机器学习:都有哪些具体分类?项目的流程是怎样?
-

-
emydswg 这家伙很懒,还没有设置简介...
0 人点赞了该文章 · 212 浏览
“ 分享一些机器学习的基础。”
机器学习、人工智能应该是近几年最火的关键词之一了。今天分享一些机器学习的基础知识。如果有啥不正确的地方,欢迎各位大佬指正。
01—机器学习的定义
在说机器学习之前先明确一下,什么是人类的学习行为呢?
可以这样总结,人类从历史经验中获取规律,并将其应用到新的类似场景中,就是人类的学习行为。
相对应的,机器学习是指让机器去训练、去学习,让机器从大量数据中找到数据中的内在特征,从而对新事物做出判断。
02—机器学习的分类
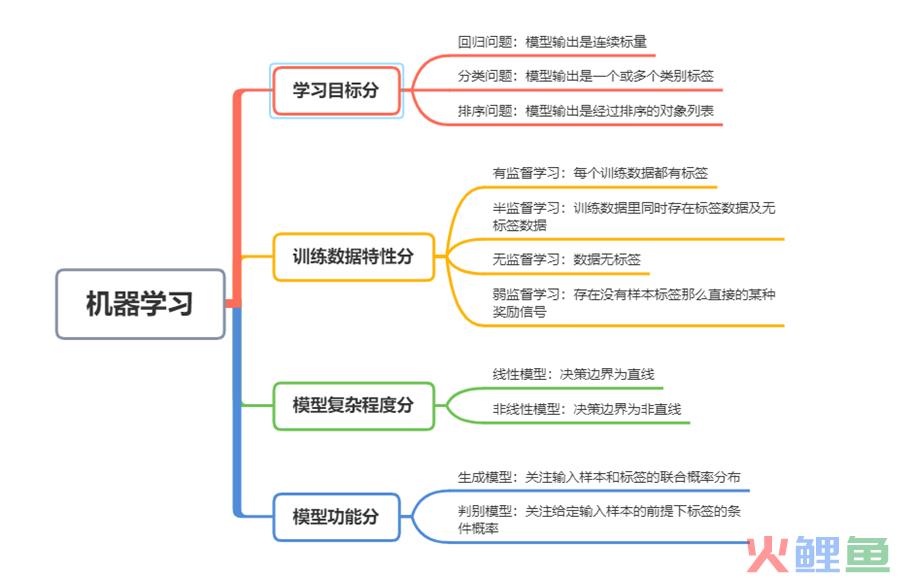
机器学习有哪些类别呢?按照不同的分类方式,有不同的细分类别。梳理了一下,主要有以下的概况图:
(1)按照学习目标分类
什么是机器学习目标呢?通俗来讲,就是我们想通过机器学习,最终实现的结果形态是什么样。
按照学习目标,主要可以分为三类:回归问题、分类问题、排序问题。
回归问题:解决的是目标是连续性变量的问题。比如想根据身高预测体重,体重就是一个连续性变量。
分类问题:解决的是目标是离散的标签的问题。比如预测一个人是男还是女。
排序问题:模型输出的是经过排序的对象列表。
(2)按照训练数据的特性分类
上文提到了,进行机器学习是需要训练数据为基础的(不然机器没法学习呀)。按照训练数据的特性,主要分为以下两类:
有监督学习:通过已有的训练样本去训练得到一个最优模型,再利用这个模型将所有的输入映射为相应的输出,对输出进行简单的判断从而实现预测和分类的目的,也就具有了对未知数据进行预测和分类的能力。有监督算法常见的有:线性回归算法、BP神经网络算法、决策树、支持向量机、KNN等。
无监督学习:训练样本的标记信息未知,目标是通过对无标记训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础,此类学习任务中研究最多、应用最广的是"聚类",聚类目的在于把相似的东西聚在一起,主要通过计算样本间和群体间距离得到。深度学习和PCA都属于无监督学习的范畴。无监督算法常见的有:密度估计、异常检测、层次聚类、EM算法、K-Means算法、DBSCAN算法等。
(3)按照模型的复杂程度分类
按照模型的复杂度,主要分为两类:线性模型和非线性模型。
线性模型:决策边界为直线。例如逻辑回归模型。
非线性模型:决策边界为非直线。例如神经网络模型。
(4)按照模型功能分类
按照模型的功能来分类,主要分为判别模型与生成模型。
判别模型:由数据直接学习决策函数f(x)或条件概率分布P(y|x)进行预测的模型,其关心的是对给定的输入x,应该预测什么样的输出y。常见的k近邻法、感知机、决策树、逻辑回归、线性回归、最大熵模型。
生成模型:由数据学习输入和输出联合概率分布P(x,y),然后求出后验概率分布P(y|x)进行预测的模型。常见的生成模型朴素贝叶斯、隐马尔可夫(em算法)。
03—机器学习的基本流程
对于一个机器学习项目而言,主要的流程有以下概况:
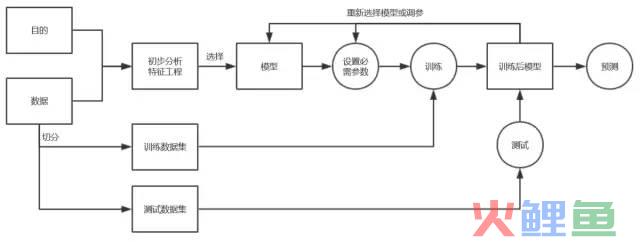
(1)数据预处理
数据清洗是检测和去除数据集中的噪声数据和无关数据,处理遗漏数据,去除空白数据域和知识背景下的白噪声。
(2)数据切分
在机器学习中,通常将所有的数据划分为三份:训练数据集、验证数据集和测试数据集。它们的功能分别为
训练数据集(train dataset):用来构建机器学习模型。
验证数据集(validation dataset):辅助构建模型,用于在构建过程中评估模型,为模型提供无偏估计,进而调整模型超参数。
测试数据集(test dataset):用来评估训练好的最终模型的性能。
关于数据如何进行切分,后续再进行分享。
(3)特征工程
特征构建是指从原始数据中人工的找出一些具有物理意义的特征。需要花时间去观察原始数据,思考问题的潜在形式和数据结构,对数据敏感性和机器学习实战经验能帮助特征构建。
关于机器学习,就先分享这些。欢迎大家继续关注~
-END-