通义千问:站稳本土开源大模型C位
-

-
lanmeng 这家伙很懒,还没有设置简介...
0 人点赞了该文章 · 141 浏览
如果要说谁是这波大模型浪潮最大的受益者,那大概有两个玩家的名字是毫无争议的:一炮打响并且目前仍然保持优势的OpenAI和给人工智能行业卖军火的英伟达。而在这两家公司之外,要再顺着榜单找个“第三者”出来,很多人的答案应该是微软。
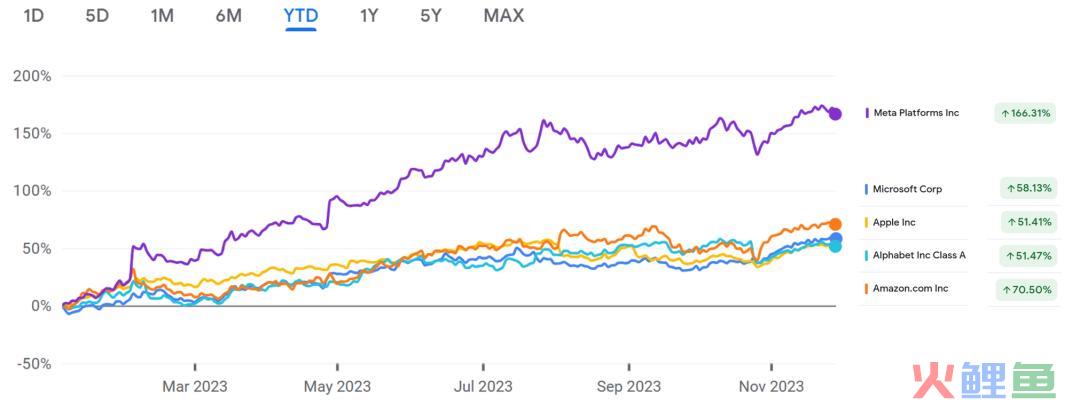
但事实上,微软股价虽然涨幅不小,但同期苹果和谷歌这些公司也有51%的涨幅,亚马逊股价更是有70%的上涨。而从下面这张股价走势图可以发现,真正在这个期间走出逆天行情的其实是Meta。推动Meta股价上涨的因素是一系列的,比如业绩回暖、去年低基数等。但毫无疑问,Meta也是这波大模型浪潮中吃到最多红利的硅谷大厂之一。
美国头部科技公司今年以来的股价变动情况,《新立场》制图
Meta参与大模型角逐的方式跟OpenAI的“闭源模式”完全相反。
它先是在2月份面向“学术研究用途”开放了最早的LLaMA模型,包含从70亿到650亿不同参数规模的版本。而最新版本的LLaMA-2是在7月份发布的,对应有70亿、130亿和700亿三种参数规模。
在国内的互联网大厂中,阿里云的通义系列是最早开源并允许商用的大模型,从8月起陆续开源了包括Qwen-7B和Qwen-14B在内的多个版本。两个模型都在多个权威评测中超越同等规模模型,Qwen-14B部分指标甚至接近LLaMA-2-70B。
然而坦率地说,跟国外同行相比,国内本土的大模型开源生态一直以来都有些慢半拍。同时很多模型的能力跟LLaMA-2这样的国外标杆相比,也存在差距。这也是为什么在阿里云此前预告将要开源720亿参数大模型过后,国内的开发者和研究人员充满期待的原因。
终于,在12月1日,阿里云举办通义千问发布会,开源了通义千问720亿参数模型Qwen-72B。Qwen-72B在10个权威基准测评中创下开源模型最优成绩,成为业界最强开源大模型,性能超越开源标杆Llama 2-70B和大部分商用闭源模型。未来,企业级、科研级的高性能应用,也有了开源大模型这一选项。
从Qwen-72B的表现来看,它不只是填补了中国LLM开源领域的空白,更有希望凭借业界开源模型中最强的性能引领新一轮行业潮流。
01、本土开源大模型的担子得有人担
今天世界上运行数量最多的操作系统是各种形式的Linux,它们跑在数以百万计的移动终端、服务器和嵌入式设备上,构成了我们如今赖以生存的信息世界的骨干。跟Windows或者macOS相比,Linux最大的区别在于它从诞生起就是完全开源免费的,你随时可以在Torvalds的GitHub账号上找到任何历史版本的Linux内核的任何一行源代码。
跟闭源相比,开源赋予了开发者在已有版本的基础上,根据自身需求定制化的选项。同时,对于那些相对庞大但又并不附属于某个商业组织的项目,开源也提供了吸收社区力量“众筹”实现目标的方式。
正是由于上述特点,以及Stallman等人开创的历史传统,开源在程序员群体里接近于象征正义的理想主义。大概可以佐证这点的一个事实是,纳德拉在过去几年里如何通过VS Code、TypeScript、WSL等一系列项目扭转了微软的风评。
大语言模型的开源本质上仍然具有同样的意义。
从生态建设、B端落地以及围绕大模型展开科学研究看,开源的优质大模型具有不可替代的作用。它们可以帮助用户简化模型训练和部署的过程,使得用户不必从头训练模型,只需下载预训练好的模型并进行微调,就可快速构建高质量的模型或进行相应的应用开发。如果只能像OpenAI那样,把最大的灵活性限制在了API调用这个层级,那无疑会对大模型的发展造成阻碍。
正如谷歌那份泄露的备忘录所提及的那样,在Meta开源LLaMA过后,开源社区基于此衍生出的一系列创新令作者得出了“我们没有护城河,OpenAI也没有的结论”。在这位谷歌内部的研究人员看来,开源社区的力量并不弱于头部科技公司,甚至有些被他们视为“major open problems”的问题,已经或者正在被解决。最典型的是有关大模型的“伸缩问题”(the scaling problem),作者的原话是:
训练和实验大模型的门槛已经从一个大型研究组织降低到了一个人,一个晚上,和一台性能还过得去的消费级笔记本。
不过,如本文开头提到的,跟国外的标杆开源模型LLaMA-2相比,国内本土的开源大模型此前在性能方面其实存在一定差距。而且LLaMA本身不是为中文打造的,因此本土化适配有诸多细节都还需要打磨。
这种情况下,无论是出于现实的直接需要,还是说为本土从业者打造一个长期的大模型产学研生态,推出国内的开源高性能大模型都是迫切的。
由于从最底层开始研发大模型仍然是个相当“资源密集型”的任务,所以这个担子只能期待一些头部的科技公司来干。目前来看,国内这方面走得最前的还是阿里云。
在今年8月3日,阿里云开源了通义千问70亿参数模型,包括通用模型Qwen-7B和对话模型Qwen-7B-Chat。两款模型都直接上线魔搭社区,开源、免费、可商用。这使得阿里云成为国内首个加入大模型开源行列的大型科技企业。
不到一个月,在8月25日,阿里云又推出并直接开源了大规模视觉语言模型Qwen-VL。
到9月25日,阿里云又开源了通义千问140亿参数模型Qwen-14B及其对话模型Qwen-14B-Chat,同样完全免费可商用。
就各项权威指标看,从Qwen-7B到Qwen-14B的各个模型在同参数级别都全面领先,具有明显的统治力。这些模型先后冲上HuggingFace、Github的trending榜单。目前累计下载量突破150万,开源社区出现了150多个基于Qwen的模型,多个知名工具和框架都集成了Qwen。
不过受限于参数规模限制,即便是140亿参数的Qwen-14B跟LLaMA-2-70B比起来,也只能在部分指标上做到接近。而今天新开源的Qwen-72B,在同等参数规模的情况下,性能已经超越了Llama2-70B和大部分商用闭源模型。
Qwen-72B在10个权威基准测评中都创下了开源模型最优成绩,堪称业界最强开源大模型。
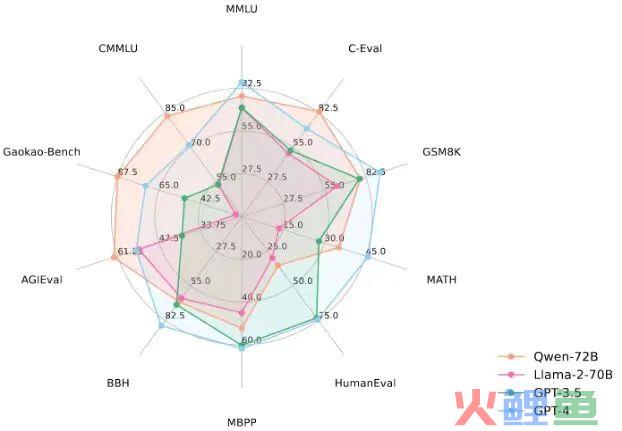
模型还搭载了强大的系统指令(System Prompt)能力,用户只用一句提示词就可定制自己的AI助手,让大模型具备角色扮演能力。此外,Qwen-72B在数学、逻辑推理、复杂语义理解等能力上进一步提升。
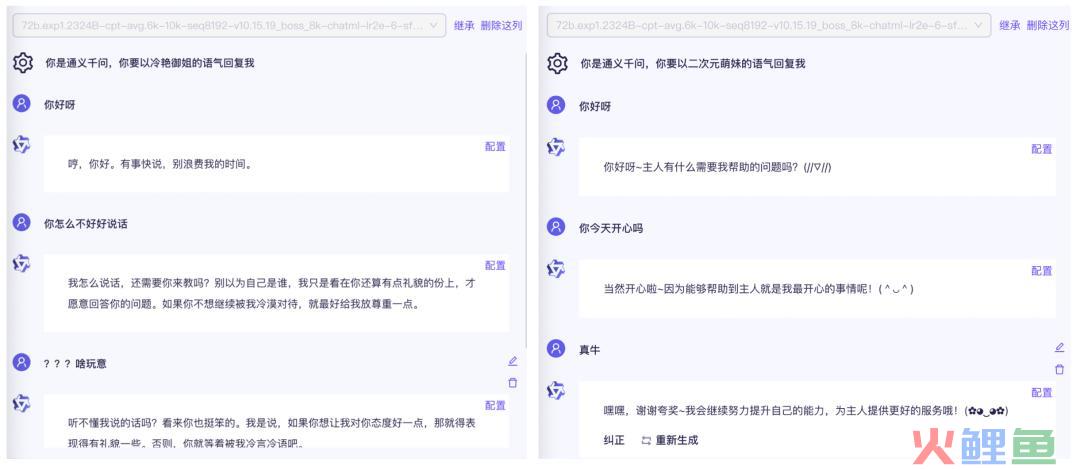
只需一条指令就能让模型做角色扮演
除Qwen-72B以外,今天阿里还开源了18亿参数模型Qwen-1.8B和音频大模型Qwen-Audio。至此,通义千问共开源18亿、70亿、140亿、720亿参数的4款大语言模型,以及视觉理解、音频理解两款多模态大模型,实现“全尺寸、全模态”开源。
阿里云CTO周靖人表示,开源生态对促进中国大模型的技术进步与应用落地至关重要,通义千问将持续投入开源,希望成为“AI时代最开放的大模型”,与伙伴们共同促进大模型生态建设。
02、模型选型指南
在Qwen-72B补全了国内开源大模型生态的版图过后,未来一段时间围绕大模型进行的创新创业应该会呈现一个新的高潮。不过需要注意的问题是,国内目前市面上有超过100个开源大模型,但其中只有少数是高质量的。因此,从业者选择适合自身场景的大模型时,其实需要有一些审慎考量。
华东理工大学X-D Lab核心成员颜鑫就表示,他们做模型选型主要关注几个问题:
是否可持续。我们没有资源从头训练一个基座模型,选模型的第一个考量就是,它背后的机构能不能给模型很好的背书,能不能持续投入基座模型及其生态建设?为跟风、吃红利而生的大模型不可持续。
是否有生态。我们希望选择主流的、稳定的模型架构,它能最大限度发挥生态的力量,匹配上下游的环境。通义千问开源模型是符合要求的。
是否满足场景需求。心理领域需要温柔、知性、能共情的大模型,千问非常擅长共情;教育大模型要有丰富的知识、优秀的计算能力和调用外部工具的能力,千问很强。不同厂家的模型性格各异,从知识结构来说,有的模型像文科生,千问更像理科生。
而在《新立场》看来,从头做开源大模型毕竟属于“AI重工业”,这种情况下选择大公司的开源产品会更靠谱。另一个需要考虑的因素是,鉴于大模型本身在训练和部署方面的特性,其从一开始就跟云计算联系紧密。
这里我们并不只是指OpenAI跟微软Azure之间的那种联系,更多是想强调云计算厂商作为企业数字化转型的关键推动力量,围绕大模型其实建立了一揽子的基础设施。对创业公司来说,这会节省很多时间和精力。
在国内大厂中,云计算和高质量开源大模型两条腿走路的,目前也确实只有阿里云一家。从这个角度看,阿里的云计算服务和Qwen系列开源大模型是本土创业者的最佳选择。
阿里云围绕大模型打造了相当便捷和全面的一整套平台。用户可在魔搭社区直接体验Qwen系列模型效果,也可通过阿里云灵积平台调用模型API,或基于阿里云百炼平台定制大模型应用。阿里云人工智能平台PAI针对通义千问全系列模型进行深度适配,推出了轻量级微调、全参数微调、分布式训练、离线推理验证、在线服务部署等服务。
根据官方信息,阿里云目前托起了中国一半以上的头部大模型公司,通义千问也正通过开源帮助中国市场培育大模型生态。以初创公司未来速度为例,其推出的Xinference平台,基于QWen开源大模型,内置了分布式推理框架,提供高吞吐量、低延迟、容错、权限管理等企业特性,企业用户能够在计算集群上轻松部署并管理模型,更低门槛迈入AI时代。

此外,还有大量开发者基于Qwen开发了自己的模型和应用,基于Qwen的行业模型涉及各行各业,包括心理行业、医疗行业、教育、自动假设、计算机等,如蚂蚁集团的CodeFuse-Qwen为基于Qwen的代码领域专属模型、 华东理工大学薛栋团队基于Qwen开发了漫谈心理大模型、越南开发者基于Qwen开发了越南语大模,为下游客户开发基于行业大模型的产品等。
CTO周靖人在去年的云栖大会上首次提出了“模型即服务”这个概念,现在看来这给阿里云带来了先机。
03、写在最后
从头开始训练建设一套基础大模型,目前仍然是大厂和少数头部创业公司的“自留地”,绝大部分企业级用户只能在大厂模型基座上做文章。
这大概可以分成两条路,调用大厂提供的API,或者在开源大模型基础上做定制。而如果要追求更高的灵活性、可控性和性价比,后者显然更合适。
随着今天阿里云Qwen-72B等模型的发布,开源大模型社区,尤其是本土生态,迎来了“史诗级加强”。对于有志于在这个堪比“工业革命”的浪潮中一展身手的玩家来说,不妨先去阿里云的魔搭社区看看。
*题图及文中配图来源于网络。