搜索引擎优化应该怎么做?了解一下搜索模型和四类基本算法!
-

-
kana 这家伙很懒,还没有设置简介...
0 人点赞了该文章 · 179 浏览
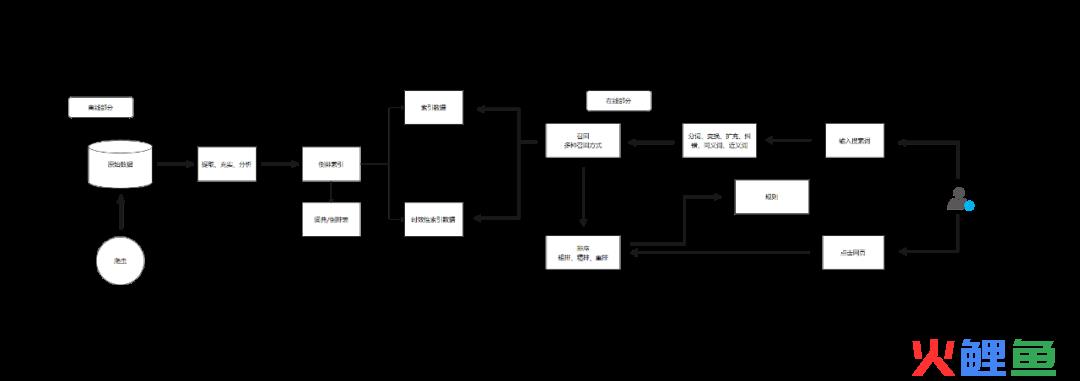
搜索引擎的基本搜索模型
搜索引擎一般是由在线和离线两部分构成,离线部分主要是搜索引擎爬取网页的原始数据再将其提取、充实、分析、索引的过程。
这一块我们需要注意的一点就是在索引数据当中有一条关于时效性索引数据的内容。主要是一些新闻的索引数据,搜索引擎会对一些有时效性的新闻给予快速的收录和较高的排名。
但是在过了时效性以后这些排名就会掉了,连收录都可能会掉出,这个时效性索引数据过了时效后的状态,主要是跟网站的结构和权威性有关。
而我们做搜索优化其实主要要在意的还是其离线部分的内容。

用户在输入了搜索词以后,搜索系统会进行Query理解从而采用不同的召回策略。
就像我在搜索“塑聊”的时候,搜索引擎通过字典判断再给我纠错为“塑料”,在搜索“su料”的时候也会给我纠错为“塑料”。
在搜索“BTC”的时候会给我扩充“比特币”的内容,在搜索“土豆”的时候会给我呈现“马铃薯”的时候,都是出于对同义词的扩充。
在搜索“搜索引擎营销”的时候会将这几个字分词为“搜索/引擎/营销”或者“搜/索/引/擎/营/销/”等更多粒度的分词。
系统在经过了召回环节后并不是直接就呈现在用户面前,而是会将这些通过不同召回策略的索引数据作为候选集合,候选集合的数量大概在几千到几万个。再通过更精细的计算模型对候选集合中的内容进行分值计算,从而获得初步的排序。
在经过了召回环节之后将会进入排序环节,而排序环节会分为粗排、精排和重排三个环节。粗排大致上是通过类似于评价搜索词和文档之间相关性的BM25算法来获取一个粗略的排序,这个数量大概是几百到几千个,在百度搜索引擎当中这个数值最大为760个。
在经过了粗排以后,搜索引擎会加载更多的特征和更复杂的模型,对粗排的内容进行排序计算,从粗排提供的候选池中选出用户最有可能点击的内容,这个数量值大概是在一百以内。
在经过精排以后,这些内容已经可以初步呈现给用户,但是在呈现之前还会有一个规则干预的环节,规则通常服务特定产品目的。例如百度信誉的官网认证服务,企业用户在做了官网认证以后,用户在搜索企业名称,企业内容会出现在搜索排名的第一位,这个就是重排。
此外排序并非是一成不变的,在内容展现给用户以后,用户点击反馈会影响到排序环节模型,用户点击更多的网址,在后续搜索展现当中会获得更高的排名,这个就是点击调权的过程,也是重排的过程。
搜索引擎的四类基本算法

TF-IDF 词频-逆文本率算法
TF=某个词在文章中出现的次数=某个词在文章中出现的次数/文章总词数
IDF=log(语料库文档总数/(包含该词文档数+1))
TF-IDF=词频(TF)*逆文档频率(IFD)
这个算法主要是为了评估字词对于一个文件集中的一份文件的重要程度。
字词的重要性随着它在文件中出现的次数成正比增加。
但同时会随着它在语料库中出现的频率成反比下降。

这句话应该怎么去理解呢?我们举一个简单的例子:
图书馆有一万本书,其中一本书关于“姜母鸭”这词出现的次数是66次,关于“做法”这个词的出现的次数是1000次。那“做法”的TF是高于“姜母鸭”的。但是对比图书馆里的10000本书中,我们会发现“姜母鸭”在其他书中出现的频次很低,而“做法”在其他书中出现的频次也很高。因此会把“做法”的权重降低从而得出关键词“姜母鸭”
TF-IDF算法可以过滤掉一些常见词(如上述的“做法”)而保留重要的词(如上述的“姜母鸭”)从而得出文档当中的重点。这个算法可以说是搜索引擎的基本算法了,换成我们比较通俗的语言去讲,就是关键词密度。
 Hits 链接分析算法
Hits 链接分析算法
在SEO当中,常常有内容为王,外链为皇的说法(现在已经不适用了),因为在SEO的早期,外链算法是对网站排名影响极大的算法。
例如当初李彦宏依靠“超链分析算法”成立了百度,而这个超链分析算法也就是我们现在比较熟知的锚文本链接。
后来谷歌对“超链分析算法”进行了优化,提出了不同网站的权重不同,所以外链传导的权重也应该不同的概念,这个就是后来的“PageRank算法”。
而现在百度和谷歌对这类算法也经历了无数个版本的迭代,而且也有新的链接分析算法出现,例如Hits算法。

Hits算法中有两个新概念,一个是“Authority”页面,一个是“Hub”页面。
“Authority”页面指的是高质量的权威页面。
“Hub”页面指的是指向很多权威页面的枢纽页面。
一个好的权威页面会被很多枢纽页面指向
一个好的枢纽页面会指向很多权威页面。
这种算法可以比较简单通过链接的去判定网站的优劣,但是也比较容易作弊。
比如万物皆可运营的官网导出的外链有腾讯新闻、搜狐新闻、凤凰新闻、悠然布衣。而腾讯新闻、搜狐新闻等三个都是权威页面,那么悠然布衣也会被认为是权威页面。
TextRank算法和LDA主题模型
除了TF-IDF算法以外,像TextRank算法和LDA、LSA这类的主题模型算法也被广泛地应用在关键词提取领域。
TextRank算法比起TF-IDF算法的特点在于它可以脱离语料库的背景,对单篇文档进行分析,提取单篇文档的关键词。但是缺点就是受分词、文本清洗影响大,受高频词影响大。
这个算法是引入了PageRank算法的理念,将文本拆成词汇组成网络模型,将词汇相似度的共现关系作为投票关系或者说推荐关系,从而去计算每个词的重要性。
例如:(例子来源于@知乎 黄鑫)

然后对上面这段话进行分词,去除中间的停用词,我们可以得到:程序员 英文 程序 开发 维护 专业 人员 程序员 分为 程序 设计 人员 程序 编码 人员 界限 特别 中国 软件 人员 分为 程序员 高级程序员 系统 分析员 项目 经理
然后建一个大小为9的窗口,每个单词要投票给它前后距离为5以内的词
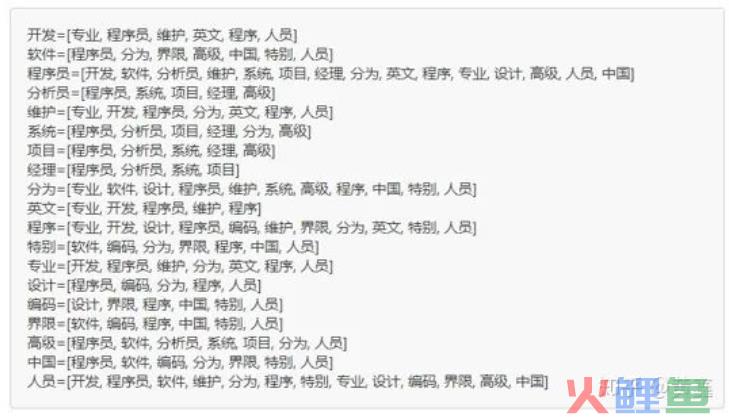
然后开始迭代投票
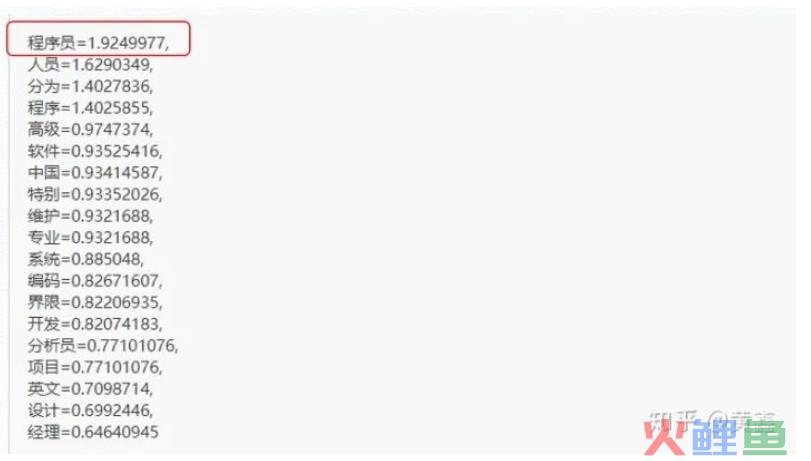
这样得出来“程序员”是这段话当中权重最高的单词。

LDA主题模型:在很多场景下,单纯的提取文档里面的关键词是不够用的,比如中国古代很多的古诗就是这么玩的。
“解落三秋叶,能开二月花。过江千尺浪,入竹万竿斜。”这首李峤的《风》,虽然是描写风的,但是除了题目全诗没有一个”风“字。
还有朱熹的《秋月》:清溪流过碧山头,空水澄鲜一色秋。隔断红尘三十里,白云红叶两悠悠。是描写月亮的但是全诗没有一个月字。
虽然关键词和文档之间没有直接的联系,但是需要通过一个维度将其串联起来,这个就是主题。每个文档都应该对应一个或者多个主题,每个主题都会有对应的词分布。
LDA语义主题模型可以实现相同语义的主题单词之间的相互关联,给信息检索中文本的潜在语义信息的挖掘提供良好的检索模型框架,可以用来识别大规模文档集或语料库中的潜在隐藏的主题信息。

比如一个文章如果涉及到“姜母鸭”这个主题,那么“闽南”、“厦门”、“泉州”等词语就会以较高的频率出现,而如果涉及到“老鼠干”,那么“闽西”、“客家”“宁化”就会出现的很频繁。
搜索引擎会分析用户查询词汇与哪些主题是相关的,这些相关会通过形容词的属性来作为参考。例如“姜母鸭”相关的都是属于美食,那么滋阴降火的功能属性、浓香鲜美的味道属性这些内容都是与它关联的。
现在百度搜索的下拉关联搜索、相关搜索等搜索词,应当就是与TextRank算法、LD算法、DNN算法等相关。

Simhash去重算法
为了计算一篇文档之间的相似度存在的,通过simhash算法可以计算出文档的simhash值,通过各个文档计算出的二进制值来计算文档之间的汉明距离,然后根据汉明距离来比较文档之间的相似度。(汉明距离是指两个相同长度的字符串相同位置上不同的字符的个数。)
例子:“我元宵节在家里用烤炉做了一只美味的烤鸡”和“我正月十五在家里用烤箱做了一盘超级好吃的烤鸡。”
首先去除停用词后变成了
“我 元宵 家里 烤炉 美味 烤鸡”和“我 正月十五 家里 烤箱 超级好吃 烤鸡”
做词频统计,再做同义词归一化 元宵=正月十五 烤炉=烤箱 美味=超级好吃
最后判断这两句话是同一个意思。
早期百度应该是对网页结构化数据进行simhash识别,而最新的原创识别应该是对句子级别的做simhash识别了。所以当前来说,简单的语句调换、关键词替换等方法做伪原创,其实对搜索引擎的影响不大,他们能够识别出来。

TF-IDF算法、TextRank算法和LDA主题模型这几种算法,除了搜索引擎营销的人员以外,做新媒体运营的同学也可以做相关了解。除了在百度以外,例如抖音、小红书、微信等平台搜索算法也与此相关。
今天就简单的聊一聊搜索引擎的几类基本算法,了解这些算法,对于指导搜索优化和内容分发都有比较大的作用,但是毕竟我不是技术出身的,对这个理解的也不是特别透彻,所以大家感兴趣的可以自己再找资料学习学习。
下一篇内容,会比较详细地去盘点一下SEO当中比较常用的一些作弊手段,也就是黑帽SEO。嗯,有缘再更新吧~