【推荐收藏】8种推荐算法对比详解
-

-
咏诗 这家伙很懒,还没有设置简介...
0 人点赞了该文章 · 142 浏览

我们身处被“投喂”的世界。
你看到的,都是别人想让你看到的。
我们知道自己想要什么,但一切满足需求的方案都是被推荐的,不管在哪个触点上和用户交互,都充满了推荐机制。
今天和大家聊一下8种推荐算法机制的相关内容。
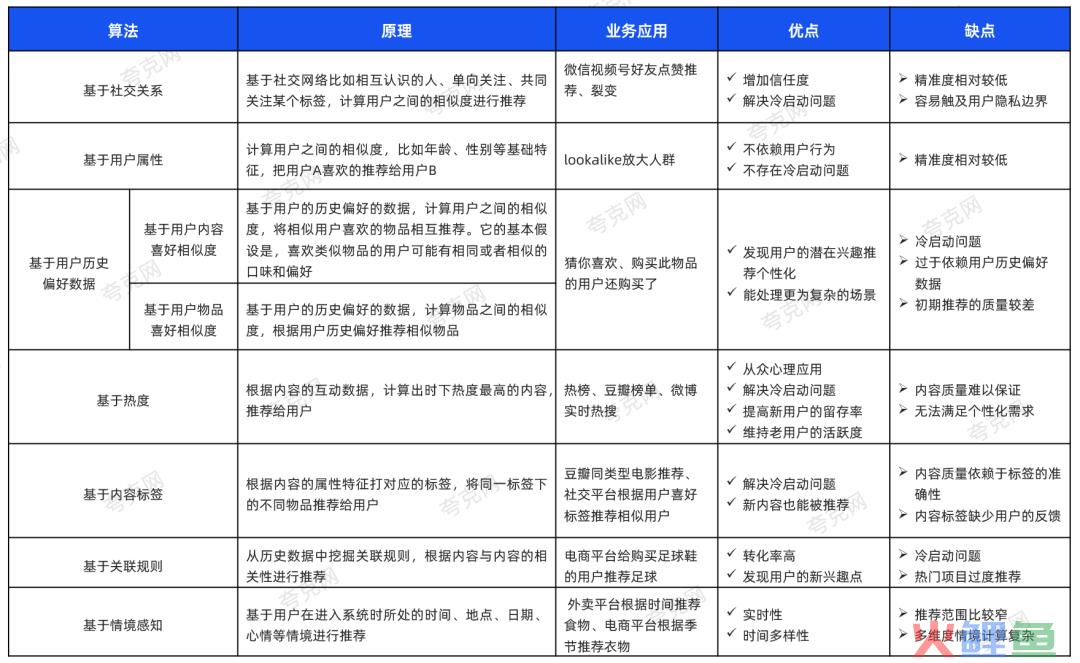
大体上分为两类:基于人(ID)和基于物(内容和商品),文末有8种算法的原理、应用场景和优缺点对比总结表格,供大家参考。
基于人(ID)的四种推荐算法:基于社交关系、基于用户静态属性、基于用户相似度和基于物品相似度;
基于物(内容和商品)的四种是:基于内容热度、内容标签、关联规则和情境感知。

基于社交关系
首先来说说基于社交关系的推荐算法,其本质是基于用户的社交关系数据,比如你在刷视频号的时候,系统会给你推送好友在看的直播、或者是好友点赞的视频。
此外,在微信的“发现”界面中有一个“看一看”模块,里面的内容同样是基于社交关系进行推荐的,当你的朋友阅读公众号文章后,点击了在看,你就会在看一看中的“朋友在看”板块下,看到朋友“在看”的文章。
再举个例子,腾讯QQ在添加好友的时候,往往会给用户推送“可能认识的人”,而“可能认识的人”则是来源于好友的好友,也就是跟用户有共同好友的人有可能会被推荐。
优点:
基于社交关系的推荐效果一般会比较好,因为用户与好友有共同兴趣的可能性比较大。
还有个好处是用户对推荐内容的信任度相对来说会比较高,比如说豆瓣评分中会显示用户关注的人对内容的评分,这样用户在看评分时就有了一个相对可信的参照。
其次是能够解决冷启动的问题,比如抖音登录时,在用户允许APP查看通讯录的情况下,抖音就会给用户推荐通讯录好友的抖音动态,这样新用户在第一次使用APP时,相对来说就有了感兴趣的内容观看。
缺点:
但基于社交关系的推荐算法也有相应的缺点。在有些情况下,推荐的内容精准度有可能变低。
比如说在视频号中,父母点赞的一些内容与年轻人的兴趣则不在一个范畴,甚至不在一个圈层,因此基于这类社交关系推荐的内容,有时并不一定是用户感兴趣的内容。但如果你是想了解父母对什么内容感兴趣,这种推荐对你来说是个不错的功能。
此外还存在一个用户隐私边界的问题,例如用户觉得某个视频很好,想点赞,但又不愿好友看到自己点赞了什么视频,因此用户就可能会选择不点赞,所以基于社交数据的推荐有,可能触及用户的隐私边界。

基于用户静态属性
第二个要介绍的是基于用户静态属性的推荐算法。比如说新用户首次使用微信读书app时,系统会根据用户性别推荐不同类型的书籍,针对男性用户多是武侠小说类书籍,而女性用户则多是文艺类书籍。
简单来说就是基于用户的一些基础特征,比如性别,地区,年龄等静态属性。给用户打上标签,针对用户的标签推荐相应的一些内容。
优点:
基于用户静态属性的推荐,优点是不存在冷启动问题,就算没有新用户的历史行为数据,也可以按用户的静态属性标签推荐相应的内容,而不会过多依赖新用户的行为数据。
缺点:
但是缺点也比较明显,一是精准度相对较低,有时基础特征相似的用户喜欢的内容不一定相同,因此推荐的内容就不一定是用户感兴趣的。
二是属性标签过于简单,仅包含了静态的基础特征属性,而用户的喜好是动态的,不断在发生变化,因此这种算法无法及时地推荐用户喜欢的内容。那么有没有基于动态特征的算法,推荐用户更有可能喜欢的内容呢?
下面我们要说的第三种跟第四种算法相对就更灵活、更精准,分别是基于用户相似度和基于物品相似度的两种推荐算法,它们本质上都是基于用户历史偏好数据。

基于用户相似度
首先我们来说说基于用户相似度的算法,与基于用户属性最大的区别就是,增加了用户的动态属性,需要利用到用户的历史偏好数据,而不仅是静态特征。
举个例子,在电商平台上,小明购买了钢笔和书,小红购买了钢笔、书还有笔记本,小刚则购买了球鞋。根据他们的历史购买数据可以判断小明和小红的偏好较为相似,那么就可以推断出小明也可能喜欢或者需要笔记本,因此将笔记本这类商品推荐给小明,小明对笔记本就更有可能产生偏好。

基于物品相似度
而基于物品相似度的算法同理,根据众多用户的历史行为数据,判断物品与物品的相似度,将若干个相似度高的物品推荐给用户。虽然这种算法计算的是物品相似度,但本质上依然是基于用户的历史偏好数据。
比如前两天我在京东搜索了数字营销书籍这个关键词,后来系统就给我推荐了这本《数据赋能》,其中的原理是,不少购买过数字营销相关书籍的用户,也买了这本《数据赋能》,基于用户历史数据,算法推测出《数据赋能》与那些数字营销书籍有较高的相似度,因此系统将这本书给用户进行推荐。我买了之后发现这本书确实很好,干货与案例并存,了解数字化转型必备。
优点:
可见基于历史偏好数据的这两种推荐算法,优点都是更加个性化、能够处理更复杂的场景,而不仅仅只是基于简单的性别、年龄等静态属性。
并且还能很好地支持用户发现潜在的兴趣偏好,比如我在淘宝购物时,我本来只想买件衬衫,而算法基于其他相似用户的购买数据,给我推荐其他用户买来搭配衬衫的裤子,那么我就有可能同样喜欢这样的搭配,并产生更进一步的购买行为。
缺点:
但这两种算法相应的缺点是,新用户或者新物品会遇到“冷启动”问题,比如电商平台中,用户在没有产生购买行为时,系统就无法基于用户的历史偏好数据来进行推荐。
此外这种算法推荐的质量还依赖于用户历史偏好数据的多少,数据越多准确性相对越高,因此在初期,系统推荐的质量则比较差,不够精准。

基于热度
首先介绍基于热度的推荐算法,这种算法的原理是根据内容的互动数据,计算出时下热度最高的内容并推荐给用户。计算热度的维度可以是时间、内容访问量、用户对内容的评分等维度。
比如微博热搜就是典型的基于热度推荐,在时间维度的基础上,根据内容的访问量得出实时的最热榜单。此外,一些影评类、视频类网站也会使用热榜来给用户进行推荐,比如豆瓣就会按评分得出好评榜单。
优点:
这种推荐算法的优点在于不依赖用户的历史数据,对新用户也可以进行推荐,甚至可以通过一些高质量榜单吸引新用户,比如摄影图片类网站给新用户推送时下热度最高的内容,可以大概率满足用户需求,提高新用户的留存率。
其次对于一些网站、App来说,不断更新的热点能够维持老用户的活跃度,老用户可以高效地获取头部内容,比如吃瓜群众第一时间在微博、豆瓣上看娱乐八卦。
缺点:
而缺点则是热度高的内容不一定是高质量内容,就像微博明星热搜,有时也可能是粉丝刷的,或者是明星自己花钱买的。
此外因为是基于热度的推荐,因此推荐的内容就不一定能满足用户个性化需求,甚至用户喜欢的一些小众内容,往往无法被推荐给用户。

基于内容标签
今天说的第二种推荐算法,是基于内容标签,根据内容的特征打上对应标签,将同一标签下的不同物品推荐给用户,比如当用户浏览文具类商品时,铅笔跟橡皮都是文具类,系统就会给用户推荐这两种商品。
需要说明的是,这里所说的推荐相似物品并不依赖于用户的历史数据,仅仅是与物品本身的标签相似度有关。比如我第一次登录网易云音乐,我选择轻音乐的标签之后,系统就会自动给我推送钢琴曲,而不需要我的历史听歌数据。
此外在基于内容标签方面,还有基于知识的推荐例子,比如说知乎在给用户推荐同一领域的文章时,是根据文章中,知识本身所属领域的标签,而不取决于用户的历史偏好数据。
优点:
可见基于内容标签的推荐算法优点是不会过度依赖用户的历史数据,就算是新内容,也能有被推荐的机会。
缺点:
缺点是推荐内容的质量取决于标签的准确性,如果内容的标签不准确,那么相应的推荐,也就无法很好地满足用户需求。其次由于标签缺少用户反馈,这就导致标签的准确性难以得到优化提升。

基于关联规则
下面我们要说的第三种推荐算法,是基于关联规则进行推荐,这是一种转化率比较高的推荐算法,因为它的原理是从历史数据中挖掘关联规则,根据内容与内容的相关性进行推荐。
比如网球和网球拍大多时候会被用户同时购买,或者是购买婴儿衣服的用户,在一定时间后会购买儿童衣服之类的关联规则。基于关联规则给用户推荐的内容,往往更有可能满足用户需求。
优点:
除了转化率高这一优点,这种推荐算法还能够发现用户的新兴趣点,挖掘出用户的潜在需求。
缺点:
但是挖掘关联规则需要大量的数据做支撑,并且在实际应用中,一些热门的项目关联度往往较高,容易被过度推荐。

基于情境感知
最后来说说基于情境感知的推荐算法,情境感知是指用户在进入系统时所处的时间、地点、日期、心情等情境,比如说你今晚回家突然想点个外卖吃,那么打开外卖APP后,系统给你推荐的可能会是烧烤、麻辣小龙虾之类的食物,而不会是豆浆、油条这类一般作为早餐的食物,这就是基于时间的推荐。
而基于地点的推荐,体现在系统给你推荐商家的时候,往往是附近的商家,而不会推荐十公里以外的食物,毕竟太远的距离,小龙虾就凉了不好吃了。
优点:
这种基于情境感知的推荐算法优点在于实时性,比如说虽然你在淘宝有过夏装的购物历史,但系统也不会在冬天给你推荐夏装。此外用户的兴趣还可能会随时间变化,比如大学时期用户喜欢购买文学类书籍,但工作后可能更多购买专业书籍,而这种推荐算法的多样性,则能够在不同时间段推荐不同的内容,更加灵活地满足用户需求。
缺点:
但其缺点是推荐范围比较窄,受到情境的影响,一些内容无法推荐给用户,并且在多维度情境下内容匹配度的计算比较复杂。还存在冷启动问题,比如外卖APP中,如果用户不授权APP获取位置信息,则无法根据地点进行推荐。
8种推荐算法介绍完了,以下是对这8种算法的对比表格,供大家参考。
原文始发于微信公众号(夸克网)