五步掌握主成分分析法——数据运营必看
-

-
kelisi 这家伙很懒,还没有设置简介...
0 人点赞了该文章 · 132 浏览

本文的目的是为主成分分析(PCA)提供一个完整且简单的解释,特别是其运作方式,以增进大家对该分析法的理解并加以利用,而不必具有强大的数学背景。
PCA实际上是网上广泛提及的一种方法,很多文章都有涉及。但是,只有极少数文章能直接切入主题,并在不过多钻研技术细节的前提下解释PCA的工作原理以及“为什么”。这就是这篇文章的目的:以更简单的方式解释主成分分析法。
在开始解释之前,本文提供了PCA在每一步骤的运作原理的逻辑解释,简化了其背后的数学概念,如标准化,协方差,特征向量和特征值,而暂未关注如何运算的问题。
什么是PCA?
PCA是一种常用于减少大数据集维数的降维方法,把大变量集转换为仍包含大变量集中大部分信息的较小变量集。
减少数据集的变量数量,自然是以牺牲精度为代价的,降维的好处是以略低的精度换取简便。因为较小的数据集更易于探索和可视化,并且使机器学习算法更容易和更快地分析数据,而不需处理无关变量。
总而言之,PCA的概念很简单——减少数据集的变量数量,同时保留尽可能多的信息。
逐步解释
第1步:标准化
这一步的目的是把输入数据集变量的范围标准化,以使它们中的每一个均可大致成比例地分析。
更具体地说,在使用PCA之前必须标准化数据的原因是PCA对初始变量的方差非常敏感。也就是说,如果初始变量的范围之间存在较大差异,那么范围较大的变量将占据范围较小的变量(例如,范围介于0和100之间的变量将占据0到1之间的变量),这将导致主成分的偏差。因此,将数据转换为可比较的比例可避免此问题。
在数学上,这一步可以通过减去平均值,再除以每个变量值的标准偏差来完成。
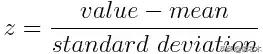
只要标准化完成后,所有变量都将转换为相同的范围[0,1]。
第2步:协方差矩阵计算
这一步的目的是:了解输入数据集的变量是如何相对于平均值变化的。或者换句话说,是为了查看它们之间是否存在任何关系。因为有时候,变量间高度相关是因为它们包含大量的信息。因此,为了识别这些相关性,我们进行协方差矩阵计算。
协方差矩阵是p×p对称矩阵(其中p是维数),其所有可能的初始变量与相关联的协方差作为条目。例如,对于具有3个变量x,y和z的三维数据集,协方差矩阵是以下的3×3矩阵:
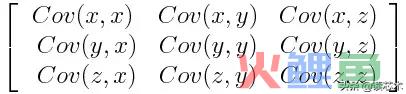
由于变量与其自身的协方差是其方差(Cov(a,a)= Var(a)),因此在主对角线(左上角到右下角)中,实际上有每个起始变量的方差。并且由于协方差是可交换的(Cov(a,b)= Cov(b,a)),协方差矩阵的条目相对于主对角线是对称的,这意味着上三角形部分和下三角形部分是相等的。
作为矩阵条目的协方差告诉我们变量之间的相关性是什么呢?
协方差的重要标志如下:
· 如果为正,则两个变量同时增加或减少(相关)
· 如果为负,则一个减少,另一个增加(不相关)
好了,现在我们知道协方差矩阵只不过是一个表,汇总了所有可能配对的变量间相关性。让我们继续下一步。
第3步:计算协方差矩阵的特征向量和特征值,用以识别主成分
特征向量和特征值都是线性代数概念,需要从协方差矩阵计算得出,以便确定数据的主成分。开始解释这些概念之前,让我们首先理解主成分的含义。
主成分是由初始变量的线性组合或混合构成的新变量。该组合中新变量(如主成分)之间彼此不相关,且大部分初始变量都被压缩进首个成分中。所以,10维数据会显示10个主成分,但是PCA试图在第一个成分中得到尽可能多的信息,然后在第二个成分中得到尽可能多的剩余信息,以此类推。
例如,假设你有一个10维数据,你最终将得到的内容如下面的屏幕图所示,其中第一个主成分包含原始数据集的大部分信息,而最后一个主成分只包含其中的很少部分。因此,以这种方式组织信息,可以在不丢失太多信息的情况下减少维度,而这需要丢弃携带较少信息的成分。
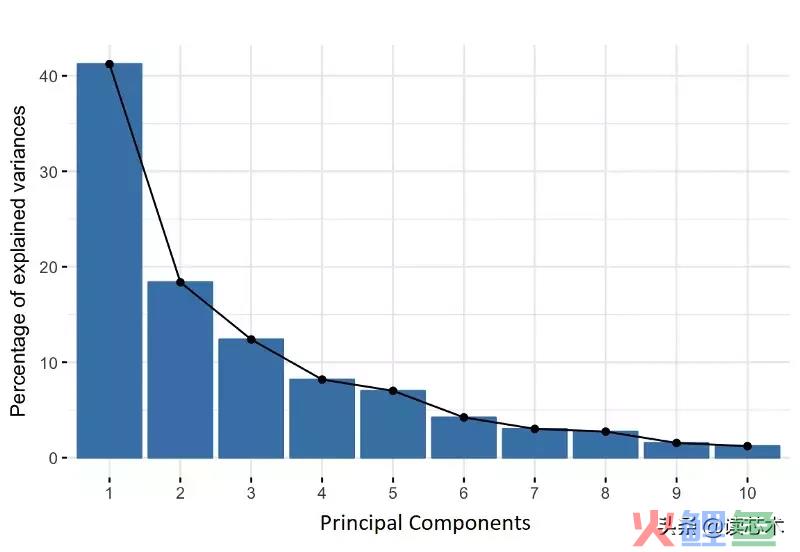
要认识到一件重要的事情是,既然新变量被构造为初始变量的线性组合,它们将更加难以解释,并且对我们没有任何实际意义。
从几何学上讲,主成分代表了解释最大方差量的数据方向,也就是说,它们是捕获数据中大部分信息的线。在这里,方差和信息间的关系是,线所承载的方差越大,数据点沿着它的分散也越大,沿着线的散点越多,它所携带的信息也越多。简单地说,只要把主成分看作是提供最佳角度来观察和评估数据的新轴,这样观测结果之间的差异就会更明显。
PCA如何构建主成分?
由于主成分的数量,如同数据中存在的变量一样多,因此主成分根据第一主成分占数据集中最大可能方差的方式进行构造。例如,假设我们的数据集的散点图如下所示,可以猜出第一个主成分吗?是的,就是大致与紫色标记匹配的线。因为它穿过原点,并且它是点(红点)的投影最分散的线。或者从数学上来讲,它是方差最大化的线(从投影点(红点)到原点的平方距离的平均值)。
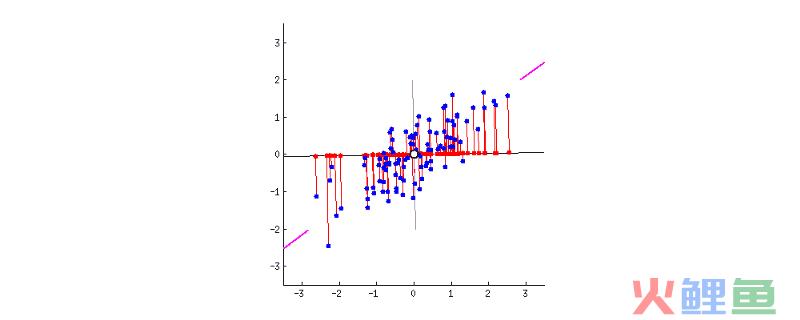
第二主成分以相同的方式计算,条件是它与第一主成分并不相关(即垂直),并且它占第二高方差。
直到计算出p个主成分数量,等于原始变量数。
现在我们理解了主成分的含义,让我们回到特征向量和特征值。首先,你需要知道的是它们总是成对出现,因此每个特征向量都有一个特征值,它们的数量等于数据的维数。例如,对于三维数据集,存在3个变量,因此存在3个具有对应特征值的特征向量。
不用多说,上面解释的所有“魔法”都是特征向量和特征值,因为协方差矩阵的特征向量实际上是方差最多的轴的方向(或最多的信息),我们称之为主成分。并且,特征值只是附加到特征向量上的系数,它们给出了每个主成分中携带的方差量。
通过特征值的顺序对特征向量进行排序,从最高到最低,你就得到了按重要性排序的主成分。
举例:
假设我们的数据集是2维的,有2个变量x,y,并且协方差矩阵的特征向量和特征值如下:
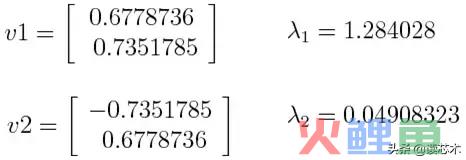
如果我们按降序对特征值进行排序,则得到λ1>λ2,这意味着与第一主成分(PC1)对应的特征向量是v1,而与第二成分(PC2)对应的特征向量是v2。
在有了主成分之后,为了计算每个成分所占的方差(信息)百分比,我们将每个成分的特征值除以特征值的总和。如果我们把这个计算法应用到上面的例子中,我们会发现,PC1和PC2分别携带了96%和4%的数据方差。
第4步:特征向量
正如我们在上一步中所看到的,计算特征向量并按其特征值依降序排列,使我们能够按重要性顺序找到主成分。在这个步骤中我们要做的,是选择保留所有成分还是丢弃那些重要性较低的成分(低特征值),并与其他成分形成一个向量矩阵,我们称之为特征向量。
因此,特征向量只是一个矩阵,其中包含我们决定保留的成分的特征向量作为列。这是降维的第一步,因为如果我们选择只保留n个特征向量(分量)中的p个,则最终数据集将只有p维。
举例:
接着上一步的例子,我们可以用v1或v2向量来形成一个特征向量。
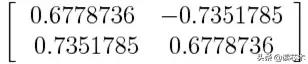
或者丢弃重要性较小的向量v2,仅用v1形成一个特征向量。

丢弃特征向量v2将使维数减少1,并且将导致最终数据集中的信息丢失。 但鉴于v2仅携带4%的信息,因此损失并不重要,我们仍将拥有v1所携带的96%的信息。
因此,正如我们在例子中看到的那样,你可以选择是保留所有成分还是丢弃不重要的成分,具体取决于你要查找的内容。如果你不追求降维,只是想利用不相关的新变量(主成分)描述你的数据,则不需要保留重要性较次的成分。
最后一步:沿主成分轴重新绘制数据
在前面的步骤中,除了标准化之外,你不需要更改任何数据,只需选择主成分,形成特征向量,但输入数据集时要始终与原始轴统一(即初始变量)。
这一步,也是最后一步,目标是使用协方差矩阵的特征向量去形成新特征向量,将数据从原始轴重新定位到由主成分轴中(因此称为主成分分析)。这可以通过将原始数据集的转置乘以特征向量的转置来完成。