联邦学习:实现数据安全隐私保护下模型训练利器(基础介绍)
-

-
rokin 这家伙很懒,还没有设置简介...
0 人点赞了该文章 · 118 浏览

“ 隐私保护,与互联网应用便捷性,真的是不可共生的吗?”
几年前,Robin在某论坛活动上表示:国人对于隐私不那么敏感,是愿意用牺牲隐私换取便捷性或者效率的。该观点一度引发舆论热点。
看起来,隐私和便捷性是不能协调共生的矛盾体一样。但真的完全无法调和这对矛盾吗?今天和大家分享一下联邦学习的一些基础概念,相信对于隐私保护问题会有一些启发。
本篇文章和之前的文章《个保法的施行内容和对互联网的影响》有些关联,可以参考。
01—联邦学习诞生背景
联邦学习诞生的背景,主要有两个:一是目前的数据在不同企业间往往是数据孤岛的存在,二是国内外政府对于用户隐私保护趋严。
(1)关于数据孤岛
数据孤岛的问题,其实在之前的文章中有所涉及。
目前由于各个公司之间业务的闭塞性与阻隔,使得不同公司、甚至同一公司不同部门之间的数据也十分割裂。
(2)关于用户隐私保护
随手一搜,海外互联网巨头因违规收集用户隐私而罚款的新闻比比皆是:
当然,最近两年国内对于用户隐私也越来越重视。比如2017年出台了《网络安全法》,今年9月刚生效的《数据安全法》,以及11月份施行的《个人信息保护法》(可参考《个保法对互联网行业的影响》)。均表明国内对于用户隐私、数据安全的监管愈发严格。
02—什么是联邦学习
我们回到最开始的问题。
公司为了提升算法、模型的表现,改善用户体验,需要收集用户的数据进行模型训练,但是个人隐私的保护使得我们不能将数据上传。怎么办呢?
对,如果数据不离开用户的使用设备,是不是就没有了隐私问题?
是的。但是用户本地的数据怎么能进行模型训练呢?
哈哈,这就是联邦学习了。
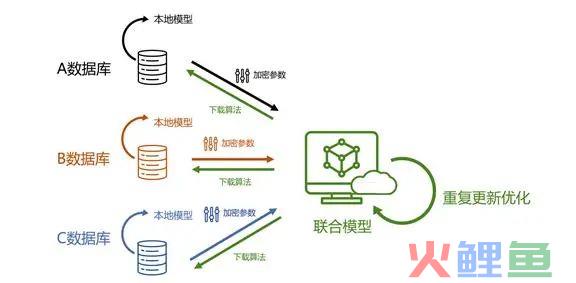
联邦学习是用去中心化的数据来训练中心化的模型,把模型训练的过程搬到了每台设备上。这就使得数据既没有离开本地,也完成了模型的训练过程。
03—联邦学习的基础流程
关于联邦学习的概要过程,这里简单介绍一下。
(1)数据下发与模型训练
参与训练的设备只有在具备参与资格的时候才会参与,平台方只会选取部分的设备接收训练模型,下发模型训练包。
用户接受到数据包后,进行本地的模型训练。通常来讲,训练模型只是几兆的数据包,几分钟就可以完成训练过程。因此对用户的影响是非常小的。
(2)训练结果回传
在用户本地设备训练完成后,会把训练结果(而不是用户的数据)传回服务器。而本地的数据包会自动消失。
(3)隐私保护
有的朋友会问:那平台是不是可以通过传给服务器的训练结果来逆向推导出用户的所有数据呢?
为了解决这个问题,联邦学习过程中,从一开始就是加密的。而且会使用连服务器都没有的秘钥来进行加密。服务器会使用安全聚合,将加密过的训练成果整合在一起,且只对聚合过程本身进行解密处理。
(4)模型测试
到这里,模型的一个简单训练过程是完成了。但是对于模型的升级还早着呢,因为还需要对模型测试、优化,最后才能正式升级。那如何对模型进行测试呢?
对,仍然在用户的本地设备上进行模型的测试。
有些设备完成模型的训练,有些设备完成模型的测试。在这样的联邦学习框架下,就可以确保用户的数据安全和个人隐私,并完成模型升级任务。
04—联邦学习的应用
想象一下,通过联邦学习,我们可以帮助医院在不侵犯患者隐私的前提下,提升诊断的准确率。
也可以通过聚合众多真实驾驶员的行为模式,来训练无人驾驶汽车。
其实国内目前应用联邦学习更多的场景是企业与企业之间的模型共建。
关于联邦学习的内容,就介绍这些,欢迎继续关注。
-END-