产品经理一定要了解的数仓知识
-

-
我怕谁 这家伙很懒,还没有设置简介...
0 人点赞了该文章 · 136 浏览

做产品经理一定会或多或少的负责产品的数据板块工作,从基础的数据埋点到数据看板、到数据报表产品设计,以至于后面数据平台产品设计。
产品经理都需要了解数据知识,尤其是数仓和数据库的知识是非常重要的。
数据库和数仓的关系有点像:咖啡厅和星巴克的关系。两者其实是息息相关的。不过对于很多互联网公司早期都会在这方面投入资源和精力。
传统的业务数据库已经能够支持,比如以PMTalk为例:
一阶段:公司刚起步,有了基础的网站和电商购买入口;只需要提供数据库、和服务器单机配置,用户能够保证购买成功即可。
对于管理者和运营来说,关心的是下单量总和、库存情况。
二阶段:随着时间和运营策略,流量越来越多。以及提供的商品越来越多,从基础性能上查询数据变得成本越来越高,同事数据颗粒度越来越粗,不能够回答出:“28女性用户会在什么时间段下单购买什么样的商品“这样的答案
三阶段:为了解决上面需求,开始提供精细化运营的数据支持。关注的问题也不再是只有总订单、总营业额,还要关注具体各个商品库存、商品退换货情况等,同时还要预测未来的订单峰值,对用户画像下的用户做商品推荐。
上面3个阶段,从简单的数据获取、到数据运营最后到数据挖掘,这都离不开数仓工作。
01 数据库和数仓的关系
数据库是存储数据以及具体开发工作中使用的工具,比较受欢迎的数据库有:MySQL,Oracle,SqlServer等。工作里体现的都是关系型数据库,比如我们在美团购买电影票产生的电影票支付信息、和购票记录,就是购买操作下产生的数据。
而我们在支付宝里查询的年度账单,就包含了多个维度数据,和用户业务操作没关系,是多个数据的汇总,就叫做OLAP(联机分析处理)
上面是关系数据库,在开发过程中为了方便管理,会利用面向对象的概念建里数据库表单,对象与对象之间是独立的。
但数据库是存储元数据的地方,元数据包含了业务元数据(比如订单、交易、社区发帖量)还有技术元数据(日志、埋点)等2个维度。
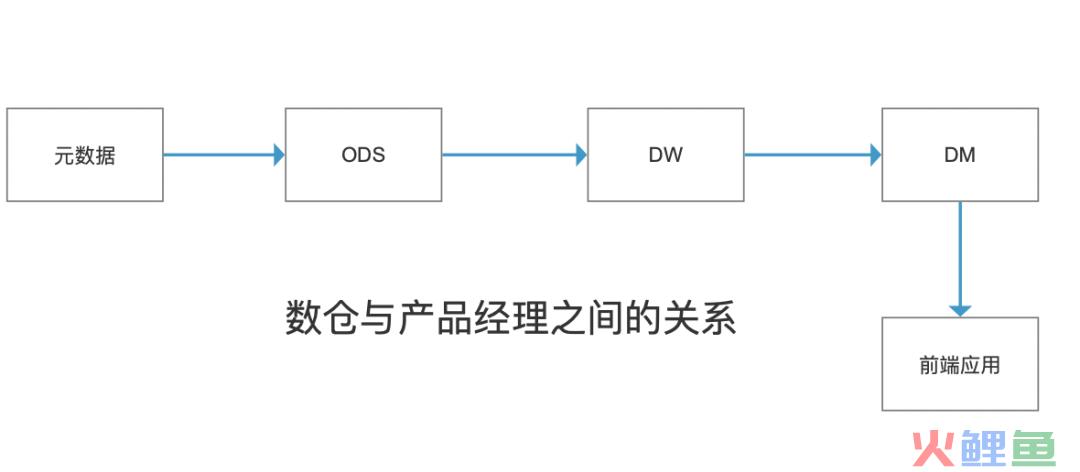
经过下面的流程,一个数仓才是算搭建完成,同时产品经理要了解前端应用(背后数仓原理)来完成数据报表、数据产品的设计
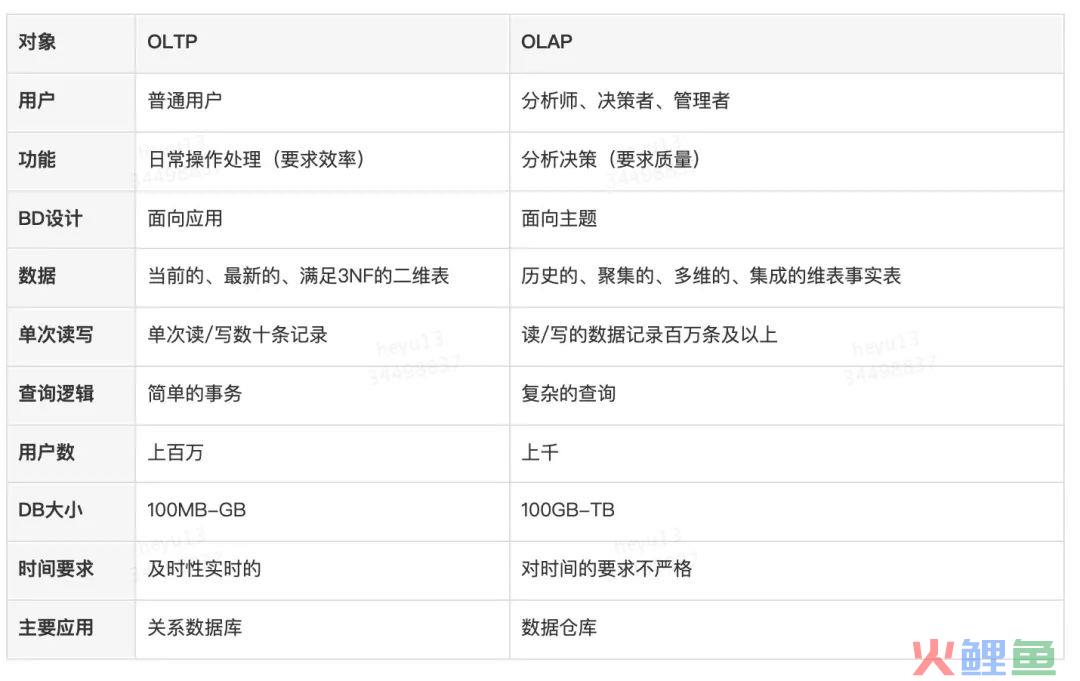
在开始了解数据仓库之前,我们数据处理的分类大致可以分成两大类:OLTP(联机事务处理)和OLAP(联机分析处理)。
OLTP(联机事务处理)就是操作型数据库的主要应用,更侧重于基本的、日常的事务处理,包括数据的增删改查。
OLAP(联机分析处理)就是分析型数据库的主要应用,以多维度的方式分析数据, 这个后续会整理。
两者的关系对比和区别,我在网上收集到一张图。可以查看两者的区别和优势,在开发层面上OL TP是至关重要的,方便了开发的读写操作,减少了数据的冗余。
比如下面就是数据库关系数据库和数仓下的数据库表单
基于书下的属性建立的数据表单,比如书的作者、书的分类、书的出版编号。各自属性都是独立管理,方便开发者进行单独属性的读写操作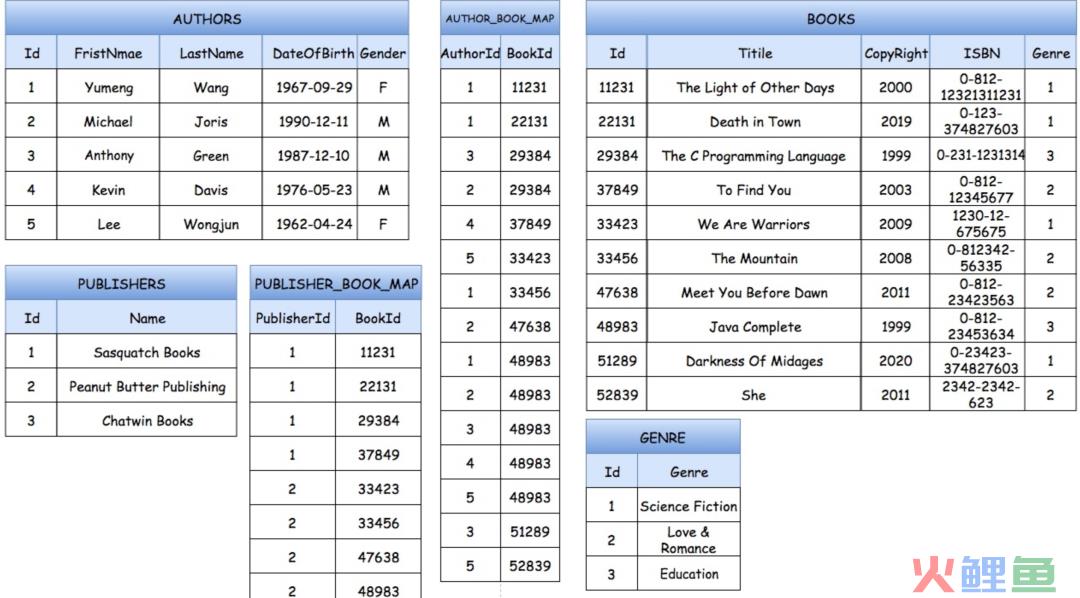 而基于分析查询的数据库,则会把若干的数据库合并为一张表。虽然有冗余数据,但至少在查询的效率会比前者更快。在一张表里就可以查询到所需要的数据
而基于分析查询的数据库,则会把若干的数据库合并为一张表。虽然有冗余数据,但至少在查询的效率会比前者更快。在一张表里就可以查询到所需要的数据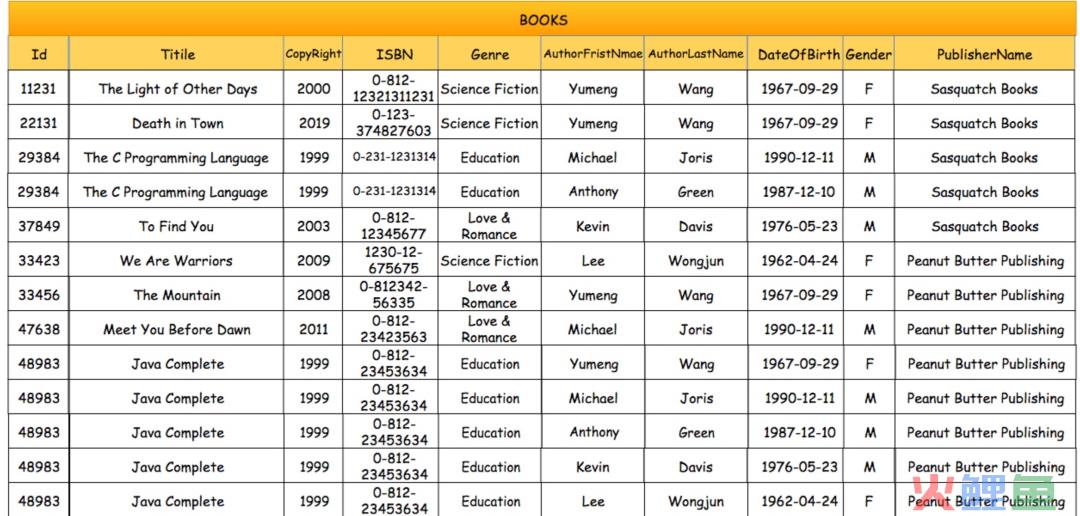
02 数据仓库是什么
数仓也是数据库的一种形态,但以面向分析的存储系统。
也就是说数仓是存数据的,企业的各种数据往里面塞,主要目的是为了有效分析数据,后续会基于它产出供分析挖掘的数据,或者数据应用需要的数。
在数仓里,会分为4个层面。从基础设施到应用层分别为:
数据源:数据来源,比如埋点采集,客户上报,API等、或自由服务数据。
ODS层:数据仓库源头系统的数据表通常会原封不动地存储一份,这称为ODS层, ODS层也经常会被称为准备区。ODS会做一些简单的ETL,但属于数据共享区为接下来的DW和DM提供所需要的数据源。
DW层:数据仓库明细层和数据仓库汇总层是数据仓库的主题内容。这一层的数据经过了ETL后变成了可以用的分析数据,通过维度、事件搭建的数据模型,成了DM前一环节。
DWS层(前端应用层):应用层汇总层,主要是将DWD和DWS的明细数据在hadoop平台进行汇总,然后将产生的结果同步到DWS数据库,提供给各个应用。
03 数据库为数据分析提供的4类数据源
在DW层面里,各种数据源中采集和存储到数据存储上,期间有可能会做一些ETL操作。数据源种类可以有多种,分为下面4类:
日志:所占份额最大,存储在备份服务器上;
业务数据库:如Mysql、Oracle等数据;
来自HTTP/FTP的数据:合作伙伴提供的接口;
其他数据源:如Excel等或手工录入的数据。
从数据源到DW的过程前,还有一个ODS过程。汇聚了各种数据源进行存储。经过ETL后才会走进DW流程。
ETL分别代表:抽取extraction、转换transformation、加载load。
(1)抽取(Extract)
从数据来源提取指定数据,数据是需要指定的,不是所有的数据都要抽取过来, 某些源数据对于分析而言没有价值,或者其可能产生的价值,远低于储存这些数据所需要的数据仓库的实现和性能上的成本,就不会抽取了。
(2)转换(Transform)
将数据转换为指定格式并进行数据清洗保证数据质量。
数据清洗,如会对不完整数据,错误数据和重复数据等脏数据进行清洗。
(3)加载(Load)
将转换过后的数据加载到目标数据仓库,加载可分为两种:
全量加载:一次对全部数据进行加载。
增量加载:一般首次需要全量加载,但是在第二次周期或者第三次周期的时候仍然全量加载的话,耗费了极大的物理和时间资源。
以上抽取、转化、加载ETL的实践具体可以用下面4个案例:
空值处理:将空值替换为特定值或直接过滤掉;
验证数据正确性:把不符合业务含义的数据做统一处理;
规范数据格式:比如把所有日期都规范成YYYY-MM-DD的格式;
数据转码:把一个源数据中用编码表示的字段通过关联编码表转换成代表其真实意义的值;
数据标准统一:比如在源数据中表示男女的方式有很多种,在抽取的时候直接根据模型中定义的值做转化。
对于产品经理来说,要知道ETL其实是整个数据分析、数仓搭建最费时间的过程。首先要做数据源的收集、同时还要收集并制定各个业务方的数据需求和指标。
数据仓库有AWS,Hive等
04 数仓和产品经理之间的关系
有了上面的数仓了解和数据指标,接下来产品经理要为运营、管理者等用户提供一套可以查询数据、以及基于数据挖掘获得的数据预测建议。这些以前端展示,应用工具主要就是和数据仓库不同环节的数据交互,这些应用一般可以分为4类:
数据查询和报表工具
BI即席分析工具
数据挖掘工具
各种基于数据仓库或数据集市的应用开发工具
针对数据挖掘要说明下:
数据挖掘是为管理者提供预判建议,比如618活动、双12活动应该上架什么商品、某地区用户应该开展什么样的商品活动,实际上就是数据挖掘的深度应用。
-END-