代码级解答-流式数据的处理问题
-

-
tanwc 这家伙很懒,还没有设置简介...
0 人点赞了该文章 · 136 浏览
前言
在普通的数据处理场景中,处理数据很简单啊,因为数据都好好的放在库里,直接select出来就好了。
但是流式数据是一条一条过来的,期间还会因为网络延迟,有些数据还会迟到。这种“数据没排好队”的情况,叫做“乱序”。这可让我们非常麻烦!
我们咋解决呢?来,今天让“中国好胖子”同学给你来一个代码级的解答!乱序
大家知道,所有数据理论上都应该有时间戳,在流式数据中,时间戳更重要。可以说时间戳就是流式数据区别于离线数据的重要标志。
在Flink中,我们大多使用EventTime作为时间戳。当我们用这个时间来参与计算的时候,由于EventTime是真实世界的时间,那么百分之100可能会发生乱序数据。
那么何为乱序数据呢,前面说过了,乱序数据就是迟到的数据。1分钟前产生的数据,1分钟之后才进入到系统中,这就延迟了。
所以那么乱序数据就是在正常的时间数据流中夹杂着一些非顺序的一些数据。
乱序是怎么产生的呢?因素太多了,例如某台机器的网络抖动,或者网卡和系统的延迟,都会导致这台机器上报的数据延迟到达。
那么flink在处理的时候,就可能收到了系统在好几秒之前产生的数据。这个一点非常讨厌,会直接导致实时Join失败。
Flink必须得解决这个问题啊,否则怎么保证迟到的数据都能用上呢,对吧?watermark就是用来解决这个问题的。
Watermark,就是水位线,用来测量乱序数据的进度的。
Flink用watermark来确定这条迟到的数据如何触发计算或者其他操作。嘿嘿,所以Watermark也是一种特殊的数据!
Watermark
单纯的从概念上不好理解,我们先假设一个场景,这样更容易理解这个事情。你最好有一些流失数据的基础,否则不太容易理解这些原理。
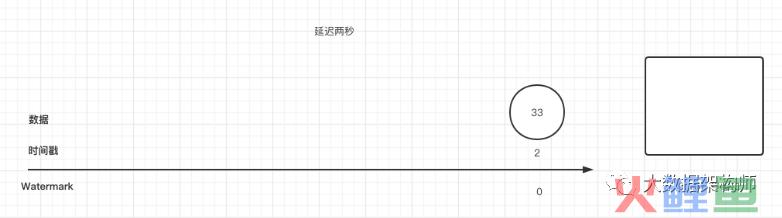
假设,我们有一个5s的窗口,并且我们可以容忍的延迟时间为2s,就是说5秒一计算,允许数据迟到2秒。
那么也就是说,从0开始,在7s的时候会触发一次计算。我画个图解释一下为什么会7s触发计算,或者永不触发。
为了排除其他影响因素,我们假设是单task,单分区的场景。其中的33 是第一条数据, 2 是他携带的时间戳,在右侧有一个5秒的窗口:
那么我们的watermark的计算公式就是 watermark = time - latertime 。那么这个时候我们可以得到这个watermark是0,那么他属于0-5s的窗口,那么我们就放到窗口里面去。
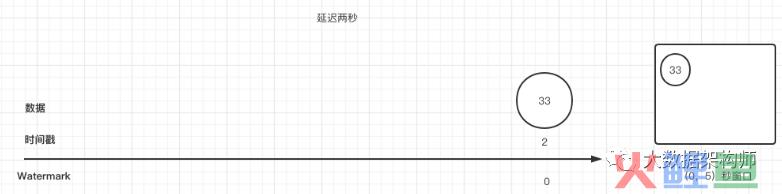
这个时候又来了一条数据,就会变成下面这样对吧,为什么会变成两个窗口呢?
因为99这条数据并不属于0-5秒这个窗口里面,因为flink窗口的大小是包左不包右的,这点很关键。
这样你就能明白,为什么33和99应该各自进到单独的窗口。所以,数据是根据EventTime来决定应该进哪个桶或者说窗口的。
现在你能理解为啥EventTime这么重要了吧?
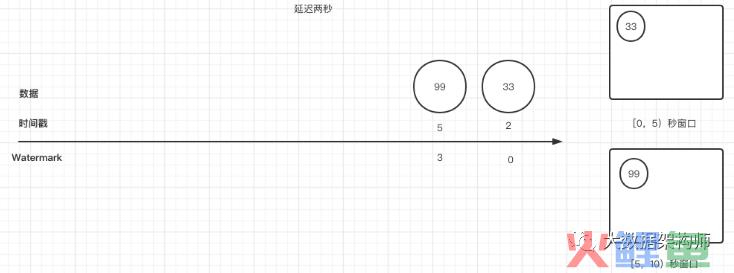
假如,这个时候来了一条乱序数据,23号(时间戳3S),这条数据迟到了,那么我们的watermark怎么更新呢?
现在,请你停下来思考一下,新来的23号数据应该进那个窗口?
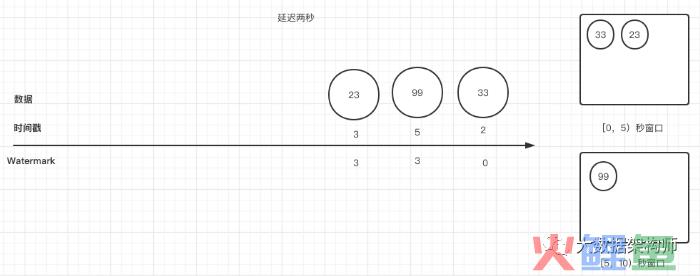
案揭晓:我们可以看到我画的图:其中,23数据携带的时间戳是3,watermark也是3,应该归到[0,5)的窗口。
你是不是会奇怪,这迟到的数据序号比前面的99号序号要大啊,怎么在后面呢,并且计算出来的watermark是3?这不是违背了我们的公式计算规则么?
按照前面的公式,watermark = time - latertime,那么23号的watermark应该是3-2=1,应该排到99号的前面去啊。
其实不是的,watermark首先是时间尺度,然后才是衡量标准。所以watermark 不能倒着走啊,因为他是负责测量数据的时间进度的。
所以他的watermark 并不会按照公式计算,而是采用的上一个数字的watermark,也就是3。
为了让你看的更清楚,我们多插几条数据看看。
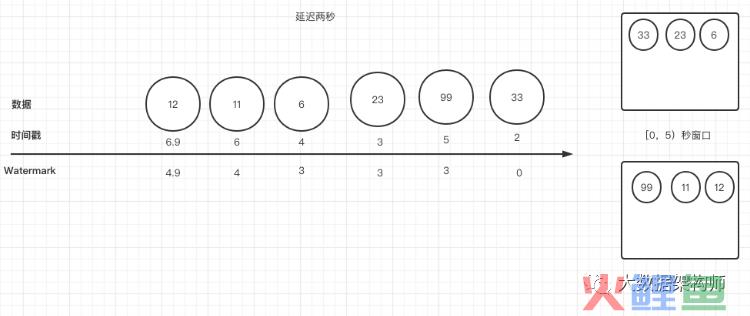
所有数据在watermark上,都是顺序排列的,6号数据的watermark,按照公式,应该是4-2=2,但是很遗憾,前面已经有3了,所以只能排在3后面。谁让你迟到了呢,对吧?
当然,这个时候他们只是在排队,还没有触发窗口的计算操作。
那么窗口计算什么时候触发呢?很简单,当watermark大于等于窗口触发时间。
第一个窗口触发计算操作的时间也就是大于等于5秒的时候。
提问:第二个窗口出发计算操作的时间是什么时候呢?
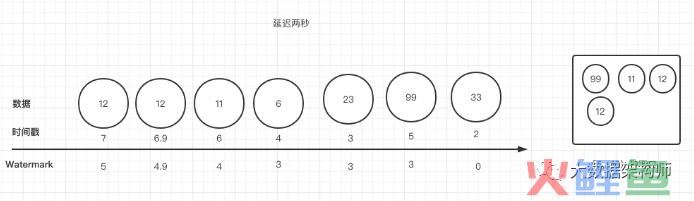
答案是10秒。
那么我们讲到这里,应该大部分人都能够了解到了watermark的运行机制,以及窗口什么时候计算。
现在还是一条线的情况。现实情况比这个要复杂的多的多。
那么我们接下来就来考虑一下我们的多并行度下,我们的watermark如何传递?
传递
我们应该知道 在一个 task中有很多的subtask,那么这些subtask都有自己的watermark。
所有的数据时间上都应该同步啊,要不然怎么多并行度计算啊?就全乱套了。
所以这个时候就会涉及到 watermark的传递,因为下游也是依赖这些watermark的。
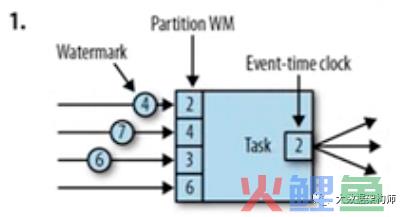
如上图所示,我们可以看到Watermark在顺序的向下游流动,左侧的向右箭头,就是这个意思。
那么我们这个时候发现有一个Partition WM 这个其实就是各个分区的 SubTask的Watermark。
我这个时候发现,每个subtask的watermark都是不一样的,并且task会存储这些watermark,记录下来各个分区的watermark,并且把最小的watermark广播出去。
当前需要记录的是2、4、3、6号watermark,其中2是最小的,好,我们记下来。
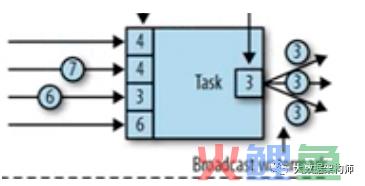
这个时候当传递过来的4号watermark更新了,把原来的2给顶走了。那么现在是4、4、3、6,最小的是3了。这个时候我们就将最小的3作为watermark传递出去。
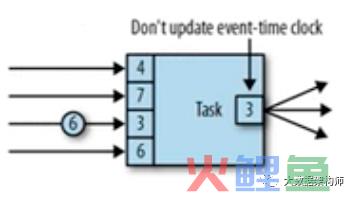
当7传递过来的时候,我们就会发现,传递过去的依然是最小的3,所以不动。
这样,我们就能解决多并行度下,watermark的传递问题。其实就是挑一个最小的watermark放出去。
你现在对watermark的机制应该是比较了解的吧?
咋用?
现在开始上代码!
1、常见用法
WatermarkStrategy .怎么样?简单吗?哈哈哈!所以不要以为Flink很难!越高级的语言,其实越简单。只是理解起来比较费劲而已。
2、WatermarkGenerator
/** * {@code WatermarkGenerator} 可以基于事件或者周期性的生成 watermark。 * *注意: WatermarkGenerator 将以前互相独立的 {@code AssignerWithPunctuatedWatermarks} * 和 {@code AssignerWithPeriodicWatermarks} 一同包含了进来。 */@Publicpublic interface WatermarkGenerator { /** * 每来一条事件数据调用一次,可以检查或者记录事件的时间戳,或者也可以基于事件数据本身去生成 watermark。 */ void onEvent(T event, long eventTimestamp, WatermarkOutput output); /** * 周期性的调用,也许会生成新的 watermark,也许不会。 * *
调用此方法生成 watermark 的间隔时间由 {@link ExecutionConfig#getAutoWatermarkInterval()} 决定。 */ void onPeriodicEmit(WatermarkOutput output);}
3、watermark 分区数据倾斜解决方案
在数据源直接使用时如果因为数据源中的某一个分区/分片在一段时间内未发送事件数据,则意味着watermarkStrategy也不会获得任何数据去生成watermark,在这种情况下可以通过设置有一个空闲时间,当超过这个时间则将这个分片或分区标记为空闲状态。
WatermarkStrategy
.
结语
Flink的很多设计都非常精巧,watermark就是其中之一。我们研究这些实现原理并不是想做源码级的开发,而是欣赏这种精妙的思想,真是为之叹息。
如果你觉得有启发,欢迎留言,一起交流。
-END-