用户标签体系如何搭建?(如何运用用户标签提高转化率?)
-

-
乔峰 这家伙很懒,还没有设置简介...
0 人点赞了该文章 · 149 浏览

亚马逊的CEO Jeff Bezos曾说过他的梦想,「如果我有一百万的用户,我就会做一百万个不同的网站!」,做这个基础是先对用户打标签。

用户标签是精细化运营的基础,能有效提高流量的分发效率和转化效率。
而目前基于标签的智能推荐系统,已经有了成熟商业应用,比如:淘宝的千人千面,美团外卖的智能推荐,腾讯的社交广告。
思考的背景
从16年开始,互联网用户增长趋缓,同比仅增长。一方面,不论是线上还是线下,新用户的获取成本都很高。另一方面,用户时间增长也在趋缓。在用户花费时间趋向饱和情况下,不同的产品之间同样存在竞争关系。
在这个背景下,随着用户量增长,运营人员面临新的挑战,有以下核心诉求:
一般运营活动中,怎么对不同用户群体分层,提高流量的分发效率?
对于个体用户,怎么深入到日常使用场景,提高流量的转化效率?
落到产品设计层面,需要解决以下问题:
怎么设计一个完善的用户标签体系?怎么打标签?打哪些标签?谁来打?
怎么使用用户标签,创造商业价值?
标签系统的结构
标签系统可以分为三个部分:数据加工层,数据服务层,数据应用层。每个层面面向用户对象不一样,处理事务有所不同。层级越往下,与业务的耦合度就越小。层级越往上,业务关联性就越强。
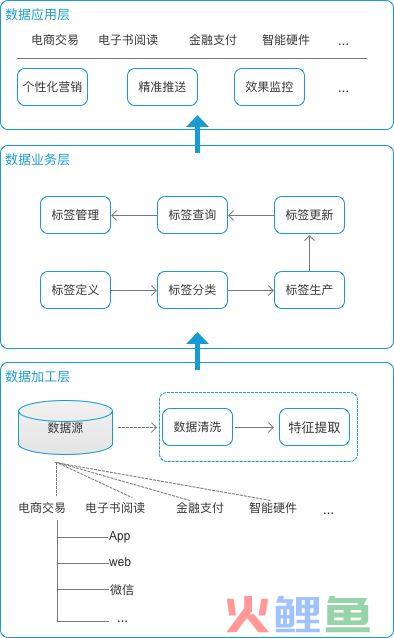
以M电商公司为例,来说明该系统的构成。
数据加工层。数据加工层收集,清洗和提取来处理数据。M公司有多个产品线:电商交易,电子书阅读,金融支付,智能硬件等等。每个产品线的业务数据又是分属在不同位置。为了搭建完善的用户标签体系,需要尽可能汇总最大范围内的数据。同时每个产品线的也要集合所有端的数据,比如:App,web,微信,其它第三方合作渠道。
收集了所有数据之后,需要经过清洗:去重,去刷单数据,去无效数据,去异常数据等等。然后再是提取特征数据,这部分就要根据产品和运营人员提的业务数据要求来做就好。
数据业务层。数据加工层为业务层提供最基础数据能力,提供数据原材料。业务层属于公共资源层,并不归属某个产品或业务线。它主要用来维护整个标签体系,集中在一个地方来进行管理。
在这一层,运营人员和产品能够参与进来,提出业务要求:将原材料进行切割。主要完成以下核心任务:
定义业务方需要的标签。
创建标签实例。
执行业务标签实例,提供相应数据。
数据应用层。应用层的任务是赋予产品和运营人员标签的工具能力,聚合业务数据,转化为用户的枪火弹药,提供数据应用服务。
业务方能够根据自己的需求来使用,共享业务标签,但彼此业务又互不影响。
实践中可应用到以下几块:
精准化营销。
个性化推送。
业务梳理
搭建用户标签体系容易陷入用户画像陷阱,照葫芦画瓢,不利于标签体系的维护和后期的扩展。
可以按下面的思路来梳理标签体系:
有哪些产品线?产品线有哪些来源渠道?一一列出。
每个产品线有哪些业务对象?比如用户,商品。
最后再根据对象聚合业务,每个对象涉及哪些业务?每个业务下哪些业务数据和用户行为?
结果类似如下:

标签的分类
按业务对象整理了业务数据后,可以继续按照对象的属性来进行分类,
主要目的:
方便管理标签,便于维护和扩展。
结构清晰,展示标签之间的关联关系。
为标签建模提供子集。方便独立计算某个标签下的属性偏好或者权重。
梳理标签分类时,尽可能按照MECE原则,相互独立,完全穷尽。每一个子集的组合都能覆盖到父集所有数据。标签深度控制在四级比较合适,方便管理,到了第四级就是具体的标签实例。
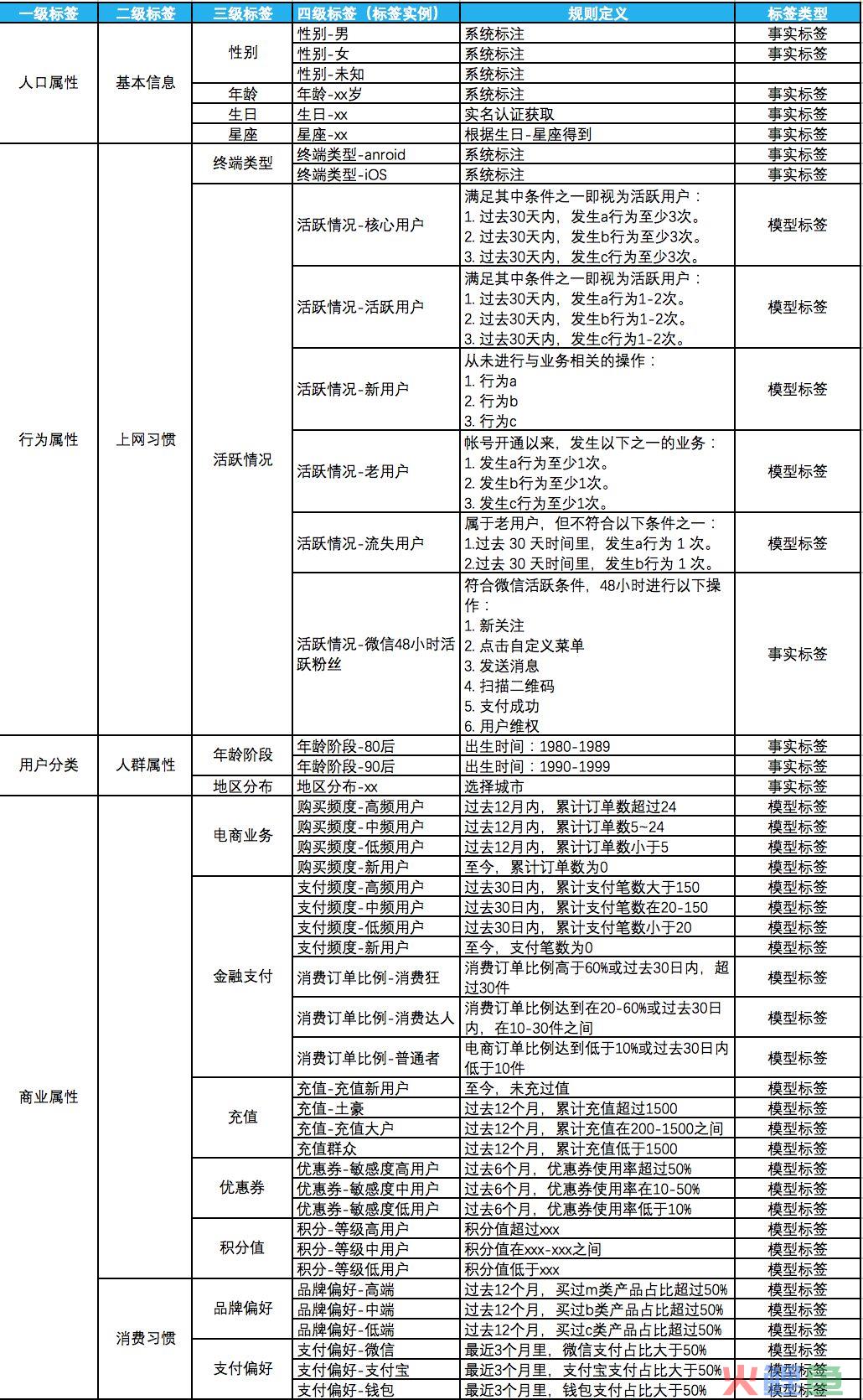
标签的模型
按数据的实效性来看,标签可分为
静态属性标签。长期甚至永远都不会发生改变。比如性别,出生日期,这些数据都是既定的事实,几乎不会改变。
动态属性标签。存在有效期,需要定期地更新,保证标签的有效性。比如用户的购买力,用户的活跃情况。
从数据提取维度来看,标签数据又可以分为类型。
事实标签。既定事实,从原始数据中提取。比如通过用户设置获取性别,通过实名认证获取生日,星座等信息。
模型标签。没有对应数据,需要定义规则,建立模型来计算得出标签实例。比如支付偏好度。
预测标签。参考已有事实数据,来预测用户的行为或偏好。比如用户a的历史购物行为与群体A相似,使用协同过滤算法,预测用户a也会喜欢某件物品。
标签的处理
为什么要从两个维度来对标签区分?这是为了方便用户标签的进一步处理。
静态动态的划分是面向业务维度,便于运营人员理解业务。这一点能帮助他们:
理解标签体系的设计。
表达自己的需求。
事实标签,模型标签,预测标签是面向数据处理维度,便于技术人员理解标签模块功能分类,帮助他们:
设计合理数据处理单元,相互独立,协同处理。
标签的及时更新及数据响应的效率。
以上面的标签图表为例,面临以下问题:
属性信息缺失怎么办?比如,现实中总有用户未设置用户性别,那怎么才能知道用户的性别呢?
行为属性,消费属性的标签能不能灵活设置?比如,活跃运营中需要做A/B test,不能将品牌偏好规则写死,怎么办?
既有的属性创建不了我想要的标签?比如,用户消费能力需要综合结合多项业务的数据才合理,如何解决?
模型标签的定义解决的就是从无到有的问题。建立模型,计算用户相应属性匹配度。现实中,事实标签也存在数据缺失情况。比如用户性别未知,但是可以根据用户浏览商品,购买商品的历史行为来计算性别偏好度。当用户购买的女性化妆品和内衣较多,偏好值趋近于性别女,即可以推断用户性别为女。
模型计算规则的开放解决的是标签灵活配置的问题。运营人员能够根据自己的需求,灵活更改标签实例的定义规则。
比如图表中支付频度实例的规则定义,可以做到:
时间的开放。支持时间任意选择:昨天,前天,近x天,自定义某段时间等等。
支付笔数的开放。大于,等于,小于某个值,或者在某两个值区间。
标签的组合解决就是标签扩展的问题。除了原有属性的规则定义,还可以使用对多个标签进行组合,创建新的复合型标签。比如定义用户的消费能力等级。
标签最终呈现的形态要满足两个需求:
标签的最小颗粒度要触达到具体业务事实数据,同时支持对应标签实例的规则自定义。
不同的标签可以相互自由组合为新的标签,同时支持标签间的关系,权重自定义。
实践分享
数据应用层即为标签的使用场景,最典型的应用场景是:精准推送。
精准推送。该场景对标签的实效性要求并不高,可以只考虑离线的历史数据,不需要结合实时数据,是标签首选的实践场景。运营人员使用标签筛选出目标用户,定向推送活动。推送渠道根据活动的需要来进行多渠道投放,能够支持微信,App,短信。
运营主要工作基本就是不停地生产活动,向用户投食,监测活动的效果,不断优化投放策略:找到不同用户对应的最佳匹配活动。这块主要关注活动以下环节:
活动前:目标用户,活动内容,投放渠道。
活动中:效果监控和跟踪。
活动后:效果复盘和优化。
除精准推送外,用户标签还有其它的应用场景。在技术层面上,对算法建模及响应性能也有更高的要求:
推荐栏位
消费周期评估
广告投放
促销排期
另外,用户的数据信息不仅局限于应用内本身。仅通过用户昵称或手机号已经足以爬取到用户在全网内留下的所有信息,从而构建丰富的用户画像。你多大?在哪里工作?家庭人员情况?在技术面前,都是一张透明的白纸。只不过目前这样做要花费很多人力,成本太高。
前天,产品群里有人问为啥有的产品引导用户关联第三方账号?同样是为了获取用户数据,用户一般并不知晓,以为只是增加新的登录方式。
建议及想法
如果你的产品微信粉丝数量接近千万级,不防试一试,用标签做精准营销。微信聚合了大量的粉丝,向商家端开放了粉丝的基本信息,提供了开放接口能力及多种消息触达方式,是最好的试验场。
微信聚合了最大和最优质的流量。从这个角度出发,基于微信提供的能力,做一款针对C端营销的CRM营销产品,存在着很大的商业机会。