数据库设计应该考虑清楚的几个问题
-

-
Edwards 这家伙很懒,还没有设置简介...
0 人点赞了该文章 · 363 浏览
数据库设计应该考虑清楚的几个问题
很多开发者一参与到数据库设计,就会很自然地把 “三范式” 当作银弹一样来使用。他们往往认为遵循这个规范就是数据库设计的唯一标准。由于这种心态,他们往往尽管一路碰壁也会坚持把项目做下去。我在做数据库设计的时候,通常都会把这些下面这些考虑在内。只有先把这些重要的问题考虑清楚了,才能使数据库设计更加顺利进行,避免不必要的错误。
问题一:弄清楚将要开发的应用程序是什么性质的(OLTP 还是 OPAP)?
当你要开始设计一个数据库的时候,你应该首先要分出你为之设计的应用程序是什么类型的,它是 “事务处理型”(Transactional) 的仍是 “分析型” (Analytical)的?你会发现很多开发人员选用标准化做法去设计数据库,而不思考方针程序是什么类型的,这样做出来的程序很快就会堕入功能、客户定制化的问题傍边。
事务处理型:这种类型的应用程序,你的最终用户更重视数据的增查改删(CRUD,Creating/Reading/Updating/Deleting)。这种类型愈加官方的叫法是 “OLTP” 。
分析型:这种类型的应用程序,你的最终用户更重视数据分析、报表、趋势猜测等等功能。这一类的数据库的 “刺进” 和 “更新” 操作相对来说是比较少的。它们首要的意图是愈加疾速地查询、分析数据。这种类型愈加官方的叫法是 “OLAP” 。
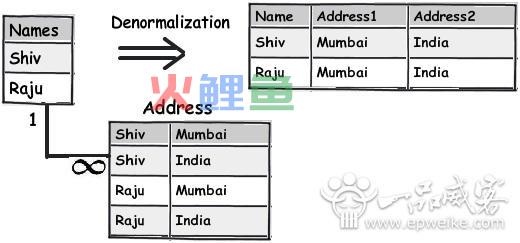
以下这个简略的图表显现了像左面 Names 和 Address 这样的简略规范化的表,怎么经过应用不规范化构造来创立一个扁平的表构造。
问题二:将你的数据按照逻辑意义分成不同的块,让事情做起来更简单
这个规则其实就是 “三范式” 中的第一范式。违反这条规则的一个标志就是,你的查询使用了很多字符串解析函数例如 substring、charindex 等等。若真如此,那就需要应用这条规则了。比如你看到的下面图片上有一个有学生名字的表,如果你想要查询学生名字中包含“Koirala”,但不包含“Harisingh”的记录,你可以想象一下你将会得到什么样的结果。所以更好的做法是将这个字段拆分为更深层次的逻辑分块,以便我们的表数据写起来更干净,以及优化查询。
问题三:当心被分隔符分割的数据,它们违反了“字段不可再分”
“第一范式”说的是避免 “重复组” 。下面这个图表作为其中的一个例子解释了 “重复组”是什么样子的。如果你仔细的观察 syllabus(课程) 这个字段,会发现在这一个字段里实在是填充了太多的数据了。像这些字段就被称为 “重复组” 了。如果我们又得必须使用这些数据,那么这些查询将会十分复杂并且我也怀疑这些查询会有性能问题。这些被塞满了分隔符的数据列需要特别注意,并且一个较好的办法是将这些字段移到另外一个表中,使用外键连接过去,同样地以便于更好的管理。
问题四:仔细地选择派生列
如果你正在开发一个 OLTP 型的应用程序,那强制不去使用派生字段会是一个很好的思路,除非有迫切的性能要求,比如经常需要求和、计算的 OLAP 程序,为了性能,这些派生字段就有必要存在了。Average 字段依赖 Marks 和 Subjects 字段。这也是冗余的一种形式。因此对于这样的由其他字段得到的字段,需要思考一下它们是否真的有必要存在。这个规则也被称为 “三范式” 里的第三条:“不应该有依赖于非主键的列” 。
问题五:如果性能是关键,不要固执地去避免冗余
不要把 “避免冗余” 当作是一条绝对的规则去遵循。如果对性能有迫切的需求,考虑一下打破常规。常规情况下你需要做多个表的连接操作,而在非常规的情况下这样的多表连接是会大大地降低性能的。
问题六:注意重复、不统一的数据
会集那些重复的数据然后重构它们。我自己愈加忧虑的是这些重复数据带来的紊乱而不是它们占用了多少磁盘空间。
例如下面这个图表,你能够看到 “5th Standard” 和 “Fifth standard” 是相同的意思,它们是重复数据。如今你可能会说是由于那些录入者录入了这些重复的数据或者是差劲的验证程序没有拦住,让这些重复的数据进入到了你的体系。如今,假如你想导出一份将原本在用户眼里非常迷惑的数据显示为不一样实体数据的陈述,该怎么做呢?
解决方法之一是将这些数据完整地移到别的一个主表,然后经过外键引证过来。在下面这个图表中你能够看到咱们是怎么创立一个名为 “Standards”(课程等级) 的主表,然后同样地运用简单的外键连接曩昔。
那么,让咱们如今就运用(榜首范式) “防止重复组” 吧。你能够看到上面这个图表,我创立了一个独自的 syllabus(课程) 表,然后运用 “多对多” 联系将它与 subject(科目) 表相关起来。经过这个方法,主表(student 表)的 syllabus(课程) 字段就不再有重复数据和分隔符了