壮实学数据技术04:ETL
-

-
hjclr 这家伙很懒,还没有设置简介...
0 人点赞了该文章 · 244 浏览

hi,米娜桑,壮实又在周六早上和大家见面啦~
经过上节的《壮实学数据技术03:数据接入》,我们要进入到数据开发的阶段喽。在了解数据开发的时候,我们绕不过去一个词:ETL。
那么什么是ETL?我们为什么需要ETL?市面上的ETL工具有哪些?今天,壮实来带你盘盘ETL。
一、什么是ETL
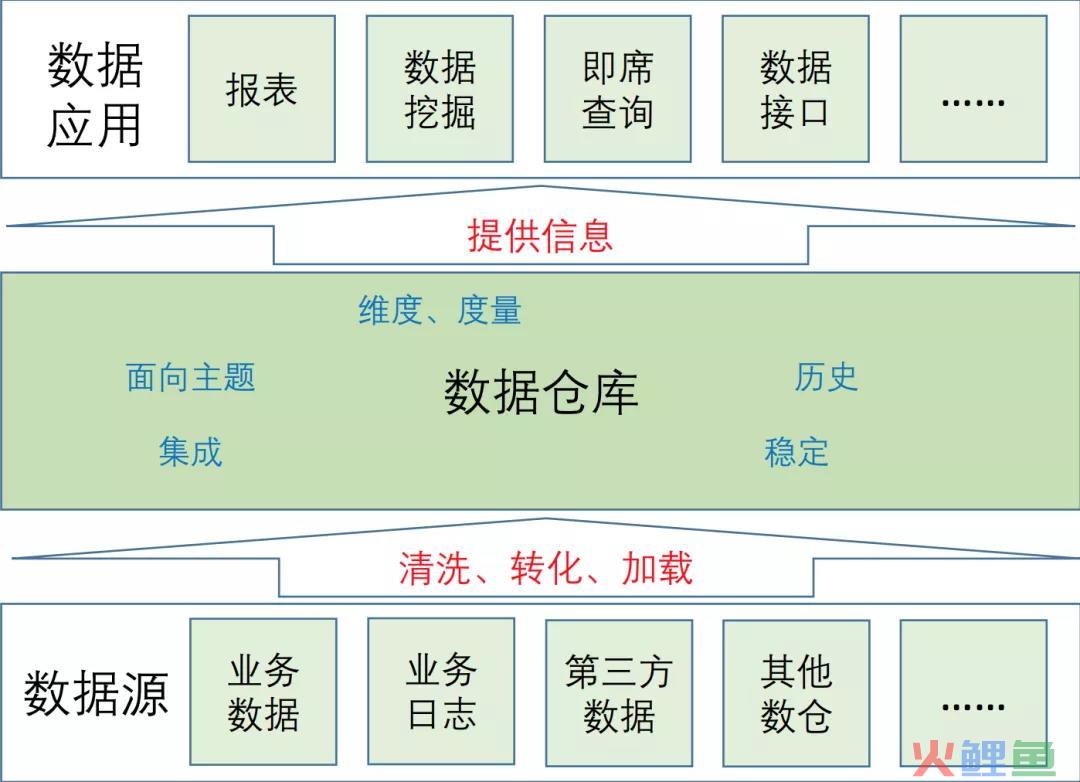
上回书我们说到,数据接入到数仓中后,需要经过一系列操作,供业务方使用。而这一系列的操作过程,简单来说就是数据就要按照统一的规则集成。我们把这些规则集成,叫做一个个数仓模型。
如果把数仓模型比做大厦,数据是砖瓦的话,那么ETL就是建设大厦的过程。它链接着数据源和数据仓库的两端。
在数仓建设的整个项目中,最难部分是用户需求分析和模型设计,而ETL规则设计和实施则是工作量最大的,约占整个项目的60%~80%,这是国内外从众多实践中得到的普遍共识。
ETL(Extract-Transform-Load),即数据从数据源经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。我们从数据源抽取出所需的数据,经过数据清洗,最终按照预先定义好的数据仓库模型,将数据加载到数据仓库中去。这中间有各种各样的同步数据和异步数据,常见的有mysql2hive、hive2hive、hive2mysql等等。
ETL的实现,常见为三种。一种是借助ETL工具,一种是SQL方式,另外一种是ETL工具和SQL相结合。前两种方法各有各的优缺点,借助工具可以快速的建立起ETL工程,可以屏蔽复杂的编码任务,提高速度,降低难度,但是缺少灵活性。而SQL的方法优点是灵活,提高ETL运行效率,但是编码复杂,对技术要求比较高。第三种是综合了前面二种的优点,极大地提高ETL的开发速度和效率。
ETL工具有 Datastage、Informatica、Kettle 等。其中 Datastage、Informatica 都是收费昂贵的商业工具,Kettle是基于Java开发的开源工具,这些工具可以通过拖拽配置等方式进行ETL开发。
二、为什么需要ETL
那么为什么需要ETL呢?主要有以下几点原因:
1、当数据来自不同的物理机,这时候如果使用SQL处理的话会浪费计算资源。
2、数据来源于不同数据库或者文件,需要把他们整理成统一的格式后才可以进行数据处理,这一过程用代码实现会很麻烦。
3、处理海量数据时会占用较多数据库的资源,会导致数据库资源不足,进而影响数据库的性能。
简单来说,进行不同数据源的ETL之后,会节省计算资源、存储资源、代码也会简单很多,省钱又省力,还省心。

三、ETL工具连连看
3.1 ETL工具选择依据
(1)对平台的支持程度
(2)抽取和装载的性能是不是较高,且对业务系统的性能影响大不大,侵入性高不高
(3)对数据源的支持程度
(4)是否具有良好的集成性和开放性
(5)数据转换和加工的功能强不强
(6)是否具有管理和调度的功能
3.2 主流ETL工具推荐
商用
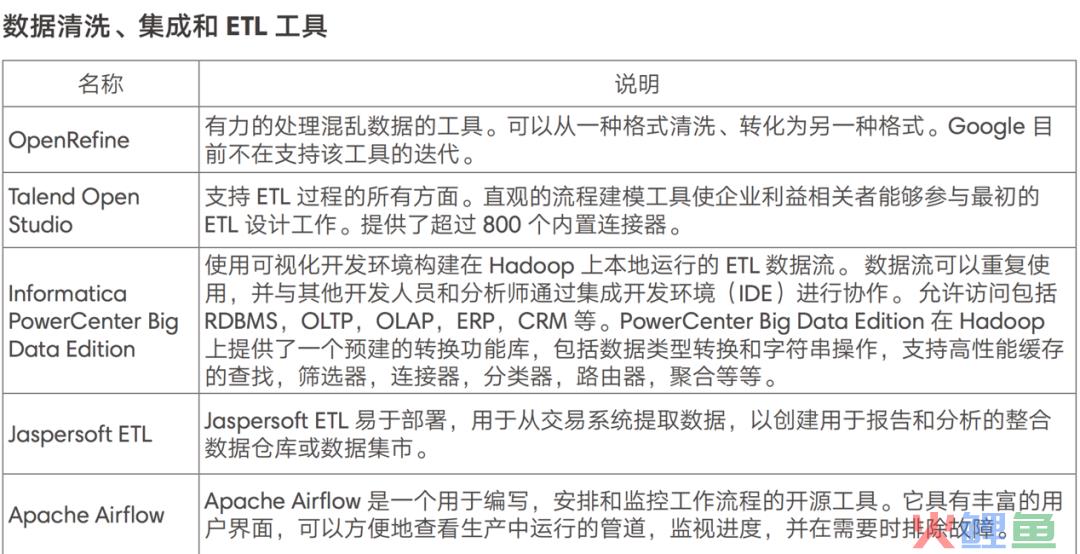

企业
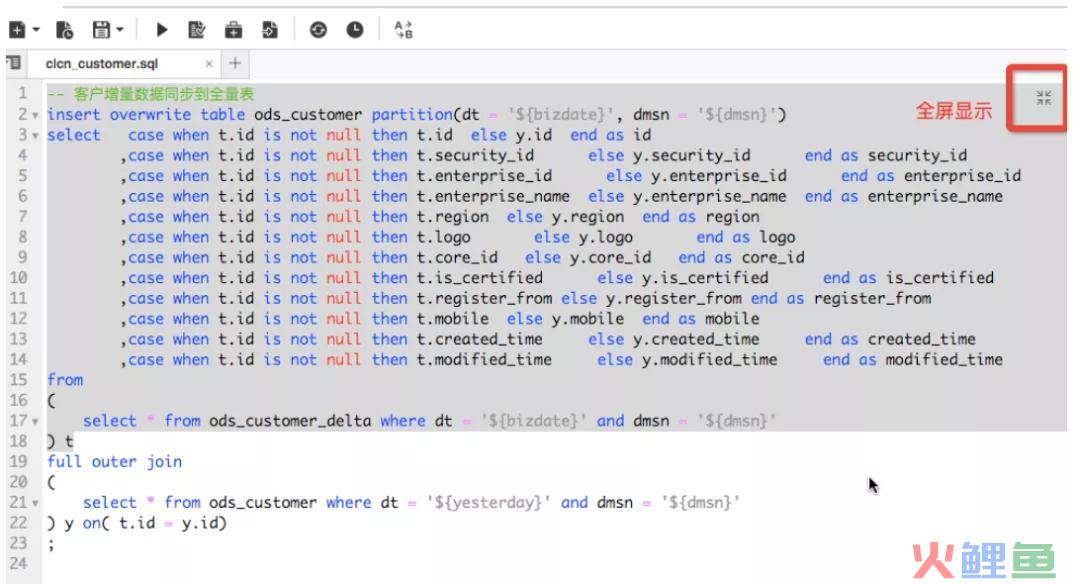
(1)阿里-御膳房
我们可以看一下阿里御膳房这个产品, 在数据开发的整个流程中,是以“模型设计”、“数据开发”、“发布”、“运维”流程化展开的。

类似的设计还有蚂蚁的ETL数据平台:
(2)网易猛犸大数据平台
在大数据开发套件的数据开发模块,网易猛犸大数据平台提供了数据库传输、SQL、Spark、OLAP Cube、MapReduce及Script各种类型任务的敏捷开发界面,任务开发者可以通过拖拽创建任务,方便地进行数据集成、数据ETL、数据分析等数据科学工作。以数据库传输为例,用户只需将“数据库传输”组件拖拽到画布上并双击,通过下拉框选择和手动输入填写表单,快速完成数据传输的任务开发。

(3)字节跳动priest
用户可以进行统一托管,声明式ETL定义。援引https://myslide.cn/slides/4103
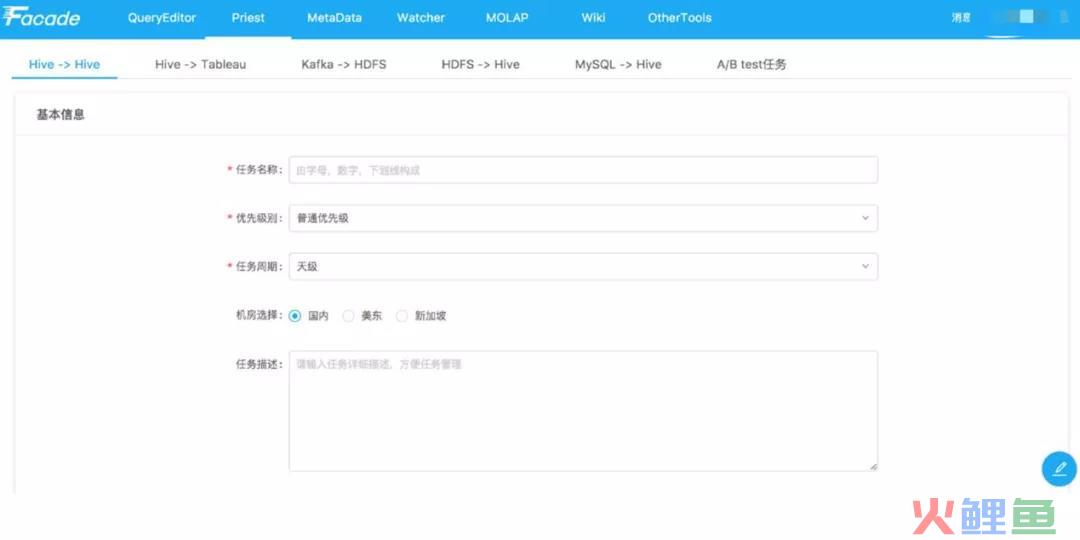
可以看到,目前ETL工具还是呈现百花齐放的方式,有类SQL模式、有拖拽模式、有封装配置模式。
当然,深入到数据开发的产品类型当中,远远不止这些,还设计到UDF、DSN、ETL参数调优(小文件过多&数据倾斜)、transform等等。
除此之外,还有ETL调度、SLA链路等等设计到数据开发后的数据调度、数据生产的流程。如果同学们对数据开发产品感兴趣,可以线下自助查询~
好啦,今天《壮实学数据技术04:ETL》就到这里啦,谢谢你的围观~

-END-