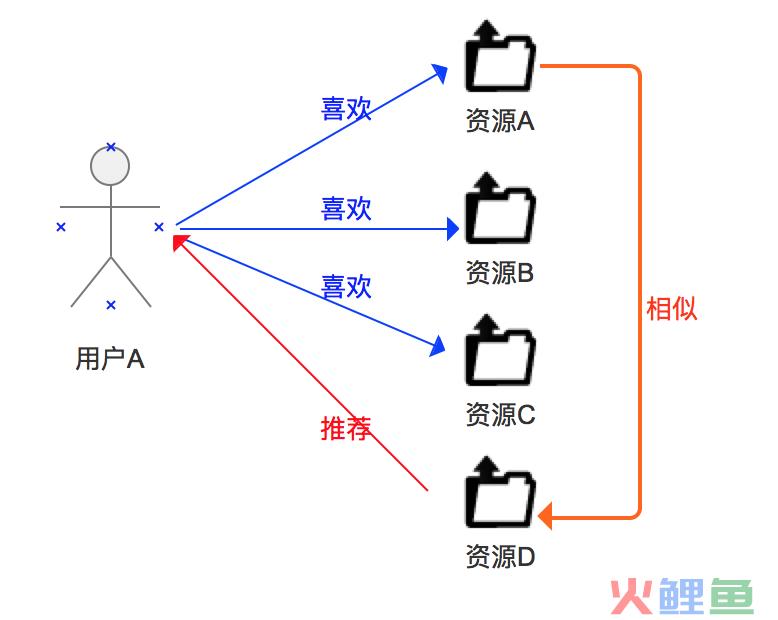
图1 基于内容的协同过滤
2.2基于用户的协同过滤 基于用户的协同过滤,就是计算用户之间的相似度,将与你相似用户所喜欢的内容推荐给你。例如下图,系统发现用户A和用户B是相似用户,就可以将用户A喜欢的资源C推荐给用户B。这是利用相似用户的爱好相似来降低资源与用户匹配的不确定性程度。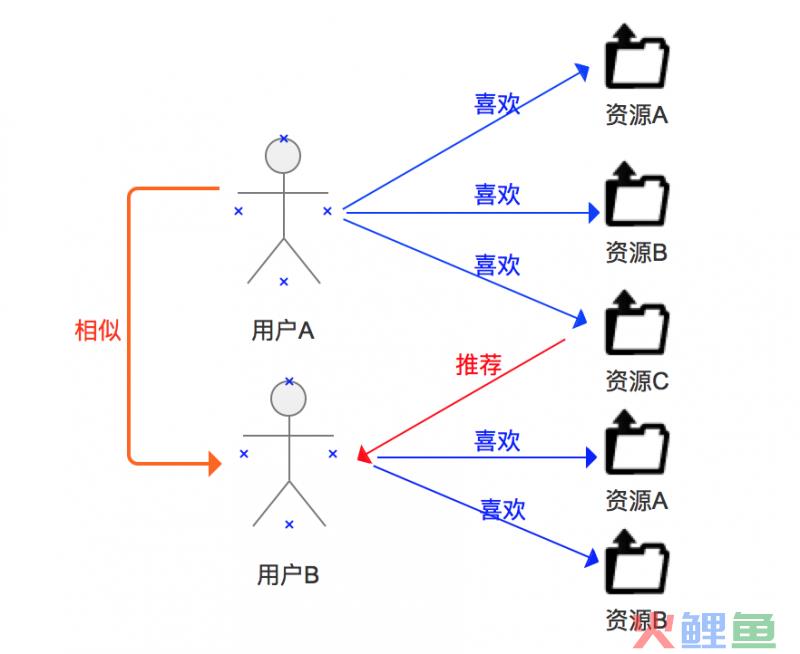
图2 基于用户的协同过滤
2.3基于模型的协同过滤 基于模型的协同过滤就是基于已有的用户与资源之间喜好关系的样本,训练模型,通过该模型计算P值,进行推荐。训练样本越多,有效特征越多(输入的有效信息维度),训练的模型越准确,也就是P值的准确度越高。 基于协同过滤的推荐效果依赖于数据样本的大小,数据维度的多少,以及数据的完备性。一般而言,这些技术方案的实现不需要策略产品经理的参与,但如果可以,其实从数据维度来看,策略产品经理可以从用户需求和场景化的角度,去考虑哪些维度对于用户是有价值的,在什么场景下有价值,价值有多大。